 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarbonEdge: Carbon-Aware Deep Learning Inference Framework for Sustainable Edge Computing
Apr 01, 2026Deep learning applications at the network edge lead to a significant growth in AI-related carbon emissions, presenting a critical sustainability challenge. The existing edge computing frameworks optimize for latency and throughput, but they largely ignore the environmental impact of inference workloads. This paper introduces CarbonEdge, a carbon-aware deep learning inference framework that extends adaptive model partitioning with carbon footprint estimation and green scheduling apabilities. We propose a carbon-aware scheduling algorithm that extends traditional weighted scoring with a carbon efficiency metric, supporting a tunable performance--carbon trade-off (demonstrated via weight sweep). Experimental evaluations on Docker-simulated heterogeneous edge environments show that CarbonEdge-Green mode achieves a 22.9% reduction in carbon emissions compared to monolithic execution. The framework achieves 1.3x improvement in carbon efficiency (245.8 vs 189.5 inferences per gram CO2) with negligible scheduling overhead (0.03ms per task). These results highlight the framework's potential for sustainable edge AI deployment, providing researchers and practitioners a tool to quantify and minimize the environmental footprint of distributed deep learning inference.
Adaptive GPU Resource Allocation for Multi-Agent Collaborative Reasoning in Serverless Environments
Dec 15, 2025Multi-agent systems powered by large language models have emerged as a promising paradigm for solving complex reasoning tasks through collaborative intelligence. However, efficiently deploying these systems on serverless GPU platforms presents significant resource allocation challenges due to heterogeneous agent workloads, varying computational demands, and the need for cost-effective scaling. This paper presents an adaptive GPU resource allocation framework that achieves 85\% latency reduction compared to round-robin scheduling while maintaining comparable throughput to static allocation, using an $O(N)$ complexity algorithm for real-time adaptation. Our approach dynamically allocates GPU resources based on workload characteristics, agent priorities, and minimum resource requirements, enabling efficient utilization while maintaining quality of service. The framework addresses three key challenges: (1) heterogeneous computational demands across lightweight coordinators and heavyweight specialists, (2) dynamic workload fluctuations requiring millisecond-scale reallocation, and (3) capacity constraints in serverless environments. Through comprehensive simulations modeling realistic multi-agent workflows with four heterogeneous agents, we demonstrate that adaptive allocation outperforms static equal and round-robin strategies across latency, cost, and GPU utilization metrics. The framework provides a practical solution for deploying cost-efficient multi-agent AI systems on serverless GPU infrastructure.
* 7 pages, 2 figures
Probing many-body Bell correlation depth with superconducting qubits
Jun 25, 2024


Quantum nonlocality describes a stronger form of quantum correlation than that of entanglement. It refutes Einstein's belief of local realism and is among the most distinctive and enigmatic features of quantum mechanics. It is a crucial resource for achieving quantum advantages in a variety of practical applications, ranging from cryptography and certified random number generation via self-testing to machine learning. Nevertheless, the detection of nonlocality, especially in quantum many-body systems, is notoriously challenging. Here, we report an experimental certification of genuine multipartite Bell correlations, which signal nonlocality in quantum many-body systems, up to 24 qubits with a fully programmable superconducting quantum processor. In particular, we employ energy as a Bell correlation witness and variationally decrease the energy of a many-body system across a hierarchy of thresholds, below which an increasing Bell correlation depth can be certified from experimental data. As an illustrating example, we variationally prepare the low-energy state of a two-dimensional honeycomb model with 73 qubits and certify its Bell correlations by measuring an energy that surpasses the corresponding classical bound with up to 48 standard deviations. In addition, we variationally prepare a sequence of low-energy states and certify their genuine multipartite Bell correlations up to 24 qubits via energies measured efficiently by parity oscillation and multiple quantum coherence techniques. Our results establish a viable approach for preparing and certifying multipartite Bell correlations, which provide not only a finer benchmark beyond entanglement for quantum devices, but also a valuable guide towards exploiting multipartite Bell correlation in a wide spectrum of practical applications.
