 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVolta: Efficient Multi-modal Models via Stage-wise Visual Context Compression
Jun 28, 2024


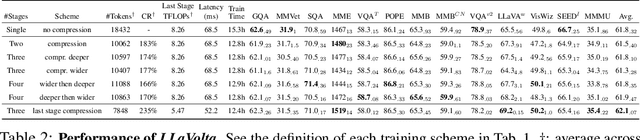
While significant advancements have been made in compressed representations for text embeddings in large language models (LLMs), the compression of visual tokens in large multi-modal models (LMMs) has remained a largely overlooked area. In this work, we present the study on the analysis of redundancy concerning visual tokens and efficient training within these models. Our initial experiments show that eliminating up to 70% of visual tokens at the testing stage by simply average pooling only leads to a minimal 3% reduction in visual question answering accuracy on the GQA benchmark, indicating significant redundancy in visual context. Addressing this, we introduce Visual Context Compressor, which reduces the number of visual tokens during training to enhance training efficiency without sacrificing performance. To minimize information loss caused by the compression on visual tokens while maintaining training efficiency, we develop LLaVolta as a lite training scheme. LLaVolta incorporates stage-wise visual context compression to progressively compress the visual tokens from heavily to lightly, and finally no compression at the end of training, yielding no loss of information when testing. Extensive experiments demonstrate that our approach enhances the performance of MLLMs in both image-language and video-language understanding, while also significantly cutting training costs. Code is available at https://github.com/Beckschen/LLaVolta
Instantiation-Net: 3D Mesh Reconstruction from Single 2D Image for Right Ventricle
Sep 16, 2019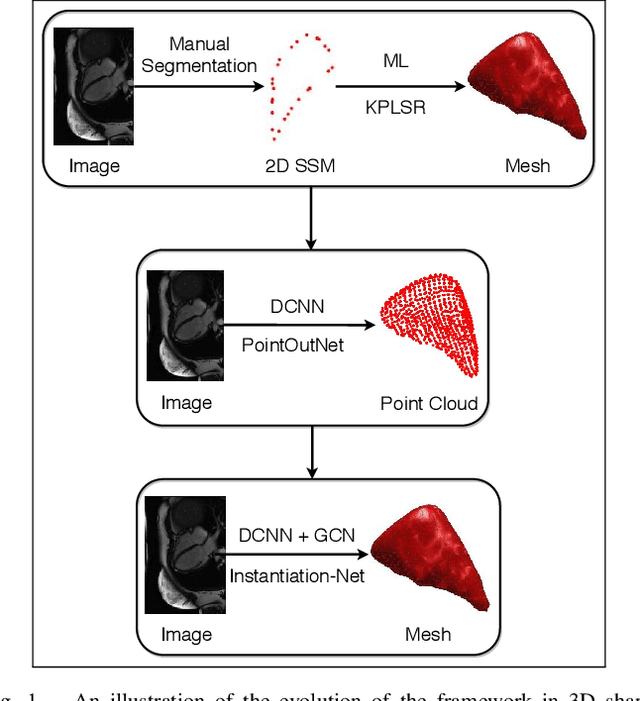



3D shape instantiation which reconstructs the 3D shape of a target from limited 2D images or projections is an emerging technique for surgical intervention. It improves the currently less-informative and insufficient 2D navigation schemes for robot-assisted Minimally Invasive Surgery (MIS) to 3D navigation. Previously, a general and registration-free framework was proposed for 3D shape instantiation based on Kernel Partial Least Square Regression (KPLSR), requiring manually segmented anatomical structures as the pre-requisite. Two hyper-parameters including the Gaussian width and component number also need to be carefully adjusted. Deep Convolutional Neural Network (DCNN) based framework has also been proposed to reconstruct a 3D point cloud from a single 2D image, with end-to-end and fully automatic learning. In this paper, an Instantiation-Net is proposed to reconstruct the 3D mesh of a target from its a single 2D image, by using DCNN to extract features from the 2D image and Graph Convolutional Network (GCN) to reconstruct the 3D mesh, and using Fully Connected (FC) layers to connect the DCNN to GCN. Detailed validation was performed to demonstrate the practical strength of the method and its potential clinical use.
