 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory Planning for UAV-Based Smart Farming Using Imitation-Based Triple Deep Q-Learning
Dec 21, 2025Unmanned aerial vehicles (UAVs) have emerged as a promising auxiliary platform for smart agriculture, capable of simultaneously performing weed detection, recognition, and data collection from wireless sensors. However, trajectory planning for UAV-based smart agriculture is challenging due to the high uncertainty of the environment, partial observations, and limited battery capacity of UAVs. To address these issues, we formulate the trajectory planning problem as a Markov decision process (MDP) and leverage multi-agent reinforcement learning (MARL) to solve it. Furthermore, we propose a novel imitation-based triple deep Q-network (ITDQN) algorithm, which employs an elite imitation mechanism to reduce exploration costs and utilizes a mediator Q-network over a double deep Q-network (DDQN) to accelerate and stabilize training and improve performance. Experimental results in both simulated and real-world environments demonstrate the effectiveness of our solution. Moreover, our proposed ITDQN outperforms DDQN by 4.43\% in weed recognition rate and 6.94\% in data collection rate.
FM-EAC: Feature Model-based Enhanced Actor-Critic for Multi-Task Control in Dynamic Environments
Dec 17, 2025Model-based reinforcement learning (MBRL) and model-free reinforcement learning (MFRL) evolve along distinct paths but converge in the design of Dyna-Q [1]. However, modern RL methods still struggle with effective transferability across tasks and scenarios. Motivated by this limitation, we propose a generalized algorithm, Feature Model-Based Enhanced Actor-Critic (FM-EAC), that integrates planning, acting, and learning for multi-task control in dynamic environments. FM-EAC combines the strengths of MBRL and MFRL and improves generalizability through the use of novel feature-based models and an enhanced actor-critic framework. Simulations in both urban and agricultural applications demonstrate that FM-EAC consistently outperforms many state-of-the-art MBRL and MFRL methods. More importantly, different sub-networks can be customized within FM-EAC according to user-specific requirements.
