 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDCO: Dynamic Curriculum Orchestration for Domain-specific Large Language Model Fine-tuning
Jan 07, 2026Domain-specific large language models (LLMs), typically developed by fine-tuning a pre-trained general-purpose LLM on specialized datasets, represent a significant advancement in applied AI. A common strategy in LLM fine-tuning is curriculum learning, which pre-orders training samples based on metrics like difficulty to improve learning efficiency compared to a random sampling strategy. However, most existing methods for LLM fine-tuning rely on a static curriculum, designed prior to training, which lacks adaptability to the model's evolving needs during fine-tuning. To address this, we propose EDCO, a novel framework based on two key concepts: inference entropy and dynamic curriculum orchestration. Inspired by recent findings that maintaining high answer entropy benefits long-term reasoning gains, EDCO prioritizes samples with high inference entropy in a continuously adapted curriculum. EDCO integrates three core components: an efficient entropy estimator that uses prefix tokens to approximate full-sequence entropy, an entropy-based curriculum generator that selects data points with the highest inference entropy, and an LLM trainer that optimizes the model on the selected curriculum. Comprehensive experiments in communication, medicine and law domains, EDCO outperforms traditional curriculum strategies for fine-tuning Qwen3-4B and Llama3.2-3B models under supervised and reinforcement learning settings. Furthermore, the proposed efficient entropy estimation reduces computational time by 83.5% while maintaining high accuracy.
Space-Time Video Super-resolution with Neural Operator
Apr 09, 2024



This paper addresses the task of space-time video super-resolution (ST-VSR). Existing methods generally suffer from inaccurate motion estimation and motion compensation (MEMC) problems for large motions. Inspired by recent progress in physics-informed neural networks, we model the challenges of MEMC in ST-VSR as a mapping between two continuous function spaces. Specifically, our approach transforms independent low-resolution representations in the coarse-grained continuous function space into refined representations with enriched spatiotemporal details in the fine-grained continuous function space. To achieve efficient and accurate MEMC, we design a Galerkin-type attention function to perform frame alignment and temporal interpolation. Due to the linear complexity of the Galerkin-type attention mechanism, our model avoids patch partitioning and offers global receptive fields, enabling precise estimation of large motions. The experimental results show that the proposed method surpasses state-of-the-art techniques in both fixed-size and continuous space-time video super-resolution tasks.
Wavelet-Like Transform-Based Technology in Response to the Call for Proposals on Neural Network-Based Image Coding
Mar 09, 2024



Neural network-based image coding has been developing rapidly since its birth. Until 2022, its performance has surpassed that of the best-performing traditional image coding framework -- H.266/VVC. Witnessing such success, the IEEE 1857.11 working subgroup initializes a neural network-based image coding standard project and issues a corresponding call for proposals (CfP). In response to the CfP, this paper introduces a novel wavelet-like transform-based end-to-end image coding framework -- iWaveV3. iWaveV3 incorporates many new features such as affine wavelet-like transform, perceptual-friendly quality metric, and more advanced training and online optimization strategies into our previous wavelet-like transform-based framework iWave++. While preserving the features of supporting lossy and lossless compression simultaneously, iWaveV3 also achieves state-of-the-art compression efficiency for objective quality and is very competitive for perceptual quality. As a result, iWaveV3 is adopted as a candidate scheme for developing the IEEE Standard for neural-network-based image coding.
