 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy Structure Learning of Hierarchical Compositional Models
Paper and Code
May 29, 2018

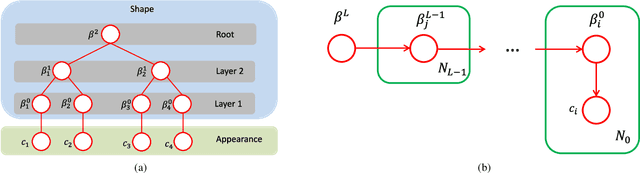
Learning the representation of an object in terms of individual parts and their spatial as well as hierarchical relation is a fundamental problem of vision. Existing approaches are limited by the need of segmented training data and prior knowledge of the object's geometry. In this paper, we overcome those limitations by integrating an explicit background model into the structure learning process. We formulate the structure learning as a hierarchical clustering process. Thereby, we iterate in an EM-type procedure between clustering image patches and using the clustered data for learning part models. The hierarchical clustering proceeds in a bottom-up manner, learning the parts of lower layers in the hierarchy first and subsequently composing them into higher-order parts. A final top-down process composes the learned hierarchical parts into a holistic object model. The key novelty of our approach is that we learn a background model that competes with the object model (the foreground) in explaining the training data. In this way, we integrate the foreground-background segmentation task into the structure learning process and therefore overcome the need for segmented training data. As a result, we can infer the number of layers in the hierarchy, the number of parts per layer and the foreground-background segmentation in a joint optimization process. We demonstrate the ability to learn semantically meaningful hierarchical compositional models from a small set of natural images of an object without detailed supervision. We show that the learned object models achieve state-of-the-art results when compared with other generative object models at object classification on a standard transfer learning dataset. The code and data used in this work are publicly available.