 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication and Control Co-Design in 6G: Sequential Decision-Making with LLMs
Paper and Code
Jul 06, 2024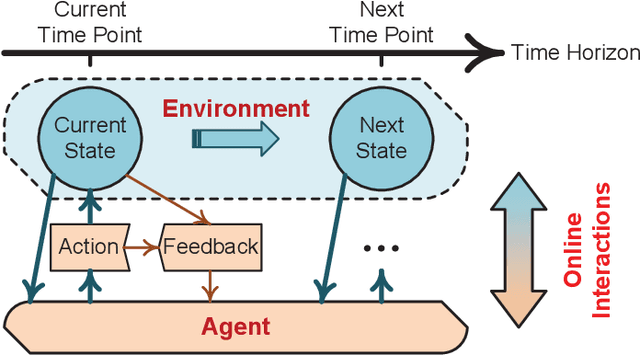
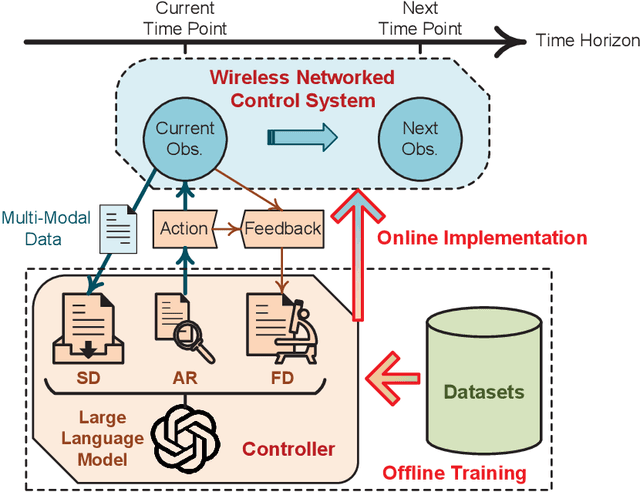
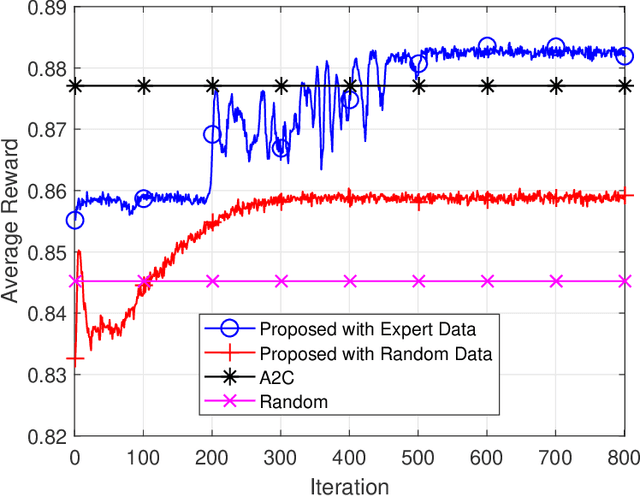
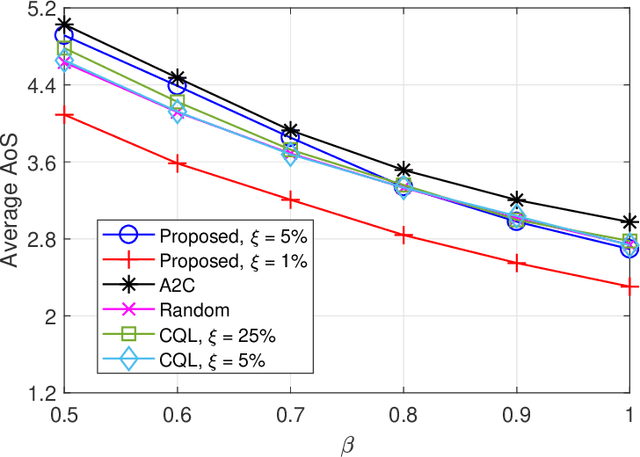
This article investigates a control system within the context of six-generation wireless networks. The control performance optimization confronts the technical challenges that arise from the intricate interactions between communication and control sub-systems, asking for a co-design. Accounting for the system dynamics, we formulate the sequential co-design decision-makings of communication and control over the discrete time horizon as a Markov decision process, for which a practical offline learning framework is proposed. Our proposed framework integrates large language models into the elements of reinforcement learning. We present a case study on the age of semantics-aware communication and control co-design to showcase the potentials from our proposed learning framework. Furthermore, we discuss the open issues remaining to make our proposed offline learning framework feasible for real-world implementations, and highlight the research directions for future explorations.