Communication and Control Co-Design in 6G: Sequential Decision-Making with LLMs
Jul 06, 2024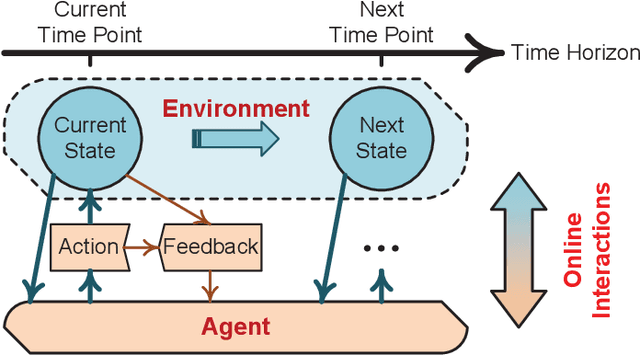
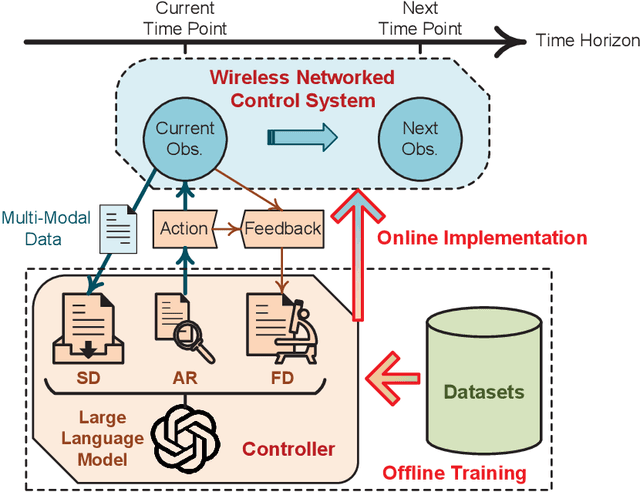
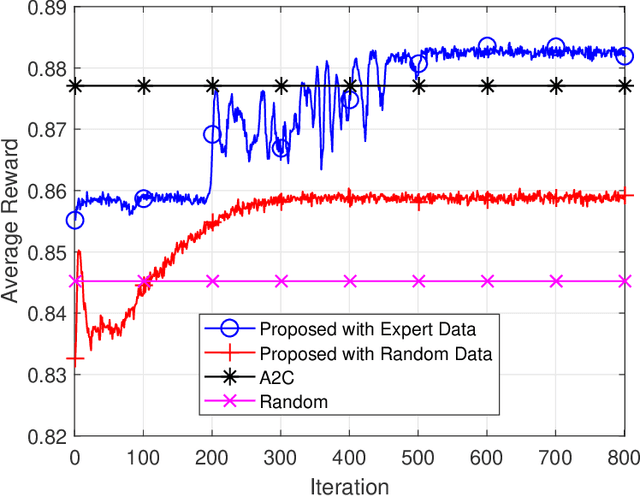
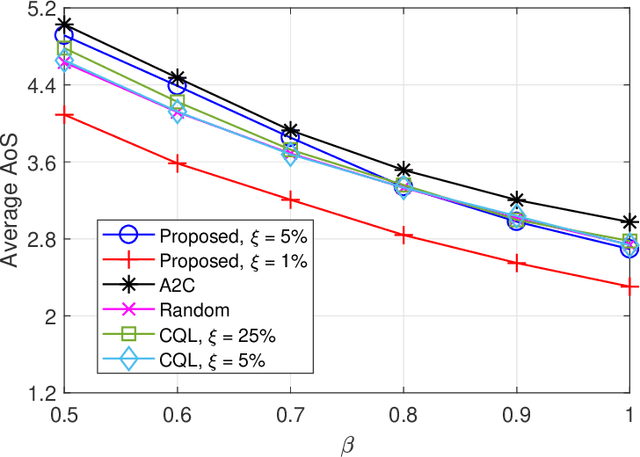
This article investigates a control system within the context of six-generation wireless networks. The control performance optimization confronts the technical challenges that arise from the intricate interactions between communication and control sub-systems, asking for a co-design. Accounting for the system dynamics, we formulate the sequential co-design decision-makings of communication and control over the discrete time horizon as a Markov decision process, for which a practical offline learning framework is proposed. Our proposed framework integrates large language models into the elements of reinforcement learning. We present a case study on the age of semantics-aware communication and control co-design to showcase the potentials from our proposed learning framework. Furthermore, we discuss the open issues remaining to make our proposed offline learning framework feasible for real-world implementations, and highlight the research directions for future explorations.
Know in AdVance: Linear-Complexity Forecasting of Ad Campaign Performance with Evolving User Interest
May 17, 2024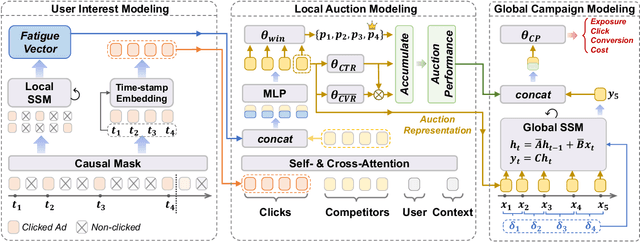
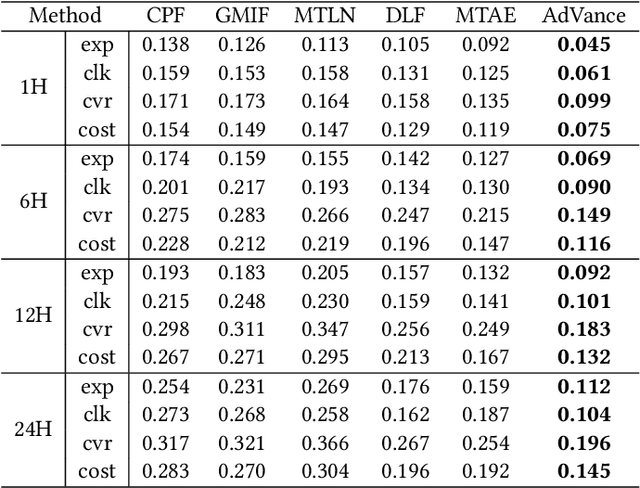
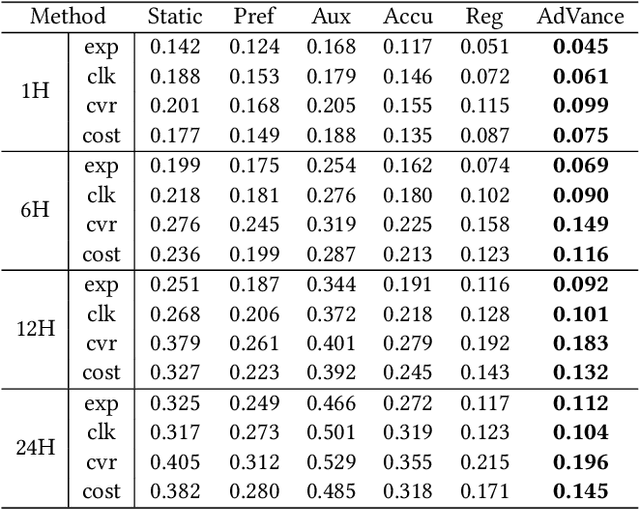
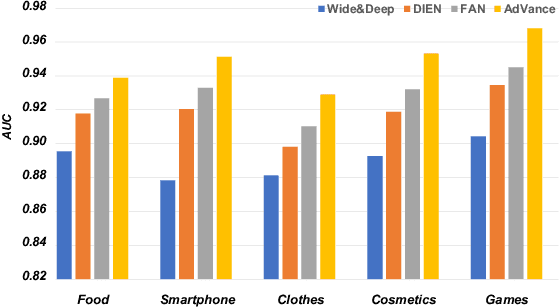
Real-time Bidding (RTB) advertisers wish to \textit{know in advance} the expected cost and yield of ad campaigns to avoid trial-and-error expenses. However, Campaign Performance Forecasting (CPF), a sequence modeling task involving tens of thousands of ad auctions, poses challenges of evolving user interest, auction