 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Kernel-Based Adaptive Spatial Aggregation for Learned Image Compression
Aug 17, 2023



Learned image compression methods have shown superior rate-distortion performance and remarkable potential compared to traditional compression methods. Most existing learned approaches use stacked convolution or window-based self-attention for transform coding, which aggregate spatial information in a fixed range. In this paper, we focus on extending spatial aggregation capability and propose a dynamic kernel-based transform coding. The proposed adaptive aggregation generates kernel offsets to capture valid information in the content-conditioned range to help transform. With the adaptive aggregation strategy and the sharing weights mechanism, our method can achieve promising transform capability with acceptable model complexity. Besides, according to the recent progress of entropy model, we define a generalized coarse-to-fine entropy model, considering the coarse global context, the channel-wise, and the spatial context. Based on it, we introduce dynamic kernel in hyper-prior to generate more expressive global context. Furthermore, we propose an asymmetric spatial-channel entropy model according to the investigation of the spatial characteristics of the grouped latents. The asymmetric entropy model aims to reduce statistical redundancy while maintaining coding efficiency. Experimental results demonstrate that our method achieves superior rate-distortion performance on three benchmarks compared to the state-of-the-art learning-based methods.
Exploring Long & Short Range Temporal Information for Learned Video Compression
Aug 07, 2022



Learned video compression methods have gained a variety of interest in the video coding community since they have matched or even exceeded the rate-distortion (RD) performance of traditional video codecs. However, many current learning-based methods are dedicated to utilizing short-range temporal information, thus limiting their performance. In this paper, we focus on exploiting the unique characteristics of video content and further exploring temporal information to enhance compression performance. Specifically, for long-range temporal information exploitation, we propose temporal prior that can update continuously within the group of pictures (GOP) during inference. In that case temporal prior contains valuable temporal information of all decoded images within the current GOP. As for short-range temporal information, we propose a progressive guided motion compensation to achieve robust and effective compensation. In detail, we design a hierarchical structure to achieve multi-scale compensation. More importantly, we use optical flow guidance to generate pixel offsets between feature maps at each scale, and the compensation results at each scale will be used to guide the following scale's compensation. Sufficient experimental results demonstrate that our method can obtain better RD performance than state-of-the-art video compression approaches. The code is publicly available on: https://github.com/Huairui/LSTVC.
Learned Video Compression via Heterogeneous Deformable Compensation Network
Jul 11, 2022