Z-Net: an Asymmetric 3D DCNN for Medical CT Volume Segmentation
Sep 16, 2019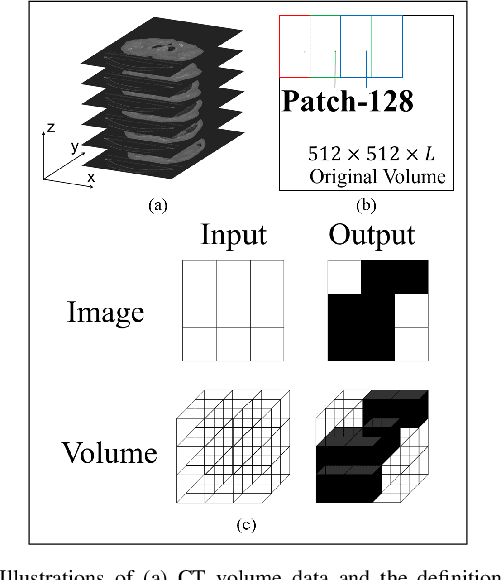
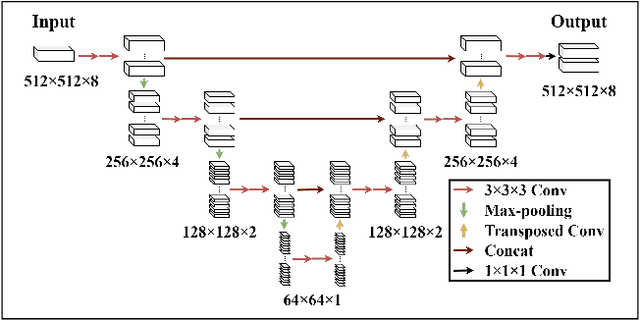
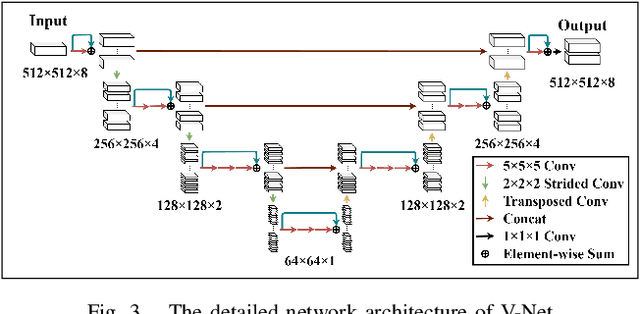
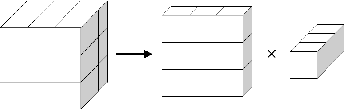
Accurate volume segmentation from the Computed Tomography (CT) scan is a common prerequisite for pre-operative planning, intra-operative guidance and quantitative assessment of therapeutic outcomes in robot-assisted Minimally Invasive Surgery (MIS). The use of 3D Deep Convolutional Neural Network (DCNN) is a viable solution for this task but is memory intensive. The use of patch division can mitigate this issue in practice, but can cause discontinuities between the adjacent patches and severe class-imbalances within individual sub-volumes. This paper presents a new patch division approach - Patch-512 to tackle the class-imbalance issue by preserving a full field-of-view of the objects in the XY planes. To achieve better segmentation results based on these asymmetric patches, a 3D DCNN architecture using asymmetrical separable convolutions is proposed. The proposed network, called Z-Net, can be seamlessly integrated into existing 3D DCNNs such as 3D U-Net and V-Net, for improved volume segmentation. Detailed validation of the method is provided for CT aortic, liver and lung segmentation, demonstrating the effectiveness and practical value of the method for intra-operative 3D navigation in robot-assisted MIS.