representation, and long context, making coarse-grained and static-modeling methods sub-optimal. We propose \textit{AdVance}, a time-aware framework that integrates local auction-level and global campaign-level modeling. User preference and fatigue are disentangled using a time-positioned sequence of clicked items and a concise vector of all displayed items. Cross-attention, conditioned on the fatigue vector, captures the dynamics of user interest toward each candidate ad. Bidders compete with each other, presenting a complete graph similar to the self-attention mechanism. Hence, we employ a Transformer Encoder to compress each auction into embedding by solving auxiliary tasks. These sequential embeddings are then summarized by a conditional state space model (SSM) to comprehend long-range dependencies while maintaining global linear complexity. Considering the irregular time intervals between auctions, we make SSM's parameters dependent on the current auction embedding and the time interval. We further condition SSM's global predictions on the accumulation of local results. Extensive evaluations and ablation studies demonstrate its superiority over state-of-the-art methods. AdVance has been deployed on the Tencent Advertising platform, and A/B tests show a remarkable 4.5\% uplift in Average Revenue per User (ARPU).
ReSup: Reliable Label Noise Suppression for Facial Expression Recognition
May 29, 2023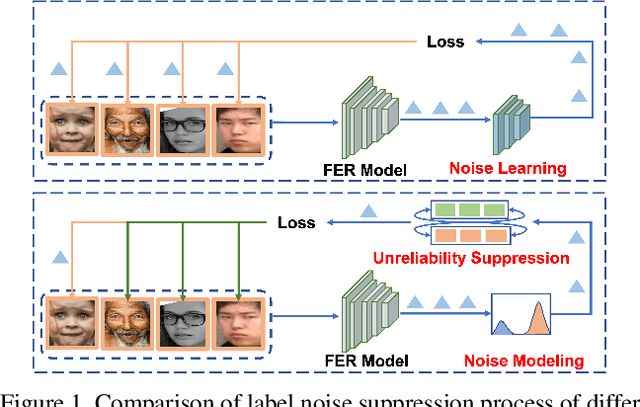
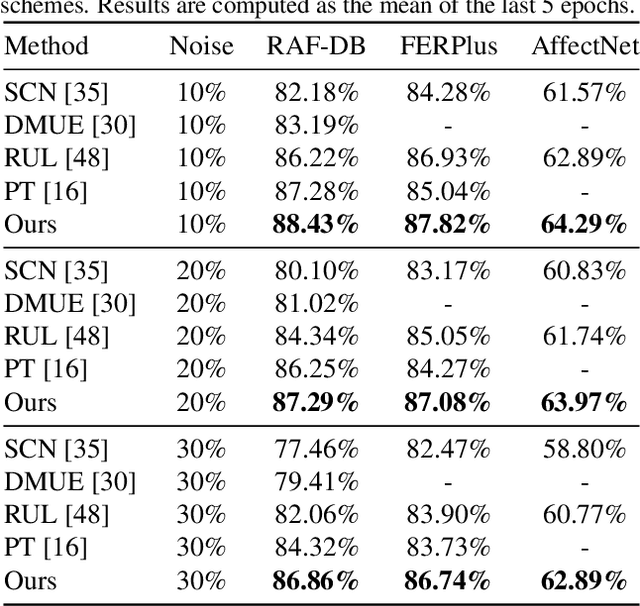
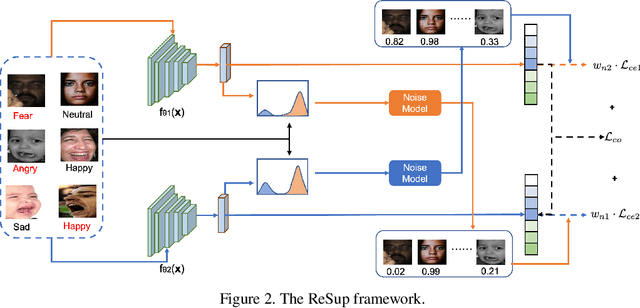
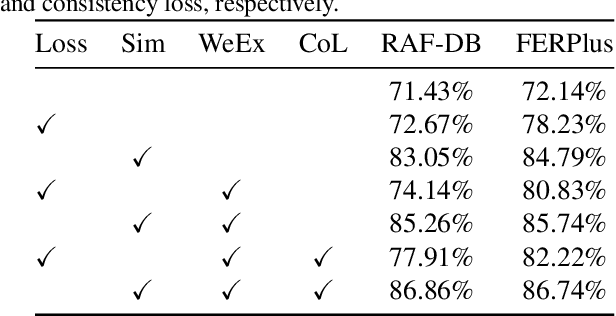
Because of the ambiguous and subjective property of the facial expression recognition (FER) task, the label noise is widely existing in the FER dataset. For this problem, in the training phase, current FER methods often directly predict whether the label of the input image is noised or not, aiming to reduce the contribution of the noised data in training. However, we argue that this kind of method suffers from the low reliability of such noise data decision