 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodex
Papers and Code
Why Are AI Agent Involved Pull Requests (Fix-Related) Remain Unmerged? An Empirical Study
Jan 29, 2026Autonomous coding agents (e.g., OpenAI Codex, Devin, GitHub Copilot) are increasingly used to generate fix-related pull requests (PRs) in real world software repositories. However, their practical effectiveness depends on whether these contributions are accepted and merged by project maintainers. In this paper, we present an empirical study of AI agent involved fix related PRs, examining both their integration outcomes, latency, and the factors that hinder successful merging. We first analyze 8,106 fix related PRs authored by five widely used AI coding agents from the AIDEV POP dataset to quantify the proportions of PRs that are merged, closed without merging, or remain open. We then conduct a manual qualitative analysis of a statistically significant sample of 326 closed but unmerged PRs, spending approximately 100 person hours to construct a structured catalog of 12 failure reasons. Our results indicate that test case failures and prior resolution of the same issues by other PRs are the most common causes of non integration, whereas build or deployment failures are comparatively rare. Overall, our findings expose key limitations of current AI coding agents in real world settings and highlight directions for their further improvement and for more effective human AI collaboration in software maintenance.
On the Impact of AGENTS.md Files on the Efficiency of AI Coding Agents
Jan 28, 2026AI coding agents such as Codex and Claude Code are increasingly used to autonomously contribute to software repositories. However, little is known about how repository-level configuration artifacts affect operational efficiency of the agents. In this paper, we study the impact of AGENTS$.$md files on the runtime and token consumption of AI coding agents operating on GitHub pull requests. We analyze 10 repositories and 124 pull requests, executing agents under two conditions: with and without an AGENTS$.$md file. We measure wall-clock execution time and token usage during agent execution. Our results show that the presence of AGENTS$.$md is associated with a lower median runtime ($Δ28.64$%) and reduced output token consumption ($Δ16.58$%), while maintaining a comparable task completion behavior. Based on these results, we discuss immediate implications for the configuration and deployment of AI coding agents in practice, and outline a broader research agenda on the role of repository-level instructions in shaping the behavior, efficiency, and integration of AI coding agents in software development workflows.
Repository Intelligence Graph: Deterministic Architectural Map for LLM Code Assistants
Jan 15, 2026Repository aware coding agents often struggle to recover build and test structure, especially in multilingual projects where cross language dependencies are encoded across heterogeneous build systems and tooling. We introduce the Repository Intelligence Graph (RIG), a deterministic, evidence backed architectural map that represents buildable components, aggregators, runners, tests, external packages, and package managers, connected by explicit dependency and coverage edges that trace back to concrete build and test definitions. We also present SPADE, a deterministic extractor that constructs RIG from build and test artifacts (currently with an automatic CMake plugin based on the CMake File API and CTest metadata), and exposes RIG as an LLM friendly JSON view that agents can treat as the authoritative description of repository structure. We evaluate three commercial agents (Claude Code, Cursor, Codex) on eight repositories spanning low to high build oriented complexity, including the real world MetaFFI project. Each agent answers thirty structured questions per repository with and without RIG in context, and we measure accuracy, wall clock completion time, and efficiency (seconds per correct answer). Across repositories and agents, providing RIG improves mean accuracy by 12.2\% and reduces completion time by 53.9\%, yielding a mean 57.8\% reduction in seconds per correct answer. Gains are larger in multilingual repositories, which improve by 17.7\% in accuracy and 69.5\% in efficiency on average, compared to 6.6\% and 46.1\% in single language repositories. Qualitative analysis suggests that RIG shifts failures from structural misunderstandings toward reasoning mistakes over a correct structure, while rare regressions highlight that graph based reasoning quality remains a key factor.
Automated QoR improvement in OpenROAD with coding agents
Jan 09, 2026EDA development and innovation has been constrained by scarcity of expert engineering resources. While leading LLMs have demonstrated excellent performance in coding and scientific reasoning tasks, their capacity to advance EDA technology itself has been largely untested. We present AuDoPEDA, an autonomous, repository-grounded coding system built atop OpenAI models and a Codex-class agent that reads OpenROAD, proposes research directions, expands them into implementation steps, and submits executable diffs. Our contributions include (i) a closed-loop LLM framework for EDA code changes; (ii) a task suite and evaluation protocol on OpenROAD for PPA-oriented improvements; and (iii) end-to-end demonstrations with minimal human oversight. Experiments in OpenROAD achieve routed wirelength reductions of up to 5.9%, and effective clock period reductions of up to 10.0%.