U-Net Training with Instance-Layer Normalization
Aug 25, 2019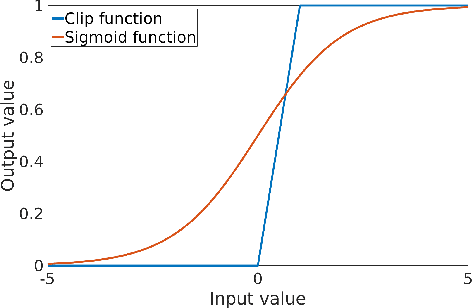


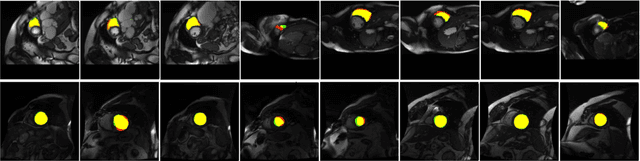
Normalization layers are essential in a Deep Convolutional Neural Network (DCNN). Various normalization methods have been proposed. The statistics used to normalize the feature maps can be computed at batch, channel, or instance level. However, in most of existing methods, the normalization for each layer is fixed. Batch-Instance Normalization (BIN) is one of the first proposed methods that combines two different normalization methods and achieve diverse normalization for different layers. However, two potential issues exist in BIN: first, the Clip function is not differentiable at input values of 0 and 1; second, the combined feature map is not with a normalized distribution which is harmful for signal propagation in DCNN. In this paper, an Instance-Layer Normalization (ILN) layer is proposed by using the Sigmoid function for the feature map combination, and cascading group normalization. The performance of ILN is validated on image segmentation of the Right Ventricle (RV) and Left Ventricle (LV) using U-Net as the network architecture. The results show that the proposed ILN outperforms previous traditional and popular normalization methods with noticeable accuracy improvements for most validations, supporting the effectiveness of the proposed ILN.
One-stage Shape Instantiation from a Single 2D Image to 3D Point Cloud
Jul 24, 2019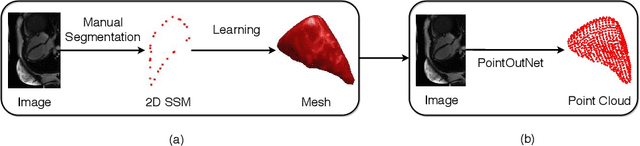
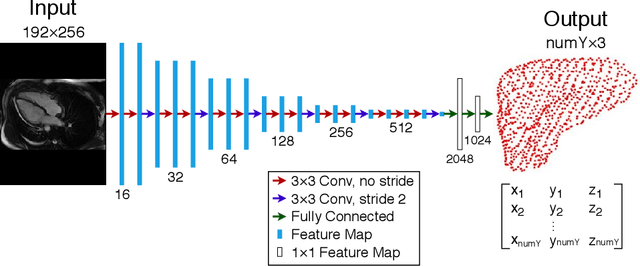
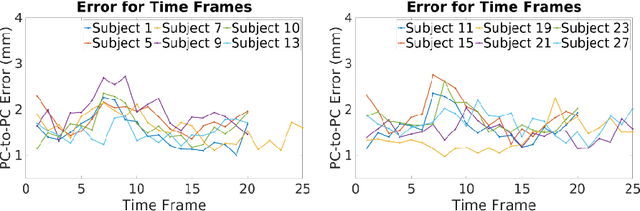
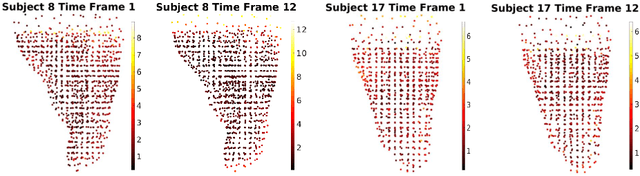
Shape instantiation which predicts the 3D shape of a dynamic target from one or more 2D images is important for real-time intra-operative navigation. Previously, a general shape instantiation framework was proposed with manual image segmentation to generate a 2D Statistical Shape Model (SSM) and with Kernel Partial Least Square Regression (KPLSR) to learn the relationship between the 2D and 3D SSM for 3D shape prediction. In this paper, the two-stage shape instantiation is improved to be one-stage. PointOutNet with 19 convolutional layers and three fully-connected layers is used as the network structure and Chamfer distance is used as the loss function to predict the 3D target point cloud from a single 2D image. With the proposed one-stage shape instantiation algorithm, a spontaneous image-to-point cloud training and inference can be achieved. A dataset from 27 Right Ventricle (RV) subjects, indicating 609 experiments, were used to validate the proposed one-stage shape instantiation algorithm. An average point cloud-to-point cloud (PC-to-PC) error of 1.72mm has been achieved, which is comparable to the PLSR-based (1.42mm) and KPLSR-based (1.31mm) two-stage shape instantiation algorithm.