operation. It makes that some mistakenly abounded clean data are not utilized sufficiently and some mistakenly kept noised data disturbing the model learning process. In this paper, we propose a more reliable noise-label suppression method called ReSup (Reliable label noise Suppression for FER). First, instead of directly predicting noised or not, ReSup makes the noise data decision by modeling the distribution of noise and clean labels simultaneously according to the disagreement between the prediction and the target. Specifically, to achieve optimal distribution modeling, ReSup models the similarity distribution of all samples. To further enhance the reliability of our noise decision results, ReSup uses two networks to jointly achieve noise suppression. Specifically, ReSup utilize the property that two networks are less likely to make the same mistakes, making two networks swap decisions and tending to trust decisions with high agreement. Extensive experiments on three popular benchmarks show that the proposed method significantly outperforms state-of-the-art noisy label FER methods by 3.01% on FERPlus becnmarks. Code: https://github.com/purpleleaves007/FERDenoise
TinyQMIX: Distributed Access Control for mMTC via Multi-agent Reinforcement Learning
Nov 21, 2022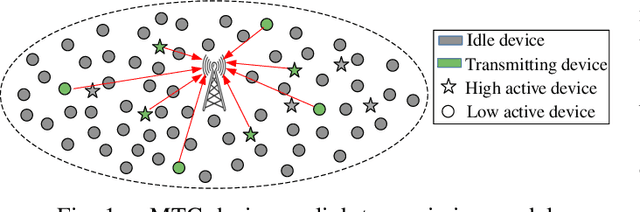
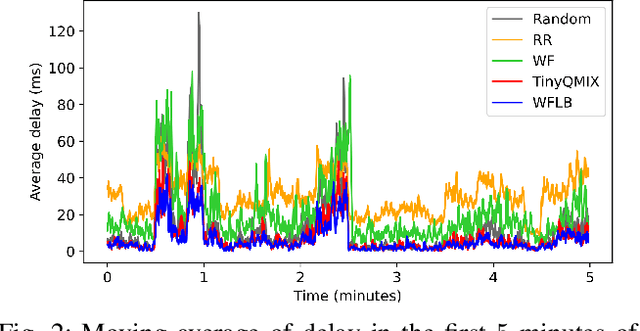
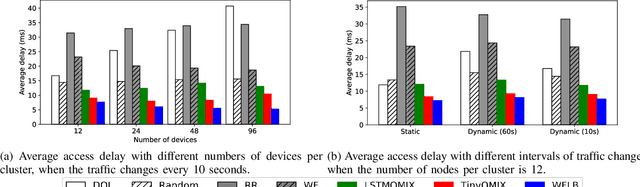
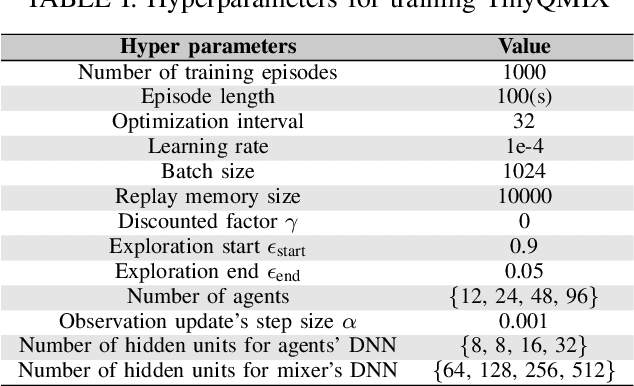
Distributed access control is a crucial component for massive machine type communication (mMTC). In this communication scenario, centralized resource allocation is not scalable because resource configurations have to be sent frequently from the base station to a massive number of devices. We investigate distributed reinforcement learning for resource selection without relying on centralized control. Another important feature of mMTC is the sporadic and dynamic change of traffic. Existing studies on distributed access control assume that traffic load is static or they are able to gradually