ParaCodex: A Profiling-Guided Autonomous Coding Agent for Reliable Parallel Code Generation and Translation
Jan 07, 2026Parallel programming is central to HPC and AI, but producing code that is correct and fast remains challenging, especially for OpenMP GPU offload, where data movement and tuning dominate. Autonomous coding agents can compile, test, and profile on target hardware, but outputs are brittle without domain scaffolding. We present ParaCodex, an HPC-engineer workflow that turns a Codex-based agent into an autonomous OpenMP GPU offload system using staged hotspot analysis, explicit data planning, correctness gating, and profiling-guided refinement. We evaluate translation from serial CPU kernels to OpenMP GPU offload kernels on HeCBench, Rodinia, and NAS. After excluding five kernels, ParaCodex succeeded on all 31 valid kernels. The generated kernels improved GPU time over reference OpenMP implementations in 25/31 cases, achieving geometric-mean speedups of 3x on HeCBench and 5x on Rodinia, and outperforming a zero-shot Codex baseline on all suites. We also evaluate CUDA to OpenMP offload translation on ParEval, where ParaCodex maintains high compilation and validation rates in code-only and end-to-end settings.
130k Lines of Formal Topology in Two Weeks: Simple and Cheap Autoformalization for Everyone?
Jan 06, 2026This is a brief description of a project that has already autoformalized a large portion of the general topology from the Munkres textbook (which has in total 241 pages in 7 chapters and 39 sections). The project has been running since November 21, 2025 and has as of January 4, 2026, produced 160k lines of formalized topology. Most of it (about 130k lines) have been done in two weeks,from December 22 to January 4, for an LLM subscription cost of about \$100. This includes a 3k-line proof of Urysohn's lemma, a 2k-line proof of Urysohn's Metrization theorem, over 10k-line proof of the Tietze extension theorem, and many more (in total over 1.5k lemmas/theorems). The approach is quite simple and cheap: build a long-running feedback loop between an LLM and a reasonably fast proof checker equipped with a core foundational library. The LLM is now instantiated as ChatGPT (mostly 5.2) or Claude Sonnet (4.5) run through the respective Codex or Claude Code command line interfaces. The proof checker is Chad Brown's higher-order set theory system Megalodon, and the core library is Brown's formalization of basic set theory and surreal numbers (including reals, etc). The rest is some prompt engineering and technical choices which we describe here. Based on the fast progress, low cost, virtually unknown ITP/library, and the simple setup available to everyone, we believe that (auto)formalization may become quite easy and ubiquitous in 2026, regardless of which proof assistant is used.
AI-Generated Code Is Not Reproducible (Yet): An Empirical Study of Dependency Gaps in LLM-Based Coding Agents
Dec 26, 2025The rise of Large Language Models (LLMs) as coding agents promises to accelerate software development, but their impact on generated code reproducibility remains largely unexplored. This paper presents an empirical study investigating whether LLM-generated code can be executed successfully in a clean environment with only OS packages and using only the dependencies that the model specifies. We evaluate three state-of-the-art LLM coding agents (Claude Code, OpenAI Codex, and Gemini) across 300 projects generated from 100 standardized prompts in Python, JavaScript, and Java. We introduce a three-layer dependency framework (distinguishing between claimed, working, and runtime dependencies) to quantify execution reproducibility. Our results show that only 68.3% of projects execute out-of-the-box, with substantial variation across languages (Python 89.2%, Java 44.0%). We also find a 13.5 times average expansion from declared to actual runtime dependencies, revealing significant hidden dependencies.
A Systematic Study of Code Obfuscation Against LLM-based Vulnerability Detection
Dec 18, 2025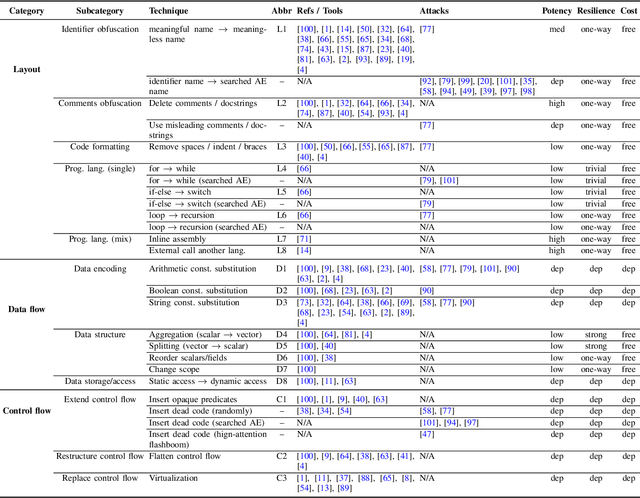
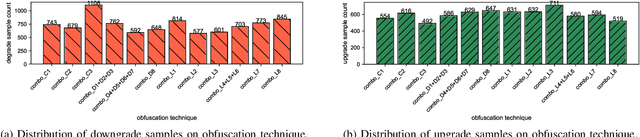

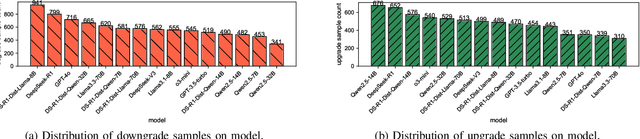
As large language models (LLMs) are increasingly adopted for code vulnerability detection, their reliability and robustness across diverse vulnerability types have become a pressing concern. In traditional adversarial settings, code obfuscation has long been used as a general strategy to bypass auditing tools, preserving exploitability without tampering with the tools themselves. Numerous efforts have explored obfuscation methods and tools, yet their capabilities differ in terms of supported techniques, granularity, and programming languages, making it difficult to systematically assess their impact on LLM-based vulnerability detection. To address this gap, we provide a structured systematization of obfuscation techniques and evaluate them under a unified framework. Specifically, we categorize existing obfuscation methods into three major classes (layout, data flow, and control flow) covering 11 subcategories and 19 concrete techniques. We implement these techniques across four programming languages (Solidity, C, C++, and Python) using a consistent LLM-driven approach, and evaluate their effects on 15 LLMs spanning four model families (DeepSeek, OpenAI, Qwen, and LLaMA), as well as on two coding agents (GitHub Copilot and Codex). Our findings reveal both positive and negative impacts of code obfuscation on LLM-based vulnerability detection, highlighting conditions under which obfuscation leads to performance improvements or degradations. We further analyze these outcomes with respect to vulnerability characteristics, code properties, and model attributes. Finally, we outline several open problems and propose future directions to enhance the robustness of LLMs for real-world vulnerability detection.
