 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiNGR: Generalized Iterative Non-Rigid Point Cloud and Surface Registration Using Gaussian Process Regression
Mar 18, 2022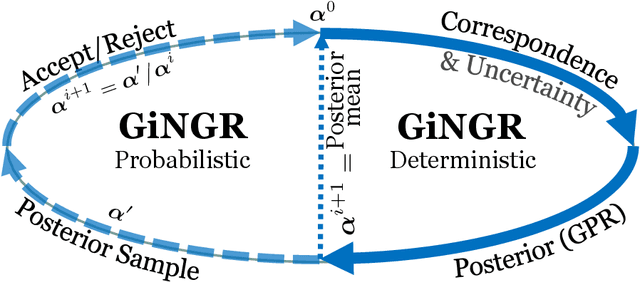



In this paper, we unify popular non-rigid registration methods for point sets and surfaces under our general framework, GiNGR. GiNGR builds upon Gaussian Process Morphable Models (GPMM) and hence separates modeling the deformation prior from model adaptation for registration. In addition, it provides explainable hyperparameters, multi-resolution registration, trivial inclusion of expert annotation, and the ability to use and combine analytical and statistical deformation priors. But more importantly, the reformulation allows for a direct comparison of registration methods. Instead of using a general solver in the optimization step, we show how Gaussian process regression (GPR) iteratively can warp a reference onto a target, leading to smooth deformations following the prior for any dense, sparse, or partial estimated correspondences in a principled way. We show how the popular CPD and ICP algorithms can be directly explained with GiNGR. Furthermore, we show how existing algorithms in the GiNGR framework can perform probabilistic registration to obtain a distribution of different registrations instead of a single best registration. This can be used to analyze the uncertainty e.g. when registering partial observations. GiNGR is publicly available and fully modular to allow for domain-specific prior construction.
To fit or not to fit: Model-based Face Reconstruction and Occlusion Segmentation from Weak Supervision
Jun 17, 2021



3D face reconstruction from a single image is challenging due to its ill-posed nature. Model-based face autoencoders address this issue effectively by fitting a face model to the target image in a weakly supervised manner. However, in unconstrained environments occlusions distort the face reconstruction because the model often erroneously tries to adapt to occluded face regions. Supervised occlusion segmentation is a viable solution to avoid the fitting of occluded face regions, but it requires a large amount of annotated training data. In this work, we enable model-based face autoencoders to segment occluders accurately without requiring any additional supervision during training, and this separates regions where the model will be fitted from those where it will not be fitted. To achieve this, we extend face autoencoders with a segmentation network. The segmentation network decides which regions the model should adapt to by reaching balances in a trade-off between including pixels and adapting the model to them, and excluding pixels so that the model fitting is not negatively affected and reaches higher overall reconstruction accuracy on pixels showing the face. This leads to a synergistic effect, in which the occlusion segmentation guides the training of the face autoencoder to constrain the fitting in the non-occluded regions, while the improved fitting enables the segmentation model to better predict the occluded face regions. Qualitative and quantitative experiments on the CelebA-HQ database and the AR database verify the effectiveness of our model in improving 3D face reconstruction under occlusions and in enabling accurate occlusion segmentation from weak supervision only. Code available at https://github.com/unibas-gravis/Occlusion-Robust-MoFA.