Edge-Cloud Polarization and Collaboration: A Comprehensive Survey
Nov 12, 2021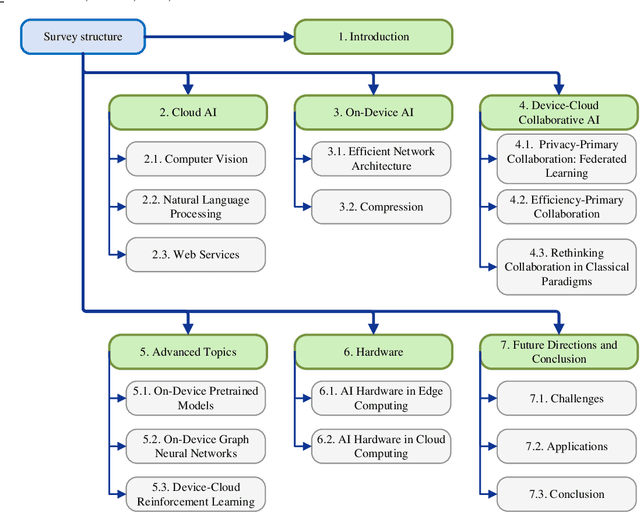
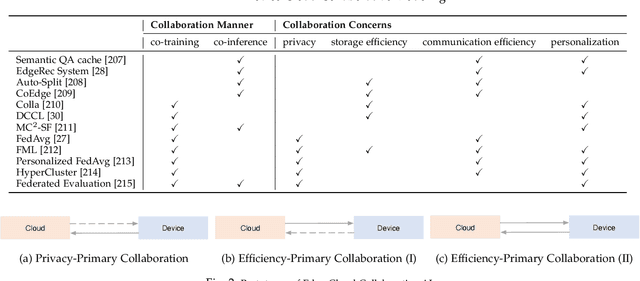
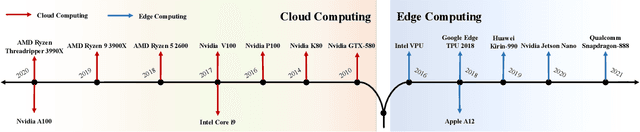
Influenced by the great success of deep learning via cloud computing and the rapid development of edge chips, research in artificial intelligence (AI) has shifted to both of the computing paradigms, i.e., cloud computing and edge computing. In recent years, we have witnessed significant progress in developing more advanced AI models on cloud servers that surpass traditional deep learning models owing to model innovations (e.g., Transformers, Pretrained families), explosion of training data and soaring computing capabilities. However, edge computing, especially edge and cloud collaborative computing, are still in its infancy to announce their success due to the resource-constrained IoT scenarios with very limited algorithms deployed. In this survey, we conduct a systematic review for both cloud and edge AI. Specifically, we are the first to set up the collaborative learning mechanism for cloud and edge modeling with a thorough review of the architectures that enable such mechanism. We also discuss potentials and practical experiences of some on-going advanced edge AI topics including pretraining models, graph neural networks and reinforcement learning. Finally, we discuss the promising directions and challenges in this field.
Poet: Product-oriented Video Captioner for E-commerce
Aug 16, 2020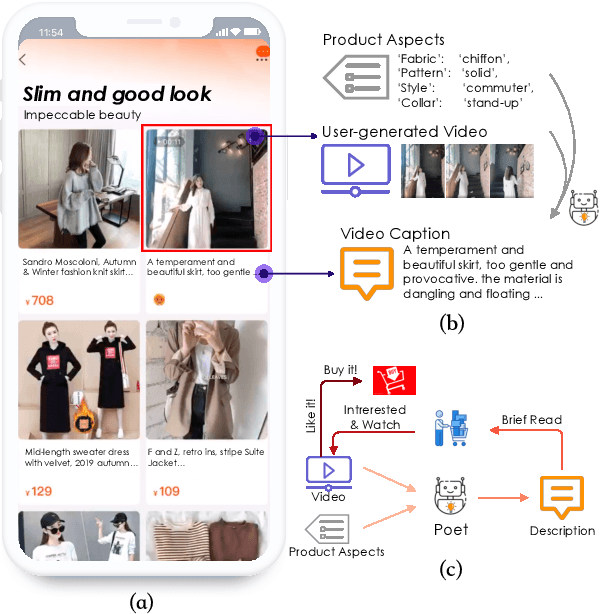
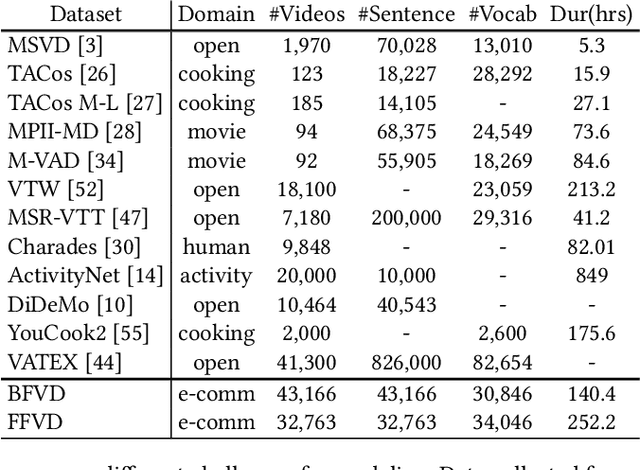
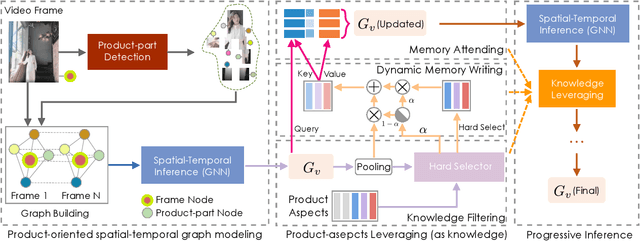
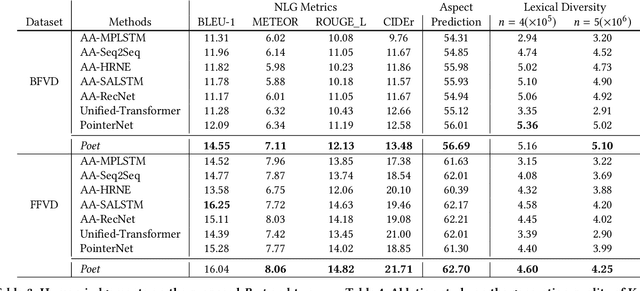
In e-commerce, a growing number of user-generated videos are used for product promotion. How to generate video descriptions that narrate the user-preferred product characteristics depicted in the video is vital for successful promoting. Traditional video captioning methods, which focus on routinely describing what exists and happens in a video, are not amenable for product-oriented video captioning. To address this problem, we propose a product-oriented video captioner framework, abbreviated as Poet. Poet firstly represents the videos as product-oriented spatial-temporal graphs. Then, based on the aspects of the video-associated product, we perform knowledge-enhanced spatial-temporal inference on those graphs for capturing the dynamic change of fine-grained product-part characteristics. The knowledge leveraging module in Poet differs from the traditional design by performing knowledge filtering and dynamic memory modeling. We