 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Apr 15, 2025We introduce InternVL3, a significant advancement in the InternVL series featuring a native multimodal pre-training paradigm. Rather than adapting a text-only large language model (LLM) into a multimodal large language model (MLLM) that supports visual inputs, InternVL3 jointly acquires multimodal and linguistic capabilities from both diverse multimodal data and pure-text corpora during a single pre-training stage. This unified training paradigm effectively addresses the complexities and alignment challenges commonly encountered in conventional post-hoc training pipelines for MLLMs. To further improve performance and scalability, InternVL3 incorporates variable visual position encoding (V2PE) to support extended multimodal contexts, employs advanced post-training techniques such as supervised fine-tuning (SFT) and mixed preference optimization (MPO), and adopts test-time scaling strategies alongside an optimized training infrastructure. Extensive empirical evaluations demonstrate that InternVL3 delivers superior performance across a wide range of multi-modal tasks. In particular, InternVL3-78B achieves a score of 72.2 on the MMMU benchmark, setting a new state-of-the-art among open-source MLLMs. Its capabilities remain highly competitive with leading proprietary models, including ChatGPT-4o, Claude 3.5 Sonnet, and Gemini 2.5 Pro, while also maintaining strong pure-language proficiency. In pursuit of open-science principles, we will publicly release both the training data and model weights to foster further research and development in next-generation MLLMs.
Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
Dec 06, 2024



We introduce InternVL 2.5, an advanced multimodal large language model (MLLM) series that builds upon InternVL 2.0, maintaining its core model architecture while introducing significant enhancements in training and testing strategies as well as data quality. In this work, we delve into the relationship between model scaling and performance, systematically exploring the performance trends in vision encoders, language models, dataset sizes, and test-time configurations. Through extensive evaluations on a wide range of benchmarks, including multi-discipline reasoning, document understanding, multi-image / video understanding, real-world comprehension, multimodal hallucination detection, visual grounding, multilingual capabilities, and pure language processing, InternVL 2.5 exhibits competitive performance, rivaling leading commercial models such as GPT-4o and Claude-3.5-Sonnet. Notably, our model is the first open-source MLLMs to surpass 70% on the MMMU benchmark, achieving a 3.7-point improvement through Chain-of-Thought (CoT) reasoning and showcasing strong potential for test-time scaling. We hope this model contributes to the open-source community by setting new standards for developing and applying multimodal AI systems. HuggingFace demo see https://huggingface.co/spaces/OpenGVLab/InternVL
DeVLBert: Learning Deconfounded Visio-Linguistic Representations
Aug 16, 2020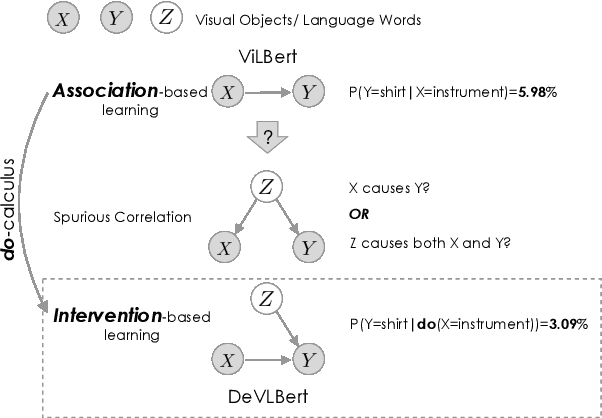
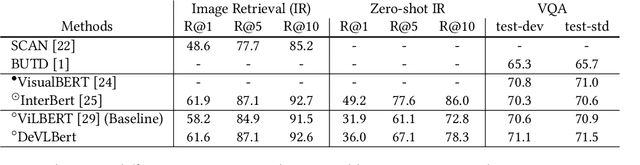
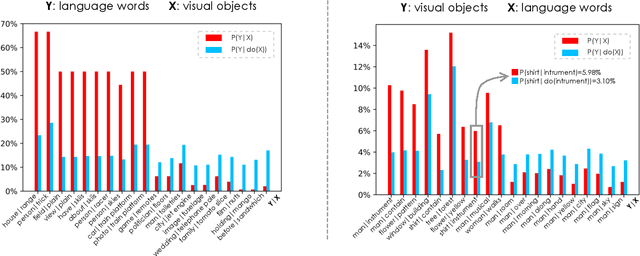
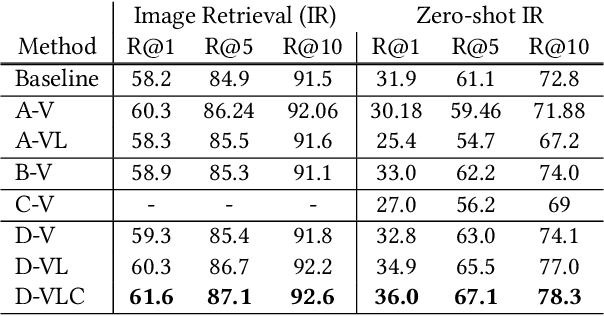