3D Morphable Face Models -- Past, Present and Future
Sep 03, 2019
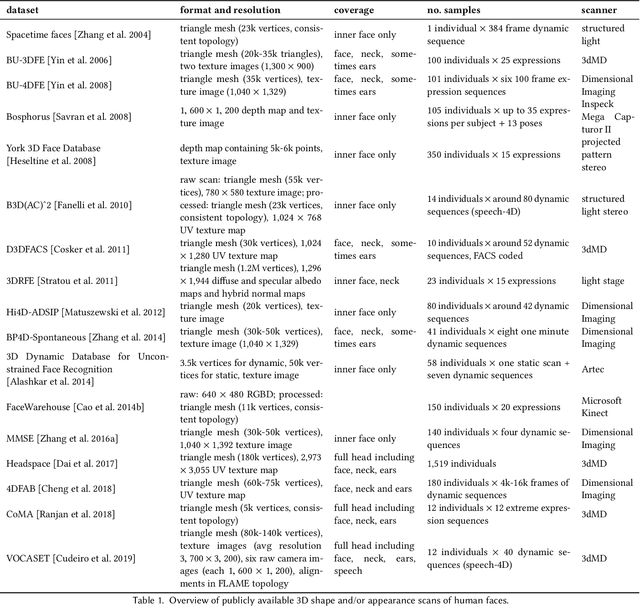
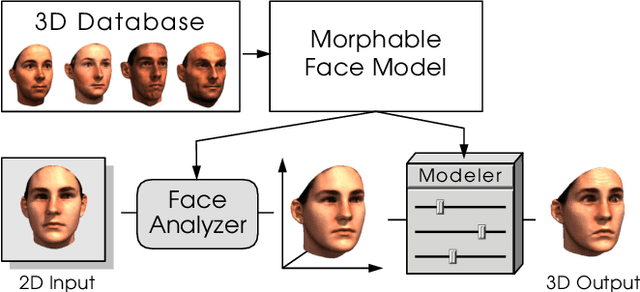
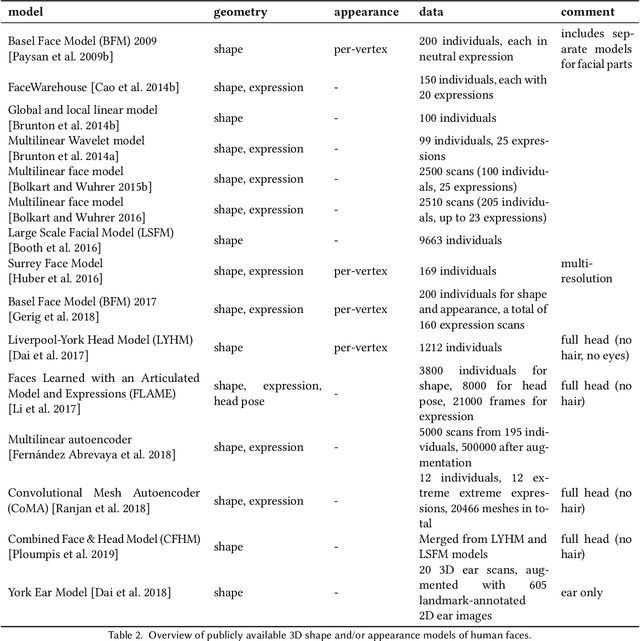
In this paper, we provide a detailed survey of 3D Morphable Face Models over the 20 years since they were first proposed. The challenges in building and applying these models, namely capture, modeling, image formation, and image analysis, are still active research topics, and we review the state-of-the-art in each of these areas. We also look ahead, identifying unsolved challenges, proposing directions for future research and highlighting the broad range of current and future applications.
A Closest Point Proposal for MCMC-based Probabilistic Surface Registration
Jul 02, 2019



In this paper, we propose a non-rigid surface registration algorithm that estimates the correspondence uncertainty using the Markov-chain Monte Carlo (MCMC) framework. The estimated uncertainty of the inferred registration is important for many applications, such as surgical planning or missing data reconstruction. The used Metropolis-Hastings (MH) algorithm decouples the inference from modelling the posterior using a propose-and-verify scheme. The widely used random sampling strategy leads to slow convergence rates in high dimensional space. In order to overcome this limitation, we introduce an informed probabilistic proposal based on ICP that can be used within the MH algorithm. While the ICP algorithm is used in the inference algorithm, the likelihood can be chosen independently. We showcase different surface distance measures, such as the traditional Euclidean norm and the Hausdorff distance. While quantifying the uncertainty of the correspondence, we also experimentally verify that our method is more robust than the non-rigid ICP algorithm and provides more accurate surface registrations. In a reconstruction task, we show how our probabilistic framework can be used to estimate the posterior distribution of missing data without assuming a fixed point-to-point correspondence. We have made our registration framework publicly available for the community.