Learning a Single Convolutional Layer Model for Low Light Image Enhancement
May 23, 2023



Low-light image enhancement (LLIE) aims to improve the illuminance of images due to insufficient light exposure. Recently, various lightweight learning-based LLIE methods have been proposed to handle the challenges of unfavorable prevailing low contrast, low brightness, etc. In this paper, we have streamlined the architecture of the network to the utmost degree. By utilizing the effective structural re-parameterization technique, a single convolutional layer model (SCLM) is proposed that provides global low-light enhancement as the coarsely enhanced results. In addition, we introduce a local adaptation module that learns a set of shared parameters to accomplish local illumination correction to address the issue of varied exposure levels in different image regions. Experimental results demonstrate that the proposed method performs favorably against the state-of-the-art LLIE methods in both objective metrics and subjective visual effects. Additionally, our method has fewer parameters and lower inference complexity compared to other learning-based schemes.
aiWave: Volumetric Image Compression with 3-D Trained Affine Wavelet-like Transform
Mar 11, 2022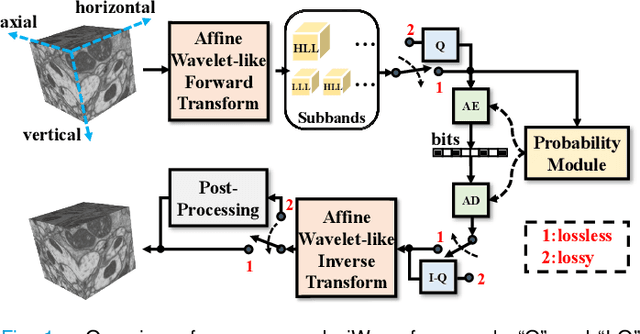
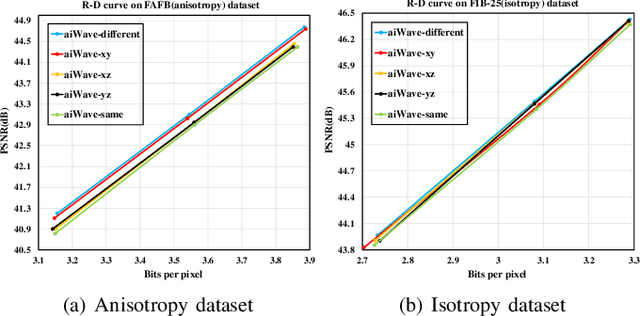
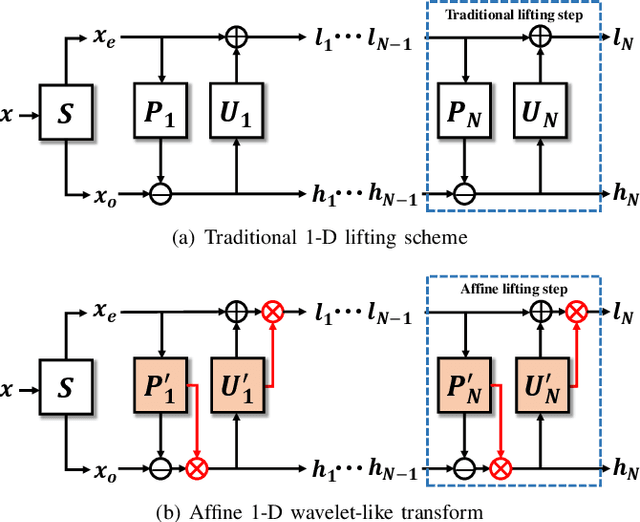
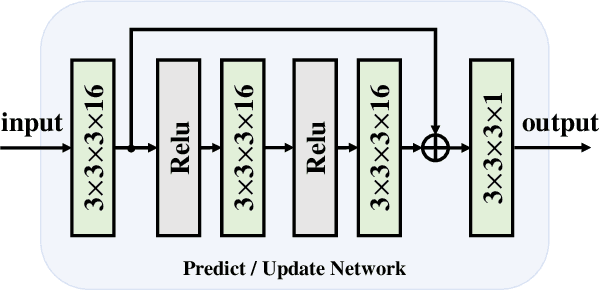
Volumetric image compression has become an urgent task to effectively transmit and store images produced in biological research and clinical practice. At present, the most commonly used volumetric image compression methods are based on wavelet transform, such as JP3D. However, JP3D employs an ideal, separable, global, and fixed wavelet basis to convert input images from pixel domain to frequency domain, which seriously limits its performance. In this paper, we first design a 3-D trained wavelet-like transform to enable signal-dependent and non-separable transform. Then, an affine wavelet basis is introduced to capture the various local correlations in different regions of volumetric images. Furthermore, we embed the proposed wavelet-like transform to an end-to-end compression framework called aiWave to enable an adaptive compression scheme for various datasets. Last but not least, we introduce the weight sharing strategies of the affine wavelet-like transform according to the volumetric data characteristics in the axial direction to reduce the amount of parameters. The experimental results show that: 1) when cooperating our trained 3-D affine wavelet-like transform with a simple factorized entropy module, aiWave performs better than JP3D and is comparable in terms of encoding and decoding complexities; 2) when adding a context module to further remove signal redundancy, aiWave can achieve a much better performance than HEVC.
