 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Reference Frame Synthesis and Post Filter Enhancement for Versatile Video Coding
Apr 28, 2024This paper presents the joint reference frame synthesis (RFS) and post-processing filter enhancement (PFE) for Versatile Video Coding (VVC), aiming to explore the combination of different neural network-based video coding (NNVC) tools to better utilize the hierarchical bi-directional coding structure of VVC. Both RFS and PFE utilize the Space-Time Enhancement Network (STENet), which receives two input frames with artifacts and produces two enhanced frames with suppressed artifacts, along with an intermediate synthesized frame. STENet comprises two pipelines, the synthesis pipeline and the enhancement pipeline, tailored for different purposes. During RFS, two reconstructed frames are sent into STENet's synthesis pipeline to synthesize a virtual reference frame, similar to the current to-be-coded frame. The synthesized frame serves as an additional reference frame inserted into the reference picture list (RPL). During PFE, two reconstructed frames are fed into STENet's enhancement pipeline to alleviate their artifacts and distortions, resulting in enhanced frames with reduced artifacts and distortions. To reduce inference complexity, we propose joint inference of RFS and PFE (JISE), achieved through a single execution of STENet. Integrated into the VVC reference software VTM-15.0, RFS, PFE, and JISE are coordinated within a novel Space-Time Enhancement Window (STEW) under Random Access (RA) configuration. The proposed method could achieve -7.34%/-17.21%/-16.65% PSNR-based BD-rate on average for three components under RA configuration.
Space-Time Video Super-resolution with Neural Operator
Apr 09, 2024



This paper addresses the task of space-time video super-resolution (ST-VSR). Existing methods generally suffer from inaccurate motion estimation and motion compensation (MEMC) problems for large motions. Inspired by recent progress in physics-informed neural networks, we model the challenges of MEMC in ST-VSR as a mapping between two continuous function spaces. Specifically, our approach transforms independent low-resolution representations in the coarse-grained continuous function space into refined representations with enriched spatiotemporal details in the fine-grained continuous function space. To achieve efficient and accurate MEMC, we design a Galerkin-type attention function to perform frame alignment and temporal interpolation. Due to the linear complexity of the Galerkin-type attention mechanism, our model avoids patch partitioning and offers global receptive fields, enabling precise estimation of large motions. The experimental results show that the proposed method surpasses state-of-the-art techniques in both fixed-size and continuous space-time video super-resolution tasks.
Learning a Single Convolutional Layer Model for Low Light Image Enhancement
May 23, 2023