adapt to the dynamic traffic. We minimize the adaptation period by training TinyQMIX, which is a lightweight multi-agent deep reinforcement learning model, to learn a distributed wireless resource selection policy under various traffic patterns before deployment. Therefore, the trained agents are able to quickly adapt to dynamic traffic and provide low access delay. Numerical results are presented to support our claims.
Information Freshness-Aware Task Offloading in Air-Ground Integrated Edge Computing Systems
Jul 15, 2020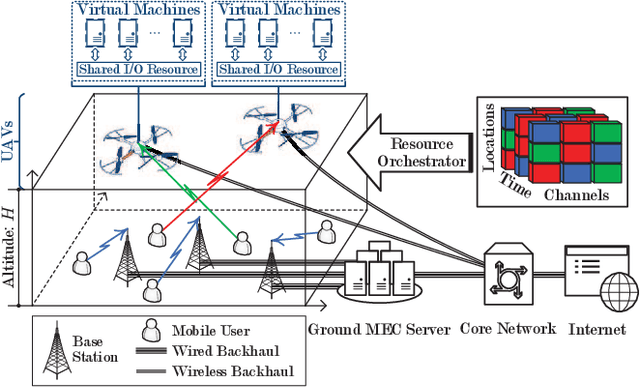
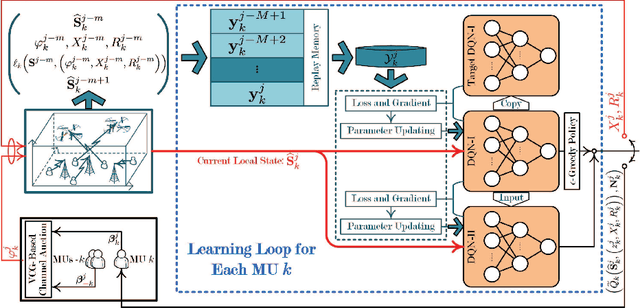
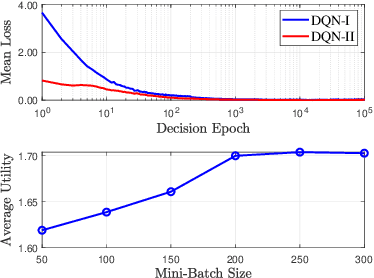
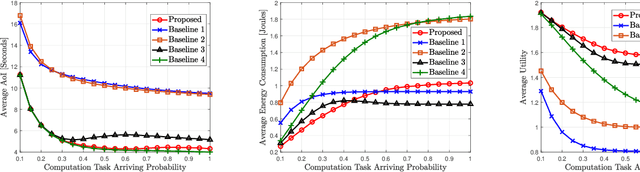
This paper studies the problem of information freshness-aware task offloading in an air-ground integrated multi-access edge computing system, which is deployed by an infrastructure provider (InP). A third-party real-time application service provider provides computing services to the subscribed mobile users (MUs) with the limited communication and computation resources from the InP based on a long-term business agreement. Due to the dynamic characteristics, the interactions among the MUs are modelled by a non-cooperative stochastic game, in which the control policies are coupled and each MU aims to selfishly maximize its own expected long-term payoff. To address the Nash equilibrium solutions, we propose that each MU behaves in accordance with the local system states and conjectures, based on which the stochastic game is transformed into a single-agent Markov decision process. Moreover, we derive a novel online deep reinforcement learning (RL) scheme that adopts two separate double deep Q-networks for each MU to approximate the Q-factor and the post-decision Q-factor. Using the proposed deep RL scheme, each MU in the system is able to make decisions without a priori statistical knowledge of dynamics. Numerical experiments examine the potentials of the proposed scheme in balancing the age of information and the energy consumption.