Informed MCMC with Bayesian Neural Networks for Facial Image Analysis
Nov 29, 2018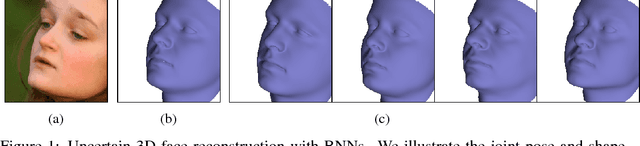
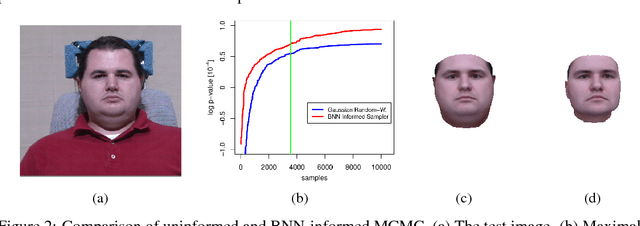
Computer vision tasks are difficult because of the large variability in the data that is induced by changes in light, background, partial occlusion as well as the varying pose, texture, and shape of objects. Generative approaches to computer vision allow us to overcome this difficulty by explicitly modeling the physical image formation process. Using generative object models, the analysis of an observed image is performed via Bayesian inference of the posterior distribution. This conceptually simple approach tends to fail in practice because of several difficulties stemming from sampling the posterior distribution: high-dimensionality and multi-modality of the posterior distribution as well as expensive simulation of the rendering process. The main difficulty of sampling approaches in a computer vision context is choosing the proposal distribution accurately so that maxima of the posterior are explored early and the algorithm quickly converges to a valid image interpretation. In this work, we propose to use a Bayesian Neural Network for estimating an image dependent proposal distribution. Compared to a standard Gaussian random walk proposal, this accelerates the sampler in finding regions of the posterior with high value. In this way, we can significantly reduce the number of samples needed to perform facial image analysis.
Priming Deep Neural Networks with Synthetic Faces for Enhanced Performance
Nov 19, 2018
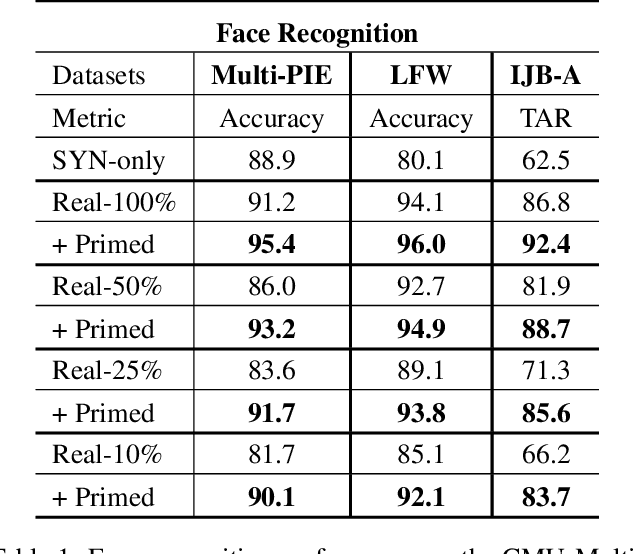
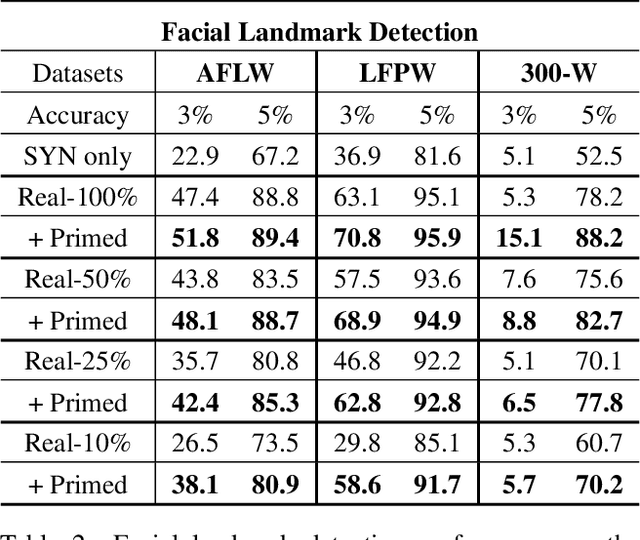
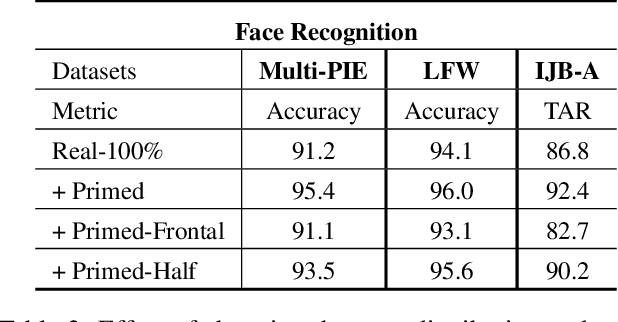
Today's most successful facial image analysis systems are based on deep neural networks. However, a major limitation of such deep learning approaches is that their performance depends strongly on the availability of large annotated datasets. In this work, we prime deep neural networks by pre-training them with synthetic face images for specific facial analysis tasks. We demonstrate that this approach enhances both the generalization performance as well as the dataset efficiency of deep neural networks. Using a 3D morphable face model, we generate arbitrary amounts of annotated data with full control over image characteristics such as facial shape and color, pose, illumination, and background. With a series of experiments, we extensively test the effect of priming deep neural networks with synthetic face examples for two popular facial image analysis tasks: face recognition and facial landmark detection. We observed the following positive effects for both tasks: 1) Priming with synthetic face images improves the generalization performance consistently across all benchmark datasets. 2) The amount of real-world data needed to achieve competitive performance is reduced by 75% for face recognition and by 50% for facial landmark detection. 3) Priming with synthetic faces is consistently superior at enhancing the performance of deep neural networks than data augmentation and transfer learning techniques. Furthermore, our experiments provide evidence that priming with synthetic faces is able to enhance performance because it reduces the negative effects of biases present in real-world training data. The proposed synthetic face image generator, as well as the software used for our experiments, have been made publicly available.
