 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaCodex: A Profiling-Guided Autonomous Coding Agent for Reliable Parallel Code Generation and Translation
Jan 07, 2026Parallel programming is central to HPC and AI, but producing code that is correct and fast remains challenging, especially for OpenMP GPU offload, where data movement and tuning dominate. Autonomous coding agents can compile, test, and profile on target hardware, but outputs are brittle without domain scaffolding. We present ParaCodex, an HPC-engineer workflow that turns a Codex-based agent into an autonomous OpenMP GPU offload system using staged hotspot analysis, explicit data planning, correctness gating, and profiling-guided refinement. We evaluate translation from serial CPU kernels to OpenMP GPU offload kernels on HeCBench, Rodinia, and NAS. After excluding five kernels, ParaCodex succeeded on all 31 valid kernels. The generated kernels improved GPU time over reference OpenMP implementations in 25/31 cases, achieving geometric-mean speedups of 3x on HeCBench and 5x on Rodinia, and outperforming a zero-shot Codex baseline on all suites. We also evaluate CUDA to OpenMP offload translation on ParEval, where ParaCodex maintains high compilation and validation rates in code-only and end-to-end settings.
Workflows vs Agents for Code Translation
Dec 15, 2025



Translating algorithms from high-level languages like MATLAB to hardware description languages (HDLs) is a resource-intensive but necessary step for deployment on FPGAs and ASICs. While large language models (LLMs) offer a path to automation, their limited training on HDL code makes end-to-end transpilation brittle and prone to syntax errors. We compare two LLM-driven methods for syntax repair in a MATLAB-to-HDL pipeline: a structured, expert-designed flow that follows a fixed sequence of operations, and a more autonomous agentic approach that uses the Model Context Protocol (MCP) \cite{anthropic2024mcp} to dynamically select its own tools. We study 42 MATLAB signal-processing functions and isolate the syntax-repair stage. Across three model scales, the agentic approach is more effective at resolving initial syntax errors, unblocking a greater number of candidates to proceed through the pipeline. This upstream improvement yields measurable downstream improvements, most notably on mid-sized models, where it increases the simulation reach rate by over 20 percentage points. We hypothesize the gains come from short prompts, aggressive context management, and conditional tool use. Conditional retrieval helps at 8B and 30B; at 235B final-success gains are small and a naive RAG variant attains the highest final success. Our findings suggest that these agentic frameworks, when properly designed, are most effective at compensating for the capacity limits of small and mid-sized models.
Measurement Simplification in ρ-POMDP with Performance Guarantees
Sep 19, 2023
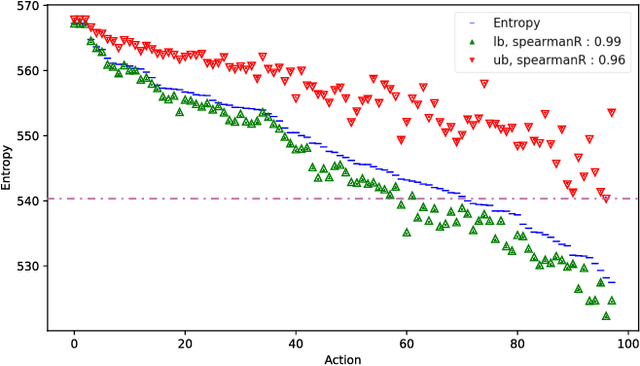
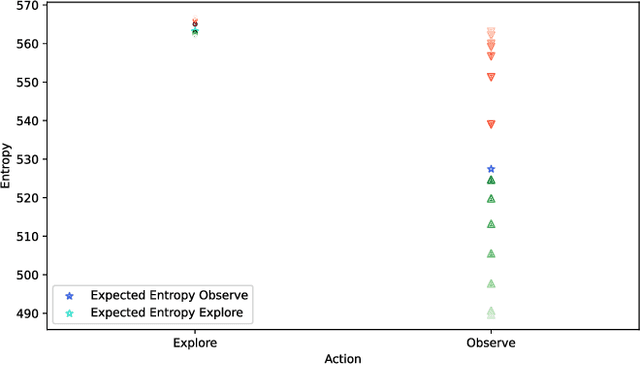

Decision making under uncertainty is at the heart of any autonomous system acting with imperfect information. The cost of solving the decision making problem is exponential in the action and observation spaces, thus rendering it unfeasible for many online systems. This paper introduces a novel approach to efficient decision-making, by partitioning the high-dimensional observation space. Using the partitioned observation space, we formulate analytical bounds on the expected information-theoretic reward, for general belief distributions. These bounds are then used to plan efficiently while keeping performance guarantees. We show that the bounds are adaptive, computationally efficient, and that they converge to the original solution. We extend the partitioning paradigm and present a hierarchy of partitioned spaces that allows greater efficiency in planning. We then propose a specific variant of these bounds for Gaussian beliefs and show a theoretical performance improvement of at least a factor of 4. Finally, we compare our novel method to other state of the art algorithms in active SLAM scenarios, in simulation and in real experiments. In both cases we show a significant speed-up in planning with performance guarantees.