 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Deep Face Recognition Systems with Synthetic Data
Paper and Code

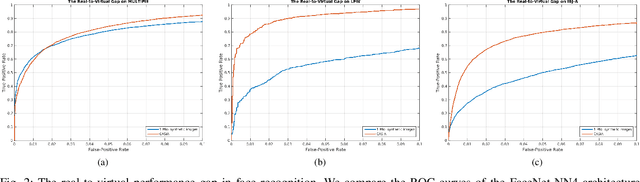
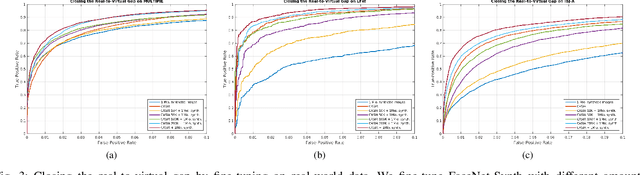
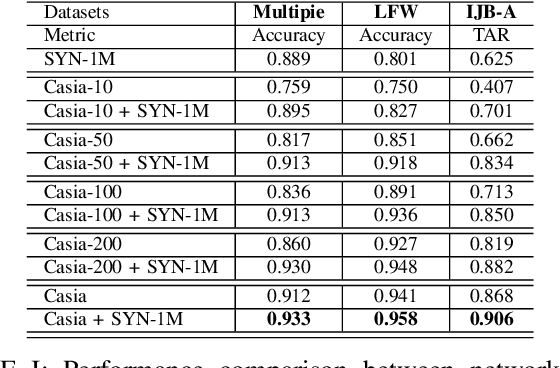
Recent advances in deep learning have significantly increased the performance of face recognition systems. The performance and reliability of these models depend heavily on the amount and quality of the training data. However, the collection of annotated large datasets does not scale well and the control over the quality of the data decreases with the size of the dataset. In this work, we explore how synthetically generated data can be used to decrease the number of real-world images needed for training deep face recognition systems. In particular, we make use of a 3D morphable face model for the generation of images with arbitrary amounts of facial identities and with full control over image variations, such as pose, illumination, and background. In our experiments with an off-the-shelf face recognition software we observe the following phenomena: 1) The amount of real training data needed to train competitive deep face recognition systems can be reduced significantly. 2) Combining large-scale real-world data with synthetic data leads to an increased performance. 3) Models trained only on synthetic data with strong variations in pose, illumination, and background perform very well across different datasets even without dataset adaptation. 4) The real-to-virtual performance gap can be closed when using synthetic data for pre-training, followed by fine-tuning with real-world images. 5) There are no observable negative effects of pre-training with synthetic data. Thus, any face recognition system in our experiments benefits from using synthetic face images. The synthetic data generator, as well as all experiments, are publicly available.