Greedy Structure Learning of Hierarchical Compositional Models
May 29, 2018

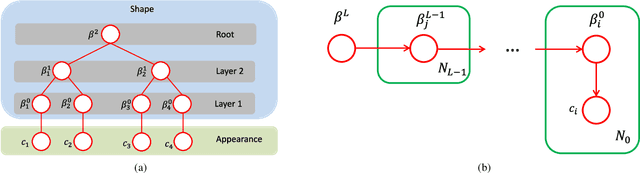
Learning the representation of an object in terms of individual parts and their spatial as well as hierarchical relation is a fundamental problem of vision. Existing approaches are limited by the need of segmented training data and prior knowledge of the object's geometry. In this paper, we overcome those limitations by integrating an explicit background model into the structure learning process. We formulate the structure learning as a hierarchical clustering process. Thereby, we iterate in an EM-type procedure between clustering image patches and using the clustered data for learning part models. The hierarchical clustering proceeds in a bottom-up manner, learning the parts of lower layers in the hierarchy first and subsequently composing them into higher-order parts. A final top-down process composes the learned hierarchical parts into a holistic object model. The key novelty of our approach is that we learn a background model that competes with the object model (the foreground) in explaining the training data. In this way, we integrate the foreground-background segmentation task into the structure learning process and therefore overcome the need for segmented training data. As a result, we can infer the number of layers in the hierarchy, the number of parts per layer and the foreground-background segmentation in a joint optimization process. We demonstrate the ability to learn semantically meaningful hierarchical compositional models from a small set of natural images of an object without detailed supervision. We show that the learned object models achieve state-of-the-art results when compared with other generative object models at object classification on a standard transfer learning dataset. The code and data used in this work are publicly available.
Empirically Analyzing the Effect of Dataset Biases on Deep Face Recognition Systems
Apr 19, 2018



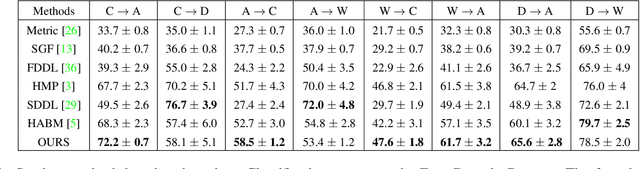
It is unknown what kind of biases modern in the wild face datasets have because of their lack of annotation. A direct consequence of this is that total recognition rates alone only provide limited insight about the generalization ability of a Deep Convolutional Neural Networks (DCNNs). We propose to empirically study the effect of different types of dataset biases on the generalization ability of DCNNs. Using synthetically generated face images, we study the face recognition rate as a function of interpretable parameters such as face pose and light. The proposed method allows valuable details about the generalization performance of different DCNN architectures to be observed and compared. In our experiments, we find that: 1) Indeed, dataset bias has a significant influence on the generalization performance of DCNNs. 2) DCNNs can generalize surprisingly well to unseen illumination conditions and large sampling gaps in the pose variation. 3) Using the presented methodology we reveal that the VGG-16 architecture outperforms the AlexNet architecture at face recognition tasks because it can much better generalize to unseen face poses, although it has significantly more parameters. 4) We uncover a main limitation of current DCNN architectures, which is the difficulty to generalize when different identities to not share the same pose variation. 5) We demonstrate that our findings on synthetic data also apply when learning from real-world data. Our face image generator is publicly available to enable the community to benchmark other DCNN architectures.