show that Poet achieves consistent performance improvement over previous methods concerning generation quality, product aspects capturing, and lexical diversity. Experiments are performed on two product-oriented video captioning datasets, buyer-generated fashion video dataset (BFVD) and fan-generated fashion video dataset (FFVD), collected from Mobile Taobao. We will release the desensitized datasets to promote further investigations on both video captioning and general video analysis problems.
Comprehensive Information Integration Modeling Framework for Video Titling
Jun 24, 2020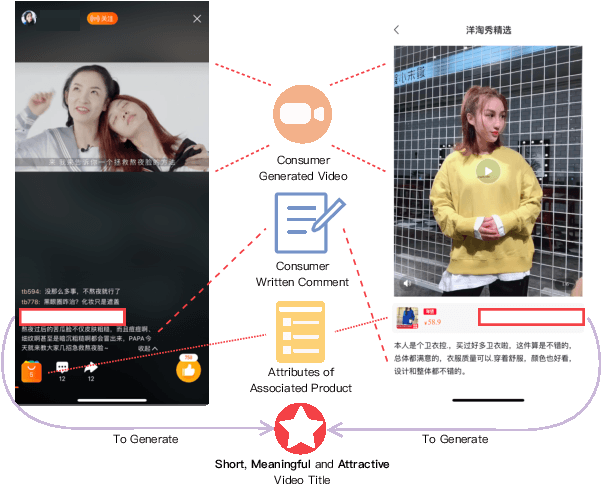

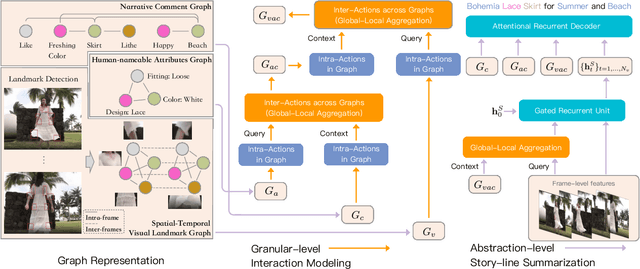
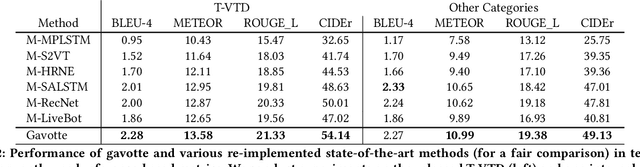
In e-commerce, consumer-generated videos, which in general deliver consumers' individual preferences for the different aspects of certain products, are massive in volume. To recommend these videos to potential consumers more effectively, diverse and catchy video titles are critical. However, consumer-generated videos seldom accompany appropriate titles. To bridge this gap, we integrate comprehensive sources of information, including the content of consumer-generated videos, the narrative comment sentences supplied by consumers, and the product attributes, in an end-to-end modeling framework. Although automatic video titling is very useful and demanding, it is much less addressed than video captioning. The latter focuses on generating sentences that describe videos as a whole while our task requires the product-aware multi-grained video analysis. To tackle this issue, the proposed method consists of two processes, i.e., granular-level interaction modeling and abstraction-level story-line summarization. Specifically, the granular-level interaction modeling first utilizes temporal-spatial landmark cues, descriptive words, and abstractive attributes to builds three individual graphs and recognizes the intra-actions in each graph through Graph Neural Networks (GNN). Then the global-local aggregation module is proposed to model inter-actions across graphs and aggregate heterogeneous graphs into a holistic graph representation. The abstraction-level story-line summarization further considers both frame-level video features and the holistic graph to utilize the interactions between products and backgrounds, and generate the story-line topic of the video. We collect a large-scale dataset accordingly from real-world data in Taobao, a world-leading e-commerce platform, and will make the desensitized version publicly available to nourish further development of the research community...
Grounded and Controllable Image Completion by Incorporating Lexical Semantics
Feb 29, 2020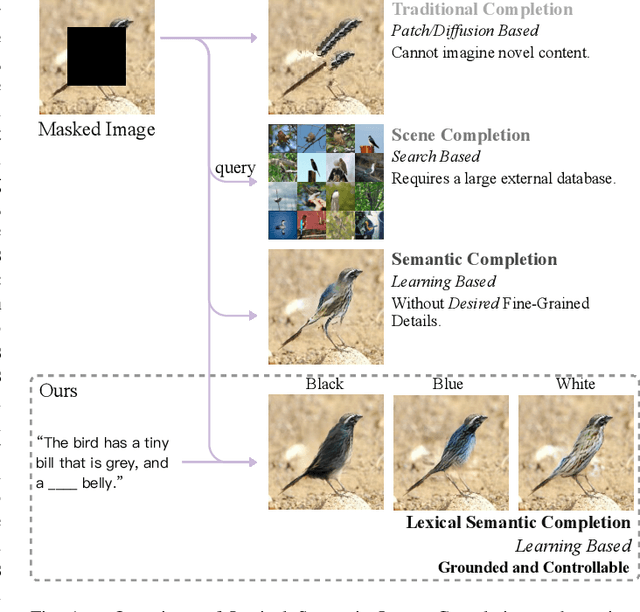
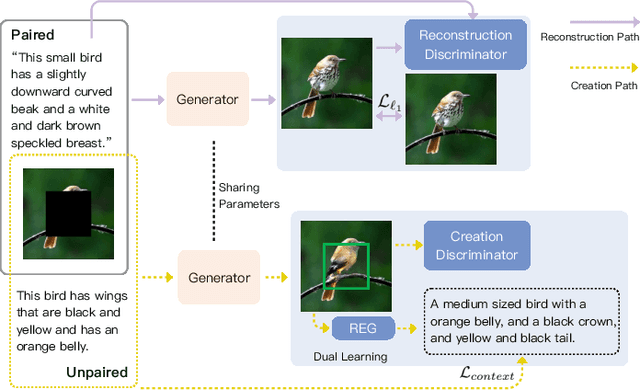
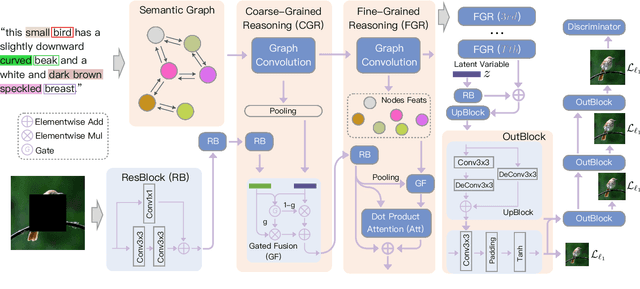

In this paper, we present an approach, namely Lexical Semantic Image Completion (LSIC), that may have potential applications in art, design, and heritage conservation, among several others. Existing image completion procedure is highly subjective by considering only visual context, which may trigger unpredictable results which are plausible but not faithful to a grounded knowledge. To permit both grounded and controllable completion process, we advocate generating results faithful to both visual and lexical semantic context, i.e., the description of leaving holes or blank regions in the image (e.g., hole description). One major challenge for LSIC comes from modeling and aligning the structure of visual-semantic context and translating across different modalities. We term this process as structure completion, which is realized by multi-grained reasoning blocks in our model. Another challenge relates to the unimodal biases, which occurs when the model generates plausible results without using the textual description. This can be true since the annotated captions for an image are often semantically equivalent in existing datasets, and thus there is only one paired text for a masked image in training. We devise an unsupervised unpaired-creation learning path besides the over-explored paired-reconstruction path, as well as a multi-stage training strategy to mitigate the insufficiency of labeled data. We conduct extensive quantitative and qualitative experiments as well as ablation studies, which reveal the efficacy of our proposed LSIC.