In this paper, we propose to investigate the problem of out-of-domain visio-linguistic pretraining, where the pretraining data distribution differs from that of downstream data on which the pretrained model will be fine-tuned. Existing methods for this problem are purely likelihood-based, leading to the spurious correlations and hurt the generalization ability when transferred to out-of-domain downstream tasks. By spurious correlation, we mean that the conditional probability of one token (object or word) given another one can be high (due to the dataset biases) without robust (causal) relationships between them. To mitigate such dataset biases, we propose a Deconfounded Visio-Linguistic Bert framework, abbreviated as DeVLBert, to perform intervention-based learning. We borrow the idea of the backdoor adjustment from the research field of causality and propose several neural-network based architectures for Bert-style out-of-domain pretraining. The quantitative results on three downstream tasks, Image Retrieval (IR), Zero-shot IR, and Visual Question Answering, show the effectiveness of DeVLBert by boosting generalization ability.
Comprehensive Information Integration Modeling Framework for Video Titling
Jun 24, 2020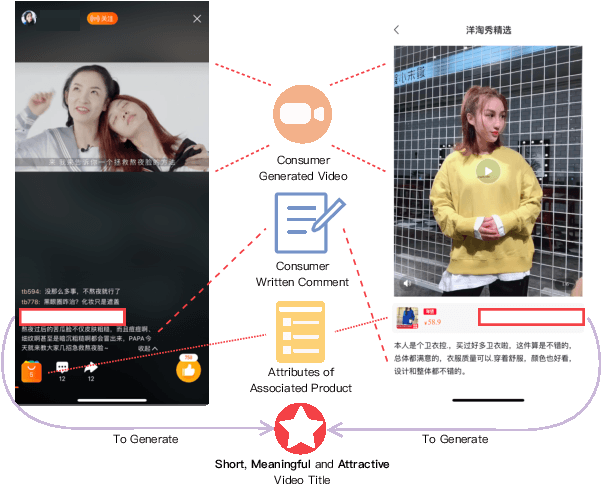

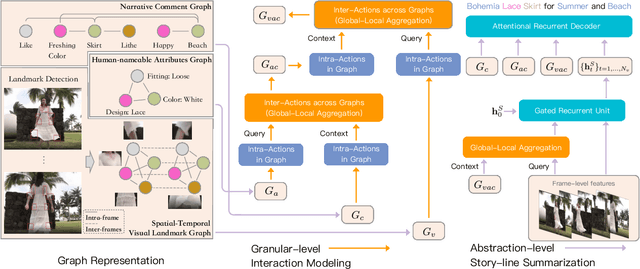
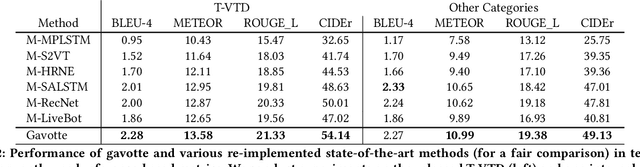
In e-commerce, consumer-generated videos, which in general deliver consumers' individual preferences for the different aspects of certain products, are massive in volume. To recommend these videos to potential consumers more effectively, diverse and catchy video titles are critical. However, consumer-generated videos seldom accompany appropriate titles. To bridge this gap, we integrate comprehensive sources of information, including the content of consumer-generated videos, the narrative comment sentences supplied by consumers, and the product attributes, in an end-to-end modeling framework. Although automatic video titling is very useful and demanding, it is much less addressed than video captioning. The latter focuses on generating sentences that describe videos as a whole while our task requires the product-aware multi-grained video analysis. To tackle this issue, the proposed method consists of two processes, i.e., granular-level interaction modeling and abstraction-level story-line summarization. Specifically, the granular-level interaction modeling first utilizes temporal-spatial landmark cues, descriptive words, and abstractive attributes to builds three individual graphs and recognizes the intra-actions in each graph through Graph Neural Networks (GNN). Then the global-local aggregation module is proposed to model inter-actions across graphs and aggregate heterogeneous graphs into a holistic graph representation. The abstraction-level story-line summarization further considers both frame-level video features and the holistic graph to utilize the interactions between products and backgrounds, and generate the story-line topic of the video. We collect a large-scale dataset accordingly from real-world data in Taobao, a world-leading e-commerce platform, and will make the desensitized version publicly available to nourish further development of the research community...