Computation Offloading in Beyond 5G Networks: A Distributed Learning Framework and Applications
Jul 15, 2020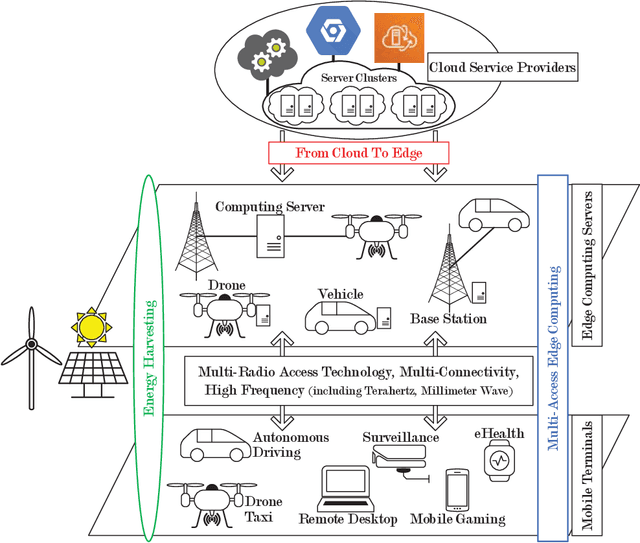
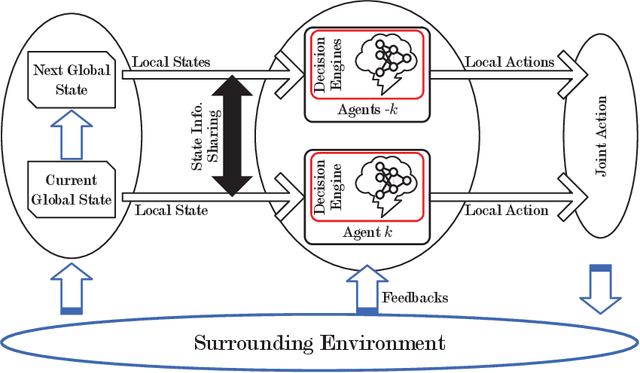
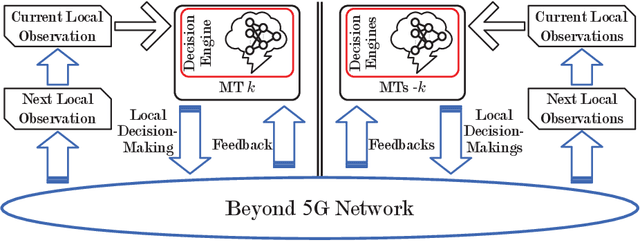
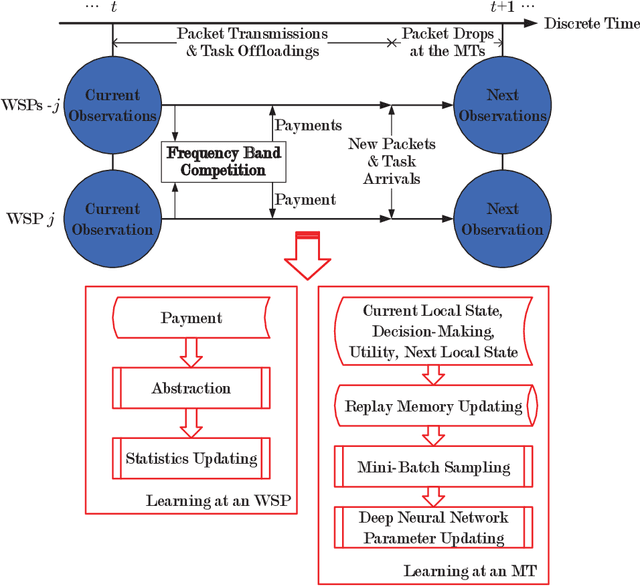
Facing the trend of merging wireless communications and multi-access edge computing (MEC), this article studies computation offloading in the beyond fifth-generation networks. To address the technical challenges originating from the uncertainties and the sharing of limited resource in an MEC system, we formulate the computation offloading problem as a multi-agent Markov decision process, for which a distributed learning framework is proposed. We present a case study on resource orchestration in computation offloading to showcase the potentials of an online distributed reinforcement learning algorithm developed under the proposed framework. Experimental results demonstrate that our learning algorithm outperforms the benchmark resource orchestration algorithms. Furthermore, we outline the research directions worth in-depth investigation to minimize the time cost, which is one of the main practical issues that prevent the implementation of the proposed distributed learning framework.