Training Deep Face Recognition Systems with Synthetic Data
Feb 16, 2018
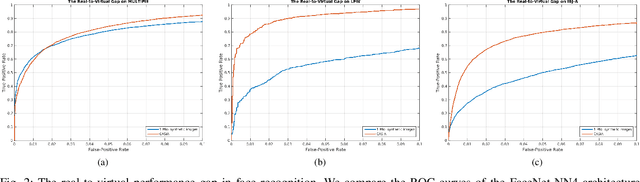
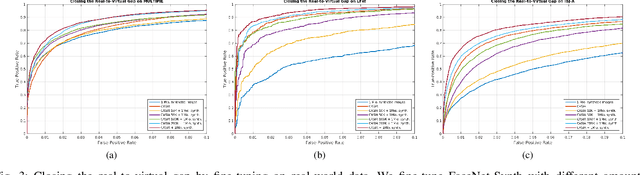
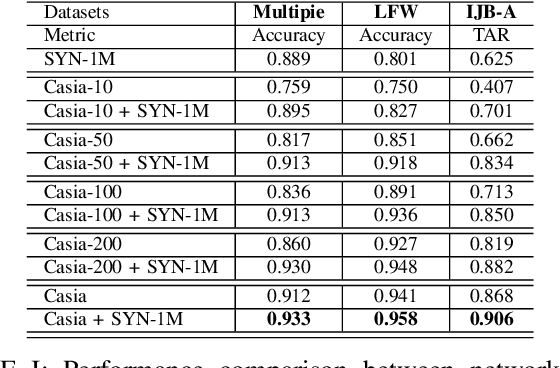
Recent advances in deep learning have significantly increased the performance of face recognition systems. The performance and reliability of these models depend heavily on the amount and quality of the training data. However, the collection of annotated large datasets does not scale well and the control over the quality of the data decreases with the size of the dataset. In this work, we explore how synthetically generated data can be used to decrease the number of real-world images needed for training deep face recognition systems. In particular, we make use of a 3D morphable face model for the generation of images with arbitrary amounts of facial identities and with full control over image variations, such as pose, illumination, and background. In our experiments with an off-the-shelf face recognition software we observe the following phenomena: 1) The amount of real training data needed to train competitive deep face recognition systems can be reduced significantly. 2) Combining large-scale real-world data with synthetic data leads to an increased performance. 3) Models trained only on synthetic data with strong variations in pose, illumination, and background perform very well across different datasets even without dataset adaptation. 4) The real-to-virtual performance gap can be closed when using synthetic data for pre-training, followed by fine-tuning with real-world images. 5) There are no observable negative effects of pre-training with synthetic data. Thus, any face recognition system in our experiments benefits from using synthetic face images. The synthetic data generator, as well as all experiments, are publicly available.
Morphable Face Models - An Open Framework
Sep 26, 2017

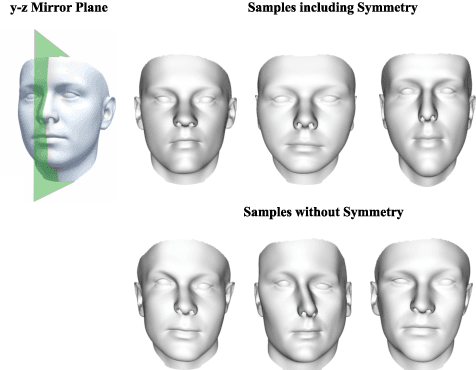

In this paper, we present a novel open-source pipeline for face registration based on Gaussian processes as well as an application to face image analysis. Non-rigid registration of faces is significant for many applications in computer vision, such as the construction of 3D Morphable face models (3DMMs). Gaussian Process Morphable Models (GPMMs) unify a variety of non-rigid deformation models with B-splines and PCA models as examples. GPMM separate problem specific requirements from the registration algorithm by incorporating domain-specific adaptions as a prior model. The novelties of this paper are the following: (i) We present a strategy and modeling technique for face registration that considers symmetry, multi-scale and spatially-varying details. The registration is applied to neutral faces and facial expressions. (ii) We release an open-source software framework for registration and model-building, demonstrated on the publicly available BU3D-FE database. The released pipeline also contains an implementation of an Analysis-by-Synthesis model adaption of 2D face images, tested on the Multi-PIE and LFW database. This enables the community to reproduce, evaluate and compare the individual steps of registration to model-building and 3D/2D model fitting. (iii) Along with the framework release, we publish a new version of the Basel Face Model (BFM-2017) with an improved age distribution and an additional facial expression model.