 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impact of AGENTS.md Files on the Efficiency of AI Coding Agents
Jan 28, 2026AI coding agents such as Codex and Claude Code are increasingly used to autonomously contribute to software repositories. However, little is known about how repository-level configuration artifacts affect operational efficiency of the agents. In this paper, we study the impact of AGENTS$.$md files on the runtime and token consumption of AI coding agents operating on GitHub pull requests. We analyze 10 repositories and 124 pull requests, executing agents under two conditions: with and without an AGENTS$.$md file. We measure wall-clock execution time and token usage during agent execution. Our results show that the presence of AGENTS$.$md is associated with a lower median runtime ($Δ28.64$%) and reduced output token consumption ($Δ16.58$%), while maintaining a comparable task completion behavior. Based on these results, we discuss immediate implications for the configuration and deployment of AI coding agents in practice, and outline a broader research agenda on the role of repository-level instructions in shaping the behavior, efficiency, and integration of AI coding agents in software development workflows.
Automated Query Reformulation for Efficient Search based on Query Logs From Stack Overflow
Feb 10, 2021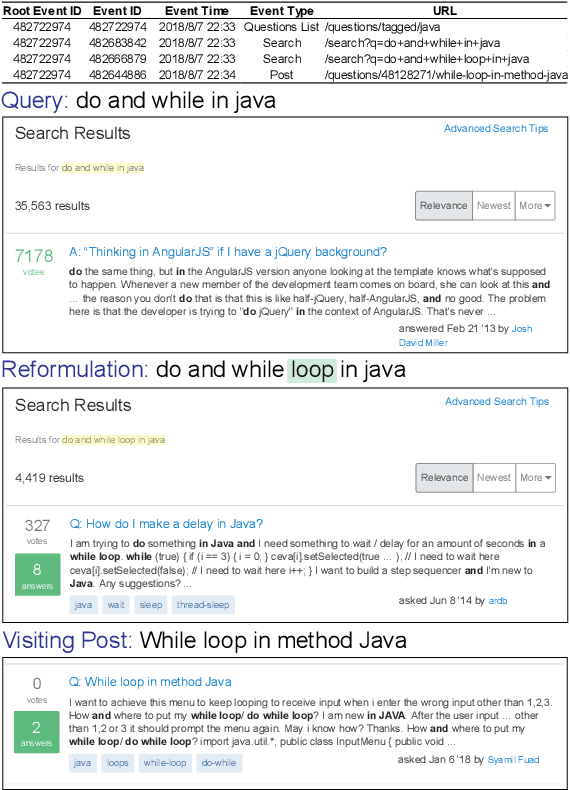
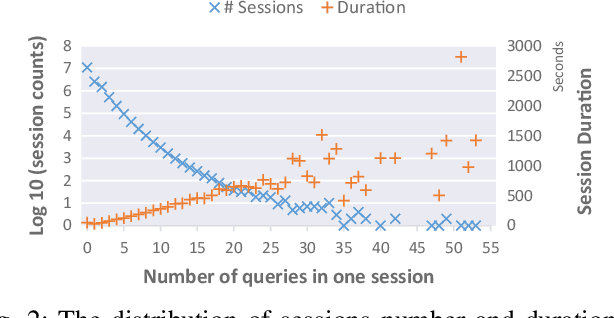

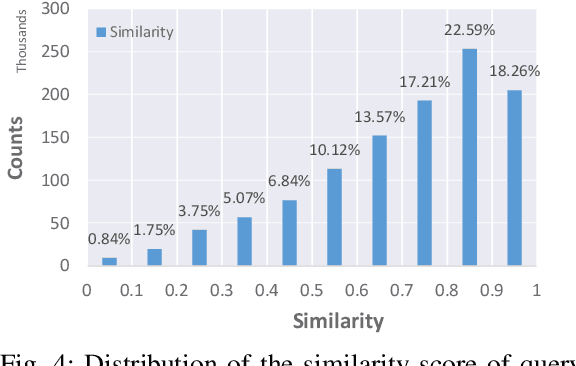
As a popular Q&A site for programming, Stack Overflow is a treasure for developers. However, the amount of questions and answers on Stack Overflow make it difficult for developers to efficiently locate the information they are looking for. There are two gaps leading to poor search results: the gap between the user's intention and the textual query, and the semantic gap between the query and the post content. Therefore, developers have to constantly reformulate their queries by correcting misspelled words, adding limitations to certain programming languages or platforms, etc. As query reformulation is tedious for developers, especially for novices, we propose an automated software-specific query reformulation approach based on deep learning. With query logs provided by Stack Overflow, we construct a large-scale query reformulation corpus, including the original queries and corresponding reformulated ones. Our approach trains a Transformer model that can automatically generate candidate reformulated queries when given the user's original query. The evaluation results show that our approach outperforms five state-of-the-art baselines, and achieves a 5.6% to 33.5% boost in terms of $\mathit{ExactMatch}$ and a 4.8% to 14.4% boost in terms of $\mathit{GLEU}$.
An Annotated Dataset of Stack Overflow Post Edits
May 06, 2020
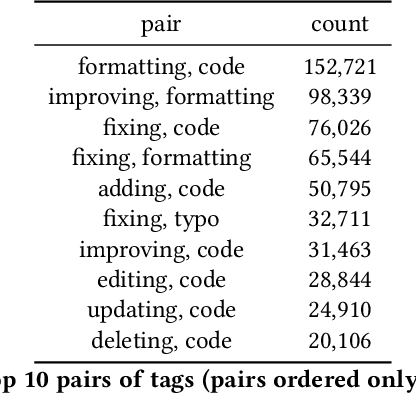
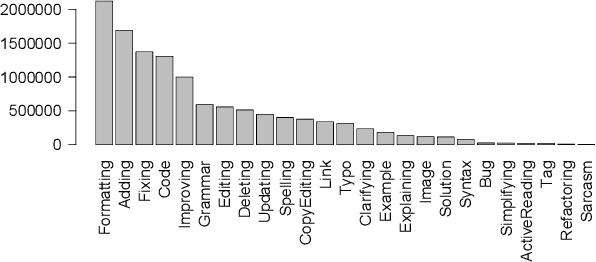
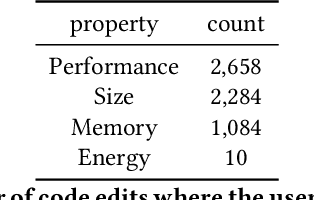
To improve software engineering, software repositories have been mined for code snippets and bug fixes. Typically, this mining takes place at the level of files or commits. To be able to dig deeper and to extract insights at a higher resolution, we hereby present an annotated dataset that contains over 7 million edits of code and text on Stack Overflow. Our preliminary study indicates that these edits might be a treasure trove for mining information about fine-grained patches, e.g., for the optimisation of non-functional properties.