 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory as Asset: From Agent-centric to Human-centric Memory Management
Mar 15, 2026We proudly introduce Memory-as-Asset, a new memory paradigm towards human-centric artificial general intelligence (AGI). In this paper, we formally emphasize that human-centric, personal memory management is a prerequisite for complementing the collective knowledge of existing large language models (LLMs) and extending their knowledge boundaries through self-evolution. We introduce three key features that shape the Memory-as-Asset era: (1) Memory in Hand, which emphasizes human-centric ownership to maximize benefits to humans; (2) Memory Group, which provides collaborative knowledge formation to avoid memory islands, and (3) Collective Memory Evolution, which enables continuous knowledge growth to extend the boundary of knowledge towards AGI. We finally give a potential three-layer memory infrastructure to facilitate the Memory-as-Asset paradigm, with fast personal memory storage, an intelligent evolution layer, and a decentralized memory exchange network. Together, these components outline a foundational architecture in which personal memories become persistent digital assets that can be accumulated, shared, and evolved over time. We believe this paradigm provides a promising path toward scalable, human-centric AGI systems that continuously grow through the collective experiences of individuals and intelligent agents.
Grounded and Controllable Image Completion by Incorporating Lexical Semantics
Feb 29, 2020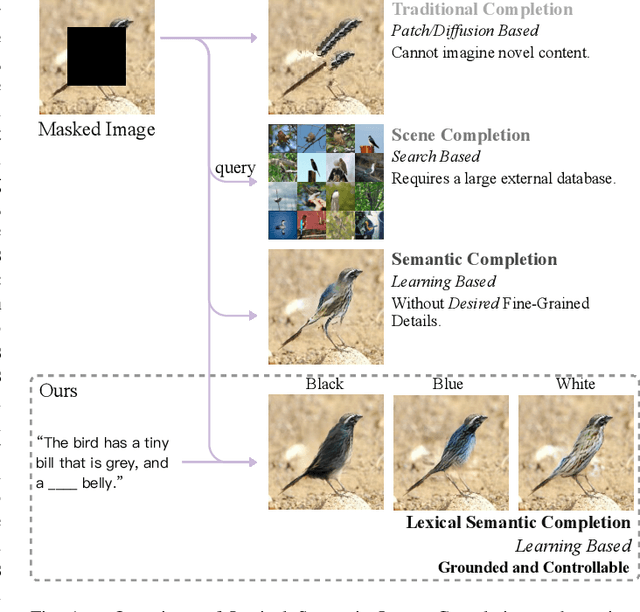
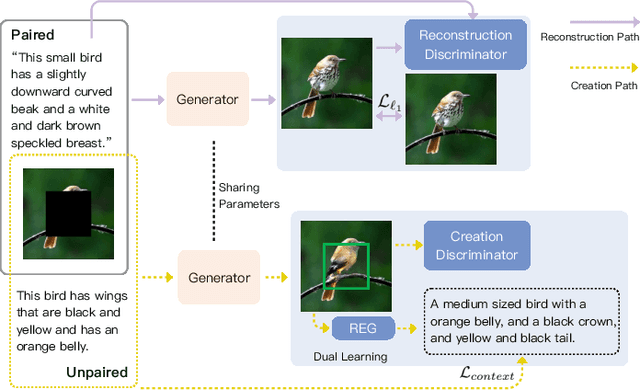
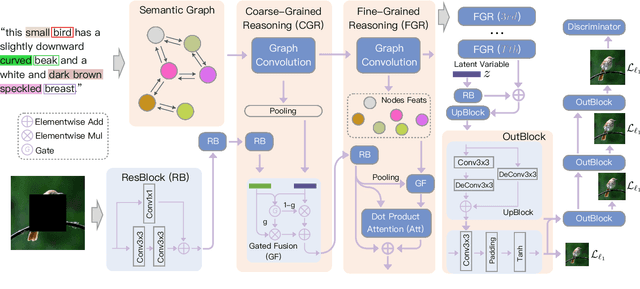

In this paper, we present an approach, namely Lexical Semantic Image Completion (LSIC), that may have potential applications in art, design, and heritage conservation, among several others. Existing image completion procedure is highly subjective by considering only visual context, which may trigger unpredictable results which are plausible but not faithful to a grounded knowledge. To permit both grounded and controllable completion process, we advocate generating results faithful to both visual and lexical semantic context, i.e., the description of leaving holes or blank regions in the image (e.g., hole description). One major challenge for LSIC comes from modeling and aligning the structure of visual-semantic context and translating across different modalities. We term this process as structure completion, which is realized by multi-grained reasoning blocks in our model. Another challenge relates to the unimodal biases, which occurs when the model generates plausible results without using the textual description. This can be true since the annotated captions for an image are often semantically equivalent in existing datasets, and thus there is only one paired text for a masked image in training. We devise an unsupervised unpaired-creation learning path besides the over-explored paired-reconstruction path, as well as a multi-stage training strategy to mitigate the insufficiency of labeled data. We conduct extensive quantitative and qualitative experiments as well as ablation studies, which reveal the efficacy of our proposed LSIC.