Grounded and Controllable Image Completion by Incorporating Lexical Semantics
Feb 29, 2020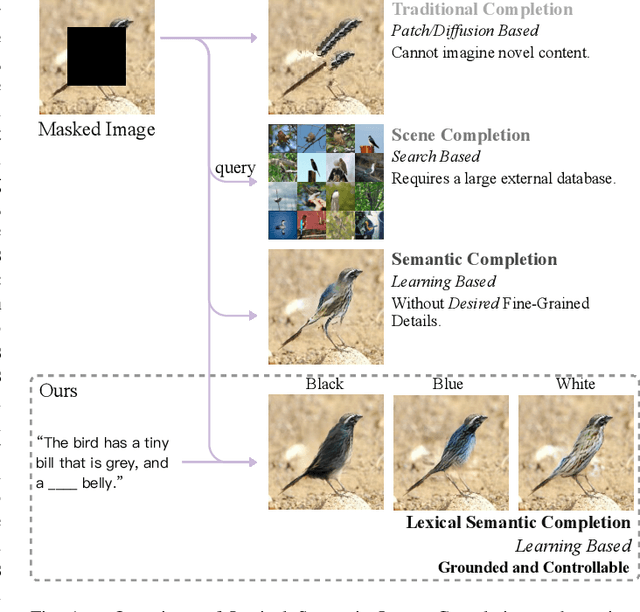
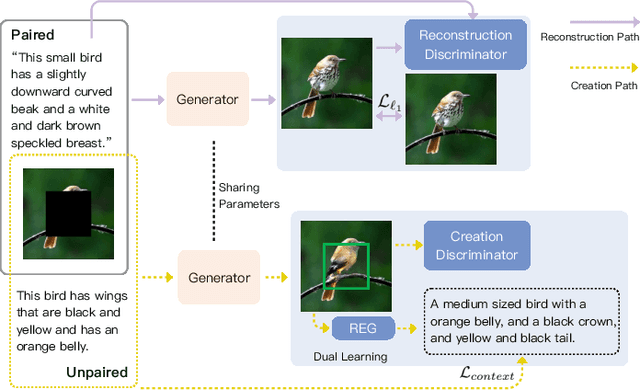
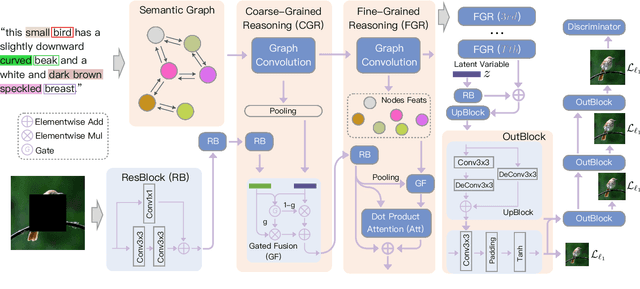

In this paper, we present an approach, namely Lexical Semantic Image Completion (LSIC), that may have potential applications in art, design, and heritage conservation, among several others. Existing image completion procedure is highly subjective by considering only visual context, which may trigger unpredictable results which are plausible but not faithful to a grounded knowledge. To permit both grounded and controllable completion process, we advocate generating results faithful to both visual and lexical semantic context, i.e., the description of leaving holes or blank regions in the image (e.g., hole description). One major challenge for LSIC comes from modeling and aligning the structure of visual-semantic context and translating across different modalities. We term this process as structure completion, which is realized by multi-grained reasoning blocks in our model. Another challenge relates to the unimodal biases, which occurs when the model generates plausible results without using the textual description. This can be true since the annotated captions for an image are often semantically equivalent in existing datasets, and thus there is only one paired text for a masked image in training. We devise an unsupervised unpaired-creation learning path besides the over-explored paired-reconstruction path, as well as a multi-stage training strategy to mitigate the insufficiency of labeled data. We conduct extensive quantitative and qualitative experiments as well as ablation studies, which reveal the efficacy of our proposed LSIC.