 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency Enhancement for Image Demosaicking
Mar 20, 2025Recovering high-frequency textures in image demosaicking remains a challenging issue. While existing methods introduced elaborate spatial learning methods, they still exhibit limited performance. To address this issue, a frequency enhancement approach is proposed. Based on the frequency analysis of color filter array (CFA)/demosaicked/ground truth images, we propose Dual-path Frequency Enhancement Network (DFENet), which reconstructs RGB images in a divide-and-conquer manner through fourier-domain frequency selection. In DFENet, two frequency selectors are employed, each selecting a set of frequency components for processing along separate paths. One path focuses on generating missing information through detail refinement in spatial domain, while the other aims at suppressing undesirable frequencies with the guidance of CFA images in frequency domain. Multi-level frequency supervision with a stagewise training strategy is employed to further improve the reconstruction performance. With these designs, the proposed DFENet outperforms other state-of-the-art algorithms on different datasets and demonstrates significant advantages on hard cases. Moreover, to better assess algorithms' ability to reconstruct high-frequency textures, a new dataset, LineSet37, is contributed, which consists of 37 artificially designed and generated images. These images feature complex line patterns and are prone to severe visual artifacts like color moir\'e after demosaicking. Experiments on LineSet37 offer a more targeted evaluation of performance on challenging cases. The code and dataset are available at https://github.com/VelvetReverie/DFENet-demosaicking.
Space-Time Video Super-resolution with Neural Operator
Apr 09, 2024



This paper addresses the task of space-time video super-resolution (ST-VSR). Existing methods generally suffer from inaccurate motion estimation and motion compensation (MEMC) problems for large motions. Inspired by recent progress in physics-informed neural networks, we model the challenges of MEMC in ST-VSR as a mapping between two continuous function spaces. Specifically, our approach transforms independent low-resolution representations in the coarse-grained continuous function space into refined representations with enriched spatiotemporal details in the fine-grained continuous function space. To achieve efficient and accurate MEMC, we design a Galerkin-type attention function to perform frame alignment and temporal interpolation. Due to the linear complexity of the Galerkin-type attention mechanism, our model avoids patch partitioning and offers global receptive fields, enabling precise estimation of large motions. The experimental results show that the proposed method surpasses state-of-the-art techniques in both fixed-size and continuous space-time video super-resolution tasks.
Learning a Single Convolutional Layer Model for Low Light Image Enhancement
May 23, 2023



Low-light image enhancement (LLIE) aims to improve the illuminance of images due to insufficient light exposure. Recently, various lightweight learning-based LLIE methods have been proposed to handle the challenges of unfavorable prevailing low contrast, low brightness, etc. In this paper, we have streamlined the architecture of the network to the utmost degree. By utilizing the effective structural re-parameterization technique, a single convolutional layer model (SCLM) is proposed that provides global low-light enhancement as the coarsely enhanced results. In addition, we introduce a local adaptation module that learns a set of shared parameters to accomplish local illumination correction to address the issue of varied exposure levels in different image regions. Experimental results demonstrate that the proposed method performs favorably against the state-of-the-art LLIE methods in both objective metrics and subjective visual effects. Additionally, our method has fewer parameters and lower inference complexity compared to other learning-based schemes.
Continuous Space-Time Video Super-Resolution Utilizing Long-Range Temporal Information
Feb 26, 2023In this paper, we consider the task of space-time video super-resolution (ST-VSR), namely, expanding a given source video to a higher frame rate and resolution simultaneously. However, most existing schemes either consider a fixed intermediate time and scale in the training stage or only accept a preset number of input frames (e.g., two adjacent frames) that fails to exploit long-range temporal information. To address these problems, we propose a continuous ST-VSR (C-STVSR) method that can convert the given video to any frame rate and spatial resolution. To achieve time-arbitrary interpolation, we propose a forward warping guided frame synthesis module and an optical-flow-guided context consistency loss to better approximate extreme motion and preserve similar structures among input and prediction frames. In addition, we design a memory-friendly cascading depth-to-space module to realize continuous spatial upsampling. Meanwhile, with the sophisticated reorganization of optical flow, the proposed method is memory friendly, making it possible to propagate information from long-range neighboring frames and achieve better reconstruction quality. Extensive experiments show that the proposed algorithm has good flexibility and achieves better performance on various datasets compared with the state-of-the-art methods in both objective evaluations and subjective visual effects.
A GPS Pseudorange Based Cooperative Vehicular Distance Measurement Technique
Jul 11, 2012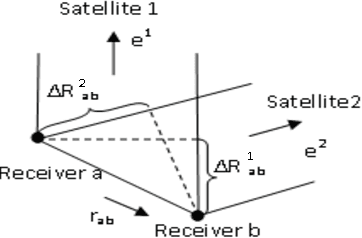

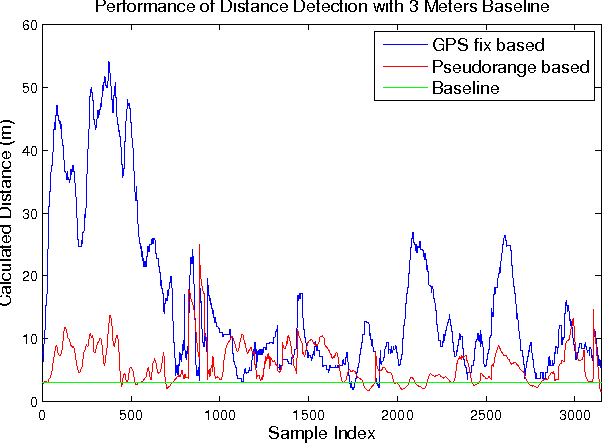

Accurate vehicular localization is important for various cooperative vehicle safety (CVS) applications such as collision avoidance, turning assistant, etc. In this paper, we propose a cooperative vehicular distance measurement technique based on the sharing of GPS pseudorange measurements and a weighted least squares method. The classic double difference pseudorange solution, which was originally designed for high-end survey level GPS systems, is adapted to low-end navigation level GPS receivers for its wide availability in ground vehicles. The Carrier to Noise Ratio (CNR) of raw pseudorange measurements are taken into account for noise mitigation. We present a Dedicated Short Range Communications (DSRC) based mechanism to implement the exchange of pseudorange information among neighboring vehicles. As demonstrated in field tests, our proposed technique increases the accuracy of the distance measurement significantly compared with the distance obtained from the GPS fixes.