iWave3D: End-to-end Brain Image Compression with Trainable 3-D Wavelet Transform
Oct 10, 2021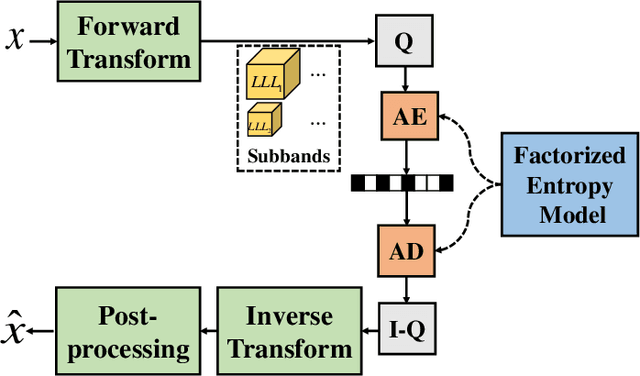
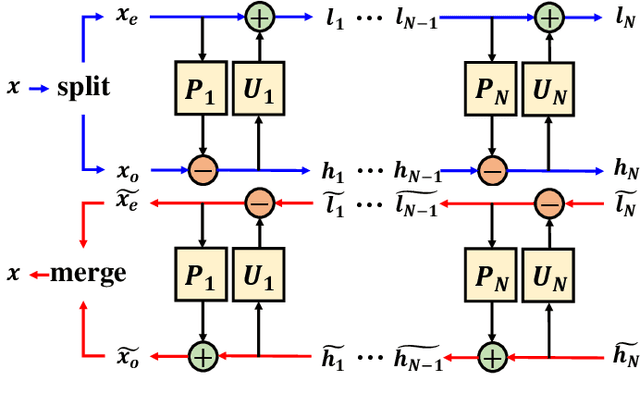
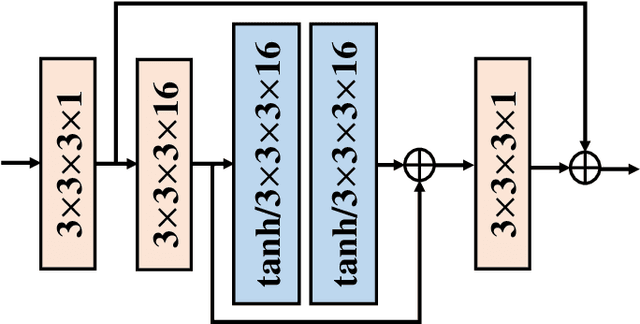
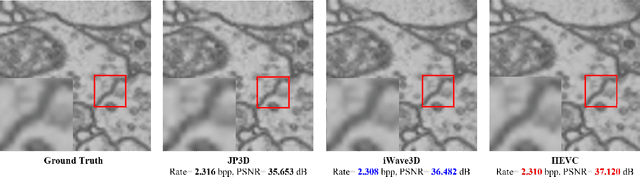
With the rapid development of whole brain imaging technology, a large number of brain images have been produced, which puts forward a great demand for efficient brain image compression methods. At present, the most commonly used compression methods are all based on 3-D wavelet transform, such as JP3D. However, traditional 3-D wavelet transforms are designed manually with certain assumptions on the signal, but brain images are not as ideal as assumed. What's more, they are not directly optimized for compression task. In order to solve these problems, we propose a trainable 3-D wavelet transform based on the lifting scheme, in which the predict and update steps are replaced by 3-D convolutional neural networks. Then the proposed transform is embedded into an end-to-end compression scheme called iWave3D, which is trained with a large amount of brain images to directly minimize the rate-distortion loss. Experimental results demonstrate that our method outperforms JP3D significantly by 2.012 dB in terms of average BD-PSNR.