Low-light image enhancement (LLIE) aims to improve the illuminance of images due to insufficient light exposure. Recently, various lightweight learning-based LLIE methods have been proposed to handle the challenges of unfavorable prevailing low contrast, low brightness, etc. In this paper, we have streamlined the architecture of the network to the utmost degree. By utilizing the effective structural re-parameterization technique, a single convolutional layer model (SCLM) is proposed that provides global low-light enhancement as the coarsely enhanced results. In addition, we introduce a local adaptation module that learns a set of shared parameters to accomplish local illumination correction to address the issue of varied exposure levels in different image regions. Experimental results demonstrate that the proposed method performs favorably against the state-of-the-art LLIE methods in both objective metrics and subjective visual effects. Additionally, our method has fewer parameters and lower inference complexity compared to other learning-based schemes.
Continuous Space-Time Video Super-Resolution Utilizing Long-Range Temporal Information
Feb 26, 2023In this paper, we consider the task of space-time video super-resolution (ST-VSR), namely, expanding a given source video to a higher frame rate and resolution simultaneously. However, most existing schemes either consider a fixed intermediate time and scale in the training stage or only accept a preset number of input frames (e.g., two adjacent frames) that fails to exploit long-range temporal information. To address these problems, we propose a continuous ST-VSR (C-STVSR) method that can convert the given video to any frame rate and spatial resolution. To achieve time-arbitrary interpolation, we propose a forward warping guided frame synthesis module and an optical-flow-guided context consistency loss to better approximate extreme motion and preserve similar structures among input and prediction frames. In addition, we design a memory-friendly cascading depth-to-space module to realize continuous spatial upsampling. Meanwhile, with the sophisticated reorganization of optical flow, the proposed method is memory friendly, making it possible to propagate information from long-range neighboring frames and achieve better reconstruction quality. Extensive experiments show that the proposed algorithm has good flexibility and achieves better performance on various datasets compared with the state-of-the-art methods in both objective evaluations and subjective visual effects.
Optical-Flow-Reuse-Based Bidirectional Recurrent Network for Space-Time Video Super-Resolution
Oct 13, 2021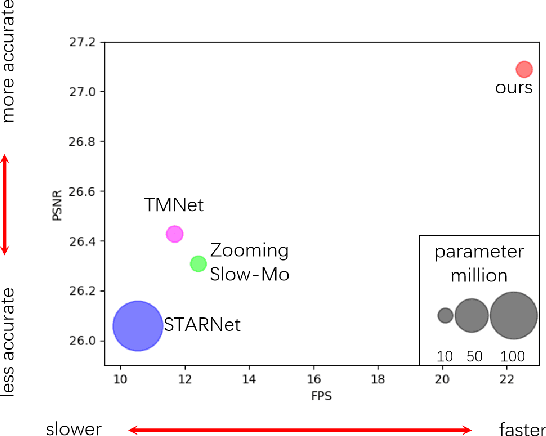
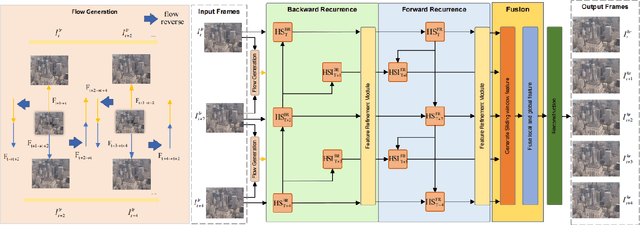
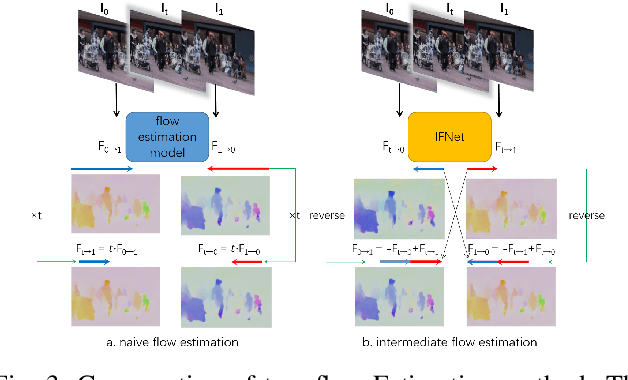

In this paper, we consider the task of space-time video super-resolution (ST-VSR), which simultaneously increases the spatial resolution and frame rate for a given video. However, existing methods typically suffer from difficulties in how to efficiently leverage information from a large range of neighboring frames or avoiding the speed degradation in the inference using deformable ConvLSTM strategies for alignment. % Some recent LSTM-based ST-VSR methods have achieved promising results. To solve the above problem of the existing methods, we propose a coarse-to-fine bidirectional recurrent neural network instead of using ConvLSTM to leverage knowledge between adjacent frames. Specifically, we first use bi-directional optical flow to update the hidden state and then employ a Feature Refinement Module (FRM) to refine the result. Since we could fully utilize a large range of neighboring frames, our method leverages local and global information more effectively. In addition, we propose an optical flow-reuse strategy that can reuse the intermediate flow of adjacent frames, which considerably reduces the computation burden of frame alignment compared with existing LSTM-based designs. Extensive experiments demonstrate that our optical-flow-reuse-based bidirectional recurrent network(OFR-BRN) is superior to the state-of-the-art methods both in terms of accuracy and efficiency.