Understanding the Modeling of Computer Network Delays using Neural Networks
Jul 23, 2018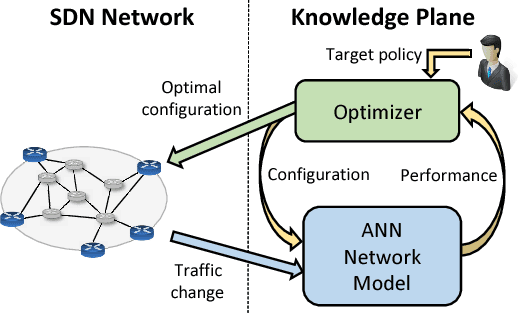
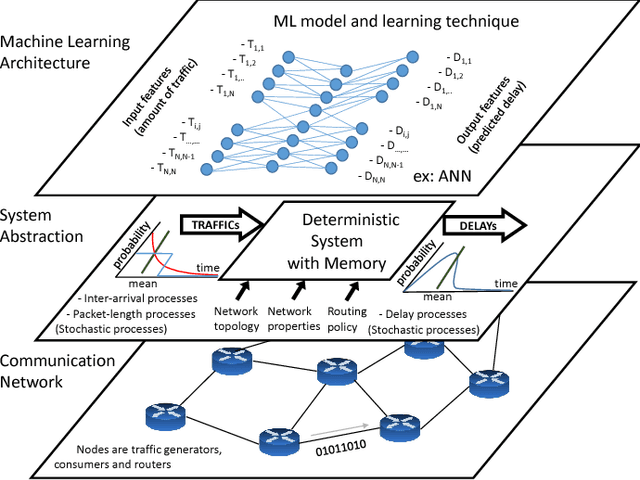
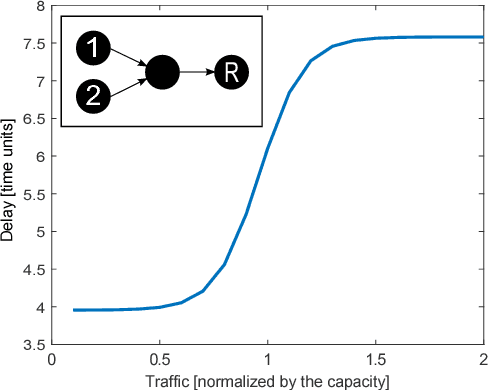
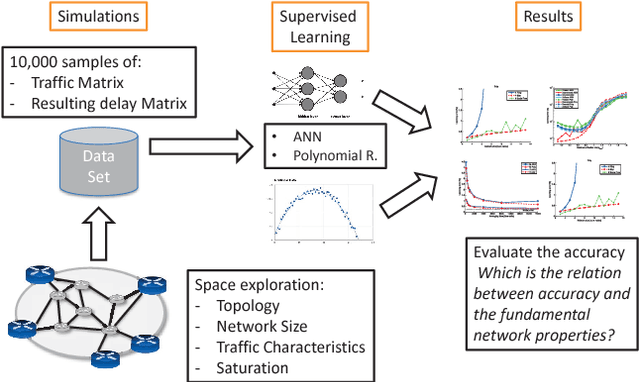
Recent trends in networking are proposing the use of Machine Learning (ML) techniques for the control and operation of the network. In this context, ML can be used as a computer network modeling technique to build models that estimate the network performance. Indeed, network modeling is a central technique to many networking functions, for instance in the field of optimization, in which the model is used to search a configuration that satisfies the target policy. In this paper, we aim to provide an answer to the following question: Can neural networks accurately model the delay of a computer network as a function of the input traffic? For this, we assume the network as a black-box that has as input a traffic matrix and as output delays. Then we train different neural networks models and evaluate its accuracy under different fundamental network characteristics: topology, size, traffic intensity and routing. With this, we aim to have a better understanding of computer network modeling with neural nets and ultimately provide practical guidelines on how such models need to be trained.