Preserving Marker Specificity with Lightweight Channel-Independent Representation Learning
Dec 17, 2025Multiplexed tissue imaging measures dozens of protein markers per cell, yet most deep learning models still apply early channel fusion, assuming shared structure across markers. We investigate whether preserving marker independence, combined with deliberately shallow architectures, provides a more suitable inductive bias for self-supervised representation learning in multiplex data than increasing model scale. Using a Hodgkin lymphoma CODEX dataset with 145,000 cells and 49 markers, we compare standard early-fusion CNNs with channel-separated architectures, including a marker-aware baseline and our novel shallow Channel-Independent Model (CIM-S) with 5.5K parameters. After contrastive pretraining and linear evaluation, early-fusion models show limited ability to retain marker-specific information and struggle particularly with rare-cell discrimination. Channel-independent architectures, and CIM-S in particular, achieve substantially stronger representations despite their compact size. These findings are consistent across multiple self-supervised frameworks, remain stable across augmentation settings, and are reproducible across both the 49-marker and reduced 18-marker settings. These results show that lightweight, channel-independent architectures can match or surpass deep early-fusion CNNs and foundation models for multiplex representation learning. Code is available at https://github.com/SimonBon/CIM-S.
Market-Bench: Evaluating Large Language Models on Introductory Quantitative Trading and Market Dynamics
Dec 13, 2025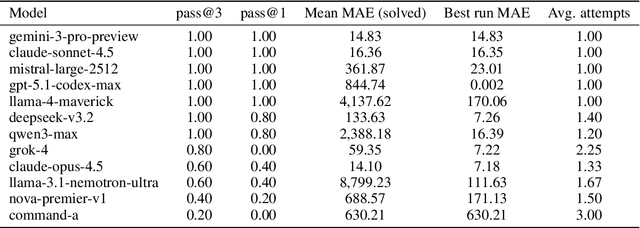
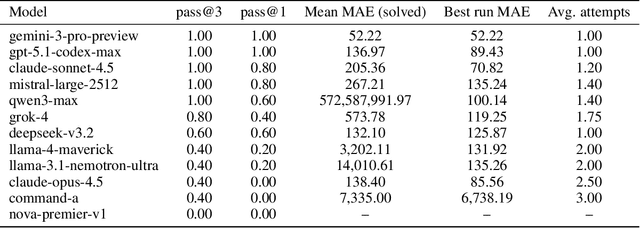


We introduce MARKET-BENCH, a benchmark that evaluates large language models (LLMs) on introductory quantitative trading tasks by asking them to construct executable backtesters from natural-language strategy descriptions and market assumptions. Each instance specifies one of three canonical strategies -- scheduled trading on Microsoft (NASDAQ: MSFT), pairs trading on Coca-Cola (NASDAQ: KO) and Pepsi (NASDAQ: PEP), or delta hedging on MSFT -- and models must produce code whose P\&L, drawdown, and position paths match a verifiable reference implementation. We assess twelve state-of-the-art models using a multi-round pass@k metric that separates structural reliability (whether the backtest runs) from numerical accuracy (mean absolute error of the backtest metrics). While most models reliably execute the simplest strategy (average pass@3 of 0.80), errors vary by orders of magnitude across models and tasks: Gemini 3 Pro and Claude 4.5 Sonnet combine strong reliability with low error on simpler strategies, GPT-5.1 Codex-Max achieves perfect pass@1 on the first two strategies and the lowest best-run error on the easiest task, and Qwen3 Max attains perfect pass@3 yet sometimes produces inaccurate P\&L paths. These results show that current LLMs can scaffold basic trading infrastructure but still struggle to reason robustly about prices, inventory, and risk; we release MARKET-BENCH and a public leaderboard at https://marketbench.ai.