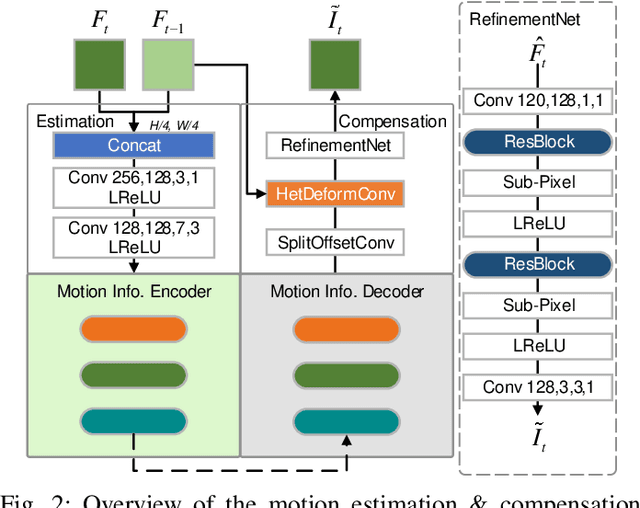
Learned video compression has recently emerged as an essential research topic in developing advanced video compression technologies, where motion compensation is considered one of the most challenging issues. In this paper, we propose a learned video compression framework via heterogeneous deformable compensation strategy (HDCVC) to tackle the problems of unstable compression performance caused by single-size deformable kernels in downsampled feature domain. More specifically, instead of utilizing optical flow warping or single-size-kernel deformable alignment, the proposed algorithm extracts features from the two adjacent frames to estimate content-adaptive heterogeneous deformable (HetDeform) kernel offsets. Then we transform the reference features with the HetDeform convolution to accomplish motion compensation. Moreover, we design a Spatial-Neighborhood-Conditioned Divisive Normalization (SNCDN) to achieve more effective data Gaussianization combined with the Generalized Divisive Normalization. Furthermore, we propose a multi-frame enhanced reconstruction module for exploiting context and temporal information for final quality enhancement. Experimental results indicate that HDCVC achieves superior performance than the recent state-of-the-art learned video compression approaches.
Optical-Flow-Reuse-Based Bidirectional Recurrent Network for Space-Time Video Super-Resolution
Oct 13, 2021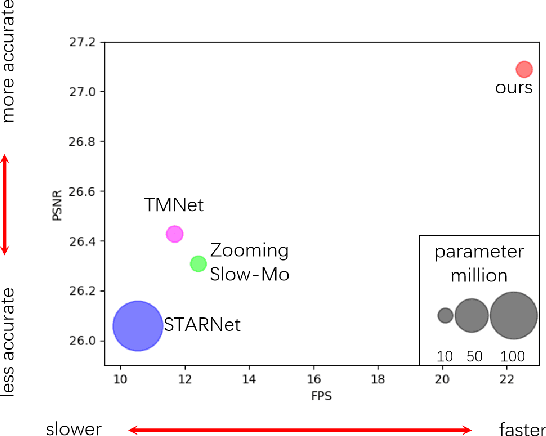
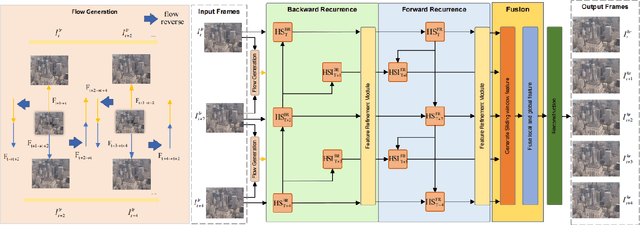
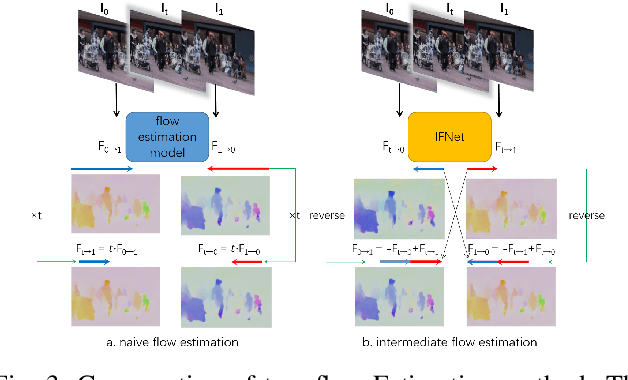

In this paper, we consider the task of space-time video super-resolution (ST-VSR), which simultaneously increases the spatial resolution and frame rate for a given video. However, existing methods typically suffer from difficulties in how to efficiently leverage information from a large range of neighboring frames or avoiding the speed degradation in the inference using deformable ConvLSTM strategies for alignment. % Some recent LSTM-based ST-VSR methods have achieved promising results. To solve the above problem of the existing methods, we propose a coarse-to-fine bidirectional recurrent neural network instead of using ConvLSTM to leverage knowledge between adjacent frames. Specifically, we first use bi-directional optical flow to update the hidden state and then employ a Feature Refinement Module (FRM) to refine the result. Since we could fully utilize a large range of neighboring frames, our method leverages local and global information more effectively. In addition, we propose an optical flow-reuse strategy that can reuse the intermediate flow of adjacent frames, which considerably reduces the computation burden of frame alignment compared with existing LSTM-based designs. Extensive experiments demonstrate that our optical-flow-reuse-based bidirectional recurrent network(OFR-BRN) is superior to the state-of-the-art methods both in terms of accuracy and efficiency.