 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralPLexer3: Accurate Biomolecular Complex Structure Prediction with Flow Models
Dec 18, 2024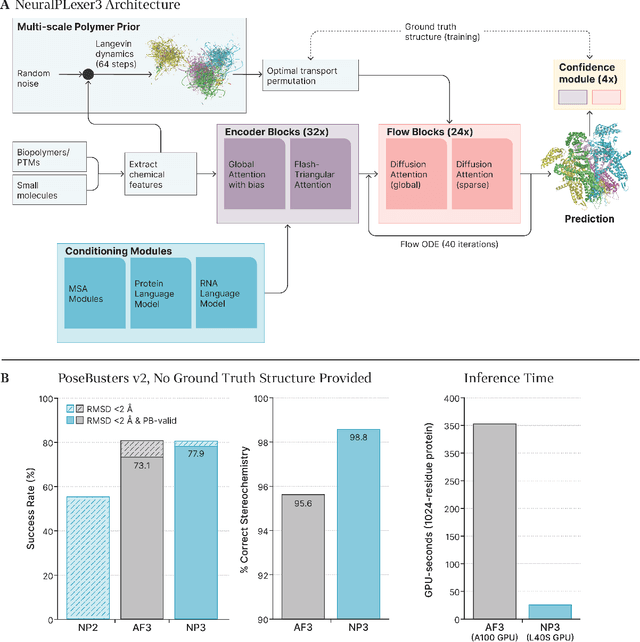
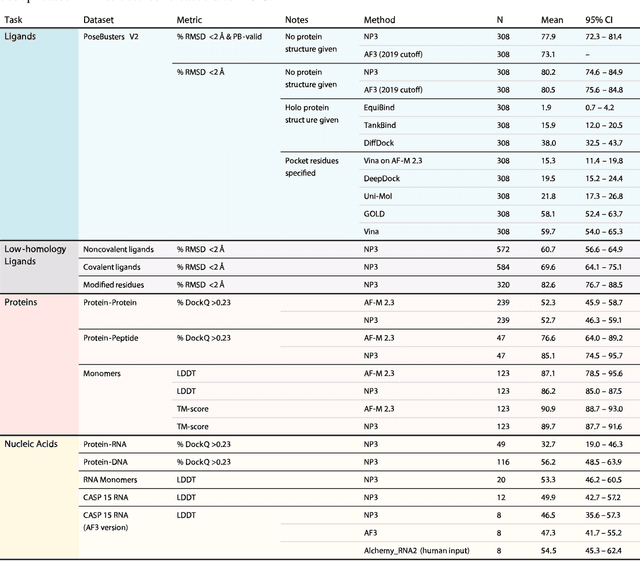