Optimized Computation Offloading Performance in Virtual Edge Computing Systems via Deep Reinforcement Learning
May 16, 2018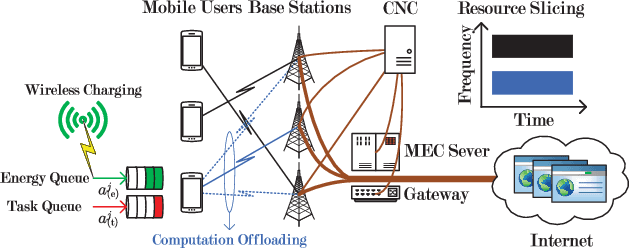
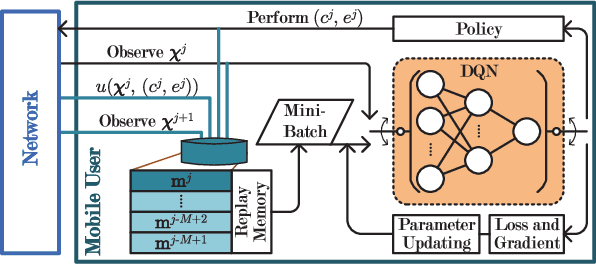
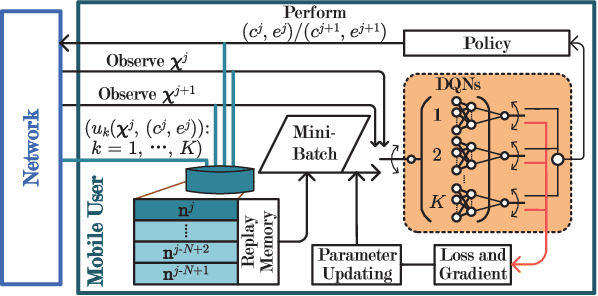
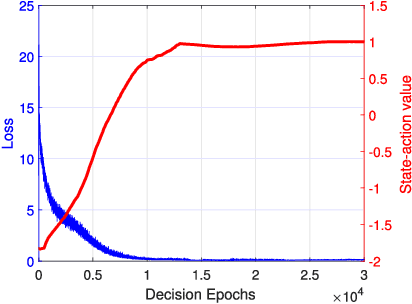
To improve the quality of computation experience for mobile devices, mobile-edge computing (MEC) is a promising paradigm by providing computing capabilities in close proximity within a sliced radio access network (RAN), which supports both traditional communication and MEC services. Nevertheless, the design of computation offloading policies for a virtual MEC system remains challenging. Specifically, whether to execute a computation task at the mobile device or to offload it for MEC server execution should adapt to the time-varying network dynamics. In this paper, we consider MEC for a representative mobile user in an ultra-dense sliced RAN, where multiple base stations (BSs) are available to be selected for computation offloading. The problem of solving an optimal computation offloading policy is modelled as a Markov decision process, where our objective is to maximize the long-term utility performance whereby an offloading decision is made based on the task queue state, the energy queue state as well as the channel qualities between MU and BSs. To break the curse of high dimensionality in state space, we first propose a double deep Q-network (DQN) based strategic computation offloading algorithm to learn the optimal policy without knowing a priori knowledge of network dynamics. Then motivated by the additive structure of the utility function, a Q-function decomposition technique is combined with the double DQN, which leads to novel learning algorithm for the solving of stochastic computation offloading. Numerical experiments show that our proposed learning algorithms achieve a significant improvement in computation offloading performance compared with the baseline policies.