End-to-End Image Compression with Probabilistic Decoding
Sep 30, 2021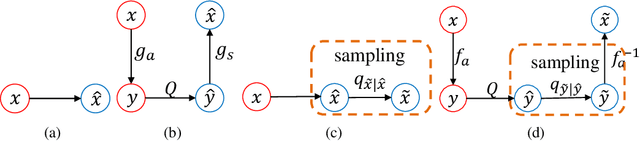

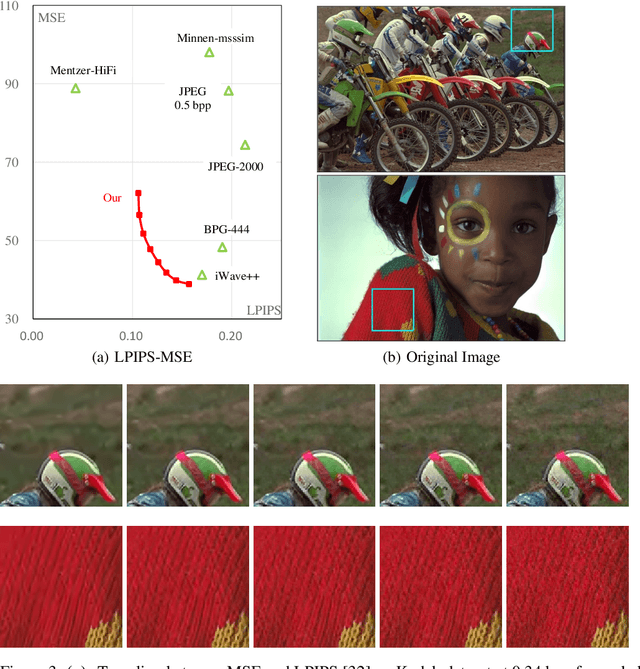
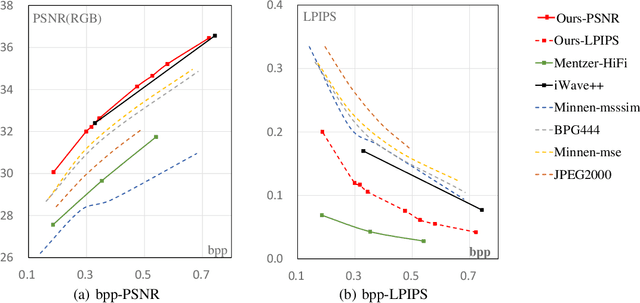
Lossy image compression is a many-to-one process, thus one bitstream corresponds to multiple possible original images, especially at low bit rates. However, this nature was seldom considered in previous studies on image compression, which usually chose one possible image as reconstruction, e.g. the one with the maximal a posteriori probability. We propose a learned image compression framework to natively support probabilistic decoding. The compressed bitstream is decoded into a series of parameters that instantiate a pre-chosen distribution; then the distribution is used by the decoder to sample and reconstruct images. The decoder may adopt different sampling strategies and produce diverse reconstructions, among which some have higher signal fidelity and some others have better visual quality. The proposed framework is dependent on a revertible neural network-based transform to convert pixels into coefficients that obey the pre-chosen distribution as much as possible. Our code and models will be made publicly available.