 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriming Deep Neural Networks with Synthetic Faces for Enhanced Performance
Nov 19, 2018
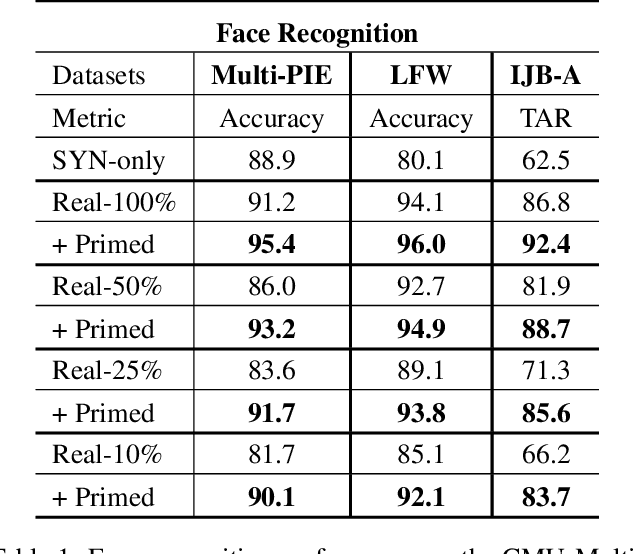
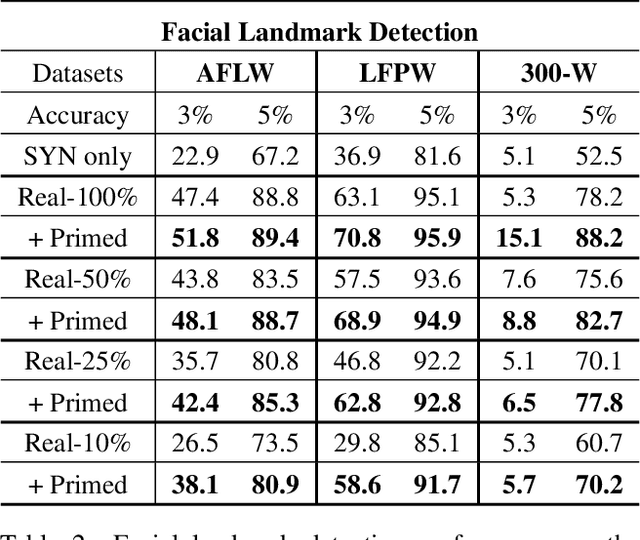
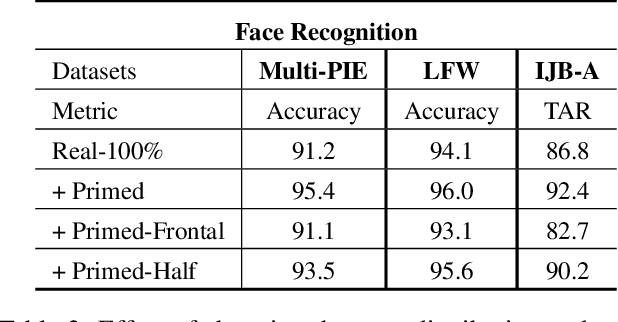
Today's most successful facial image analysis systems are based on deep neural networks. However, a major limitation of such deep learning approaches is that their performance depends strongly on the availability of large annotated datasets. In this work, we prime deep neural networks by pre-training them with synthetic face images for specific facial analysis tasks. We demonstrate that this approach enhances both the generalization performance as well as the dataset efficiency of deep neural networks. Using a 3D morphable face model, we generate arbitrary amounts of annotated data with full control over image characteristics such as facial shape and color, pose, illumination, and background. With a series of experiments, we extensively test the effect of priming deep neural networks with synthetic face examples for two popular facial image analysis tasks: face recognition and facial landmark detection. We observed the following positive effects for both tasks: 1) Priming with synthetic face images improves the generalization performance consistently across all benchmark datasets. 2) The amount of real-world data needed to achieve competitive performance is reduced by 75% for face recognition and by 50% for facial landmark detection. 3) Priming with synthetic faces is consistently superior at enhancing the performance of deep neural networks than data augmentation and transfer learning techniques. Furthermore, our experiments provide evidence that priming with synthetic faces is able to enhance performance because it reduces the negative effects of biases present in real-world training data. The proposed synthetic face image generator, as well as the software used for our experiments, have been made publicly available.
Empirically Analyzing the Effect of Dataset Biases on Deep Face Recognition Systems
Apr 19, 2018



It is unknown what kind of biases modern in the wild face datasets have because of their lack of annotation. A direct consequence of this is that total recognition rates alone only provide limited insight about the generalization ability of a Deep Convolutional Neural Networks (DCNNs). We propose to empirically study the effect of different types of dataset biases on the generalization ability of DCNNs. Using synthetically generated face images, we study the face recognition rate as a function of interpretable parameters such as face pose and light. The proposed method allows valuable details about the generalization performance of different DCNN architectures to be observed and compared. In our experiments, we find that: 1) Indeed, dataset bias has a significant influence on the generalization performance of DCNNs. 2) DCNNs can generalize surprisingly well to unseen illumination conditions and large sampling gaps in the pose variation. 3) Using the presented methodology we reveal that the VGG-16 architecture outperforms the AlexNet architecture at face recognition tasks because it can much better generalize to unseen face poses, although it has significantly more parameters. 4) We uncover a main limitation of current DCNN architectures, which is the difficulty to generalize when different identities to not share the same pose variation. 5) We demonstrate that our findings on synthetic data also apply when learning from real-world data. Our face image generator is publicly available to enable the community to benchmark other DCNN architectures.
Training Deep Face Recognition Systems with Synthetic Data
Feb 16, 2018
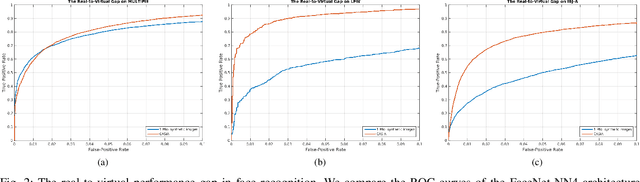
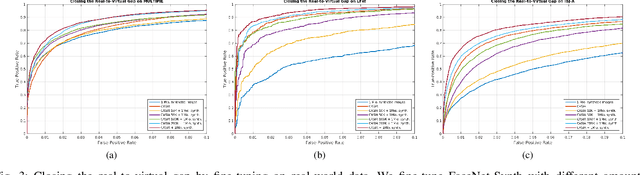
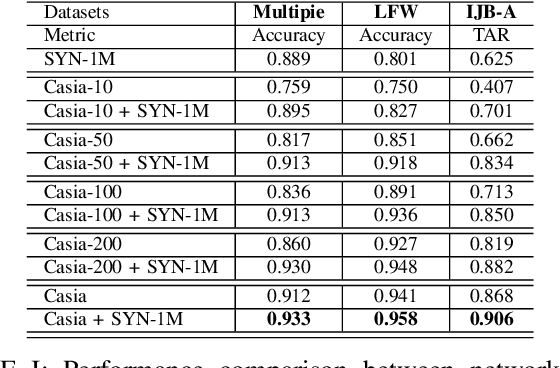
Recent advances in deep learning have significantly increased the performance of face recognition systems. The performance and reliability of these models depend heavily on the amount and quality of the training data. However, the collection of annotated large datasets does not scale well and the control over the quality of the data decreases with the size of the dataset. In this work, we explore how synthetically generated data can be used to decrease the number of real-world images needed for training deep face recognition systems. In particular, we make use of a 3D morphable face model for the generation of images with arbitrary amounts of facial identities and with full control over image variations, such as pose, illumination, and background. In our experiments with an off-the-shelf face recognition software we observe the following phenomena: 1) The amount of real training data needed to train competitive deep face recognition systems can be reduced significantly. 2) Combining large-scale real-world data with synthetic data leads to an increased performance. 3) Models trained only on synthetic data with strong variations in pose, illumination, and background perform very well across different datasets even without dataset adaptation. 4) The real-to-virtual performance gap can be closed when using synthetic data for pre-training, followed by fine-tuning with real-world images. 5) There are no observable negative effects of pre-training with synthetic data. Thus, any face recognition system in our experiments benefits from using synthetic face images. The synthetic data generator, as well as all experiments, are publicly available.
Morphable Face Models - An Open Framework
Sep 26, 2017

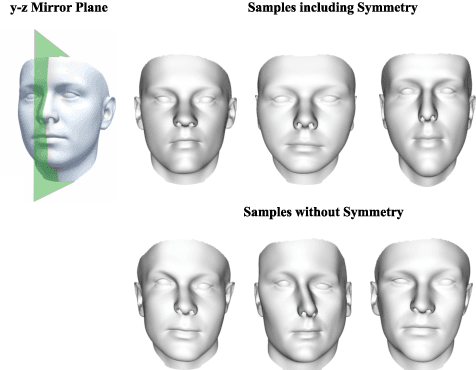

In this paper, we present a novel open-source pipeline for face registration based on Gaussian processes as well as an application to face image analysis. Non-rigid registration of faces is significant for many applications in computer vision, such as the construction of 3D Morphable face models (3DMMs). Gaussian Process Morphable Models (GPMMs) unify a variety of non-rigid deformation models with B-splines and PCA models as examples. GPMM separate problem specific requirements from the registration algorithm by incorporating domain-specific adaptions as a prior model. The novelties of this paper are the following: (i) We present a strategy and modeling technique for face registration that considers symmetry, multi-scale and spatially-varying details. The registration is applied to neutral faces and facial expressions. (ii) We release an open-source software framework for registration and model-building, demonstrated on the publicly available BU3D-FE database. The released pipeline also contains an implementation of an Analysis-by-Synthesis model adaption of 2D face images, tested on the Multi-PIE and LFW database. This enables the community to reproduce, evaluate and compare the individual steps of registration to model-building and 3D/2D model fitting. (iii) Along with the framework release, we publish a new version of the Basel Face Model (BFM-2017) with an improved age distribution and an additional facial expression model.
Gaussian Process Morphable Models
Mar 23, 2016
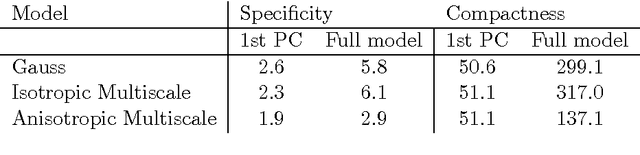

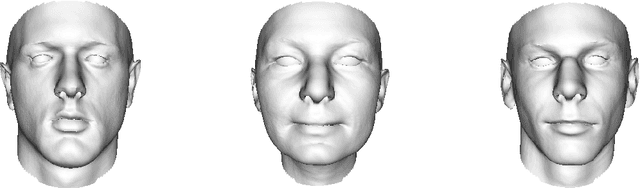
Statistical shape models (SSMs) represent a class of shapes as a normal distribution of point variations, whose parameters are estimated from example shapes. Principal component analysis (PCA) is applied to obtain a low-dimensional representation of the shape variation in terms of the leading principal components. In this paper, we propose a generalization of SSMs, called Gaussian Process Morphable Models (GPMMs). We model the shape variations with a Gaussian process, which we represent using the leading components of its Karhunen-Loeve expansion. To compute the expansion, we make use of an approximation scheme based on the Nystrom method. The resulting model can be seen as a continuous analogon of an SSM. However, while for SSMs the shape variation is restricted to the span of the example data, with GPMMs we can define the shape variation using any Gaussian process. For example, we can build shape models that correspond to classical spline models, and thus do not require any example data. Furthermore, Gaussian processes make it possible to combine different models. For example, an SSM can be extended with a spline model, to obtain a model that incorporates learned shape characteristics, but is flexible enough to explain shapes that cannot be represented by the SSM. We introduce a simple algorithm for fitting a GPMM to a surface or image. This results in a non-rigid registration approach, whose regularization properties are defined by a GPMM. We show how we can obtain different registration schemes,including methods for multi-scale, spatially-varying or hybrid registration, by constructing an appropriate GPMM. As our approach strictly separates modelling from the fitting process, this is all achieved without changes to the fitting algorithm. We show the applicability and versatility of GPMMs on a clinical use case, where the goal is the model-based segmentation of 3D forearm images.