 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive Information Integration Modeling Framework for Video Titling
Paper and Code
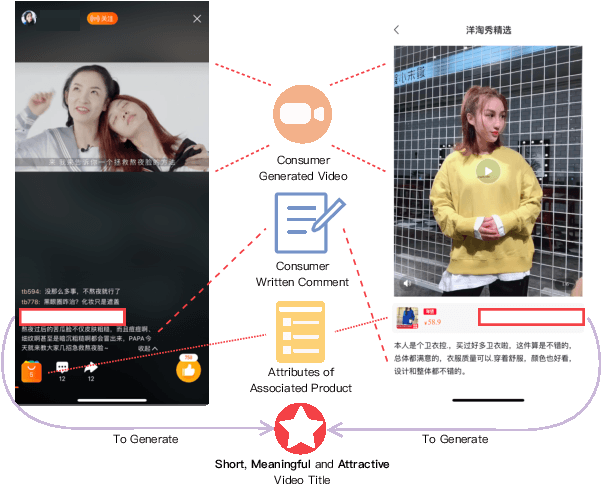

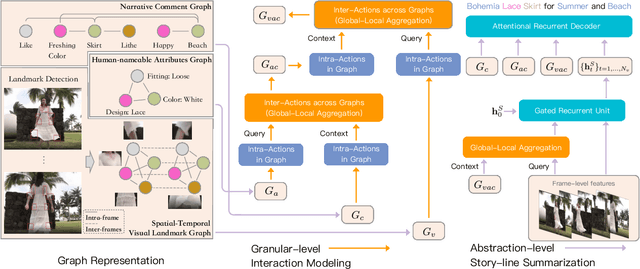
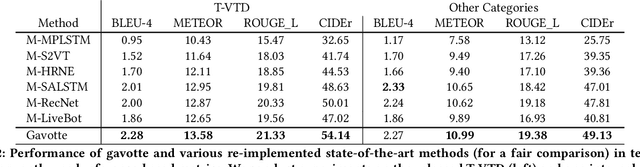
In e-commerce, consumer-generated videos, which in general deliver consumers' individual preferences for the different aspects of certain products, are massive in volume. To recommend these videos to potential consumers more effectively, diverse and catchy video titles are critical. However, consumer-generated videos seldom accompany appropriate titles. To bridge this gap, we integrate comprehensive sources of information, including the content of consumer-generated videos, the narrative comment sentences supplied by consumers, and the product attributes, in an end-to-end modeling framework. Although automatic video titling is very useful and demanding, it is much less addressed than video captioning. The latter focuses on generating sentences that describe videos as a whole while our task requires the product-aware multi-grained video analysis. To tackle this issue, the proposed method consists of two processes, i.e., granular-level interaction modeling and abstraction-level story-line summarization. Specifically, the granular-level interaction modeling first utilizes temporal-spatial landmark cues, descriptive words, and abstractive attributes to builds three individual graphs and recognizes the intra-actions in each graph through Graph Neural Networks (GNN). Then the global-local aggregation module is proposed to model inter-actions across graphs and aggregate heterogeneous graphs into a holistic graph representation. The abstraction-level story-line summarization further considers both frame-level video features and the holistic graph to utilize the interactions between products and backgrounds, and generate the story-line topic of the video. We collect a large-scale dataset accordingly from real-world data in Taobao, a world-leading e-commerce platform, and will make the desensitized version publicly available to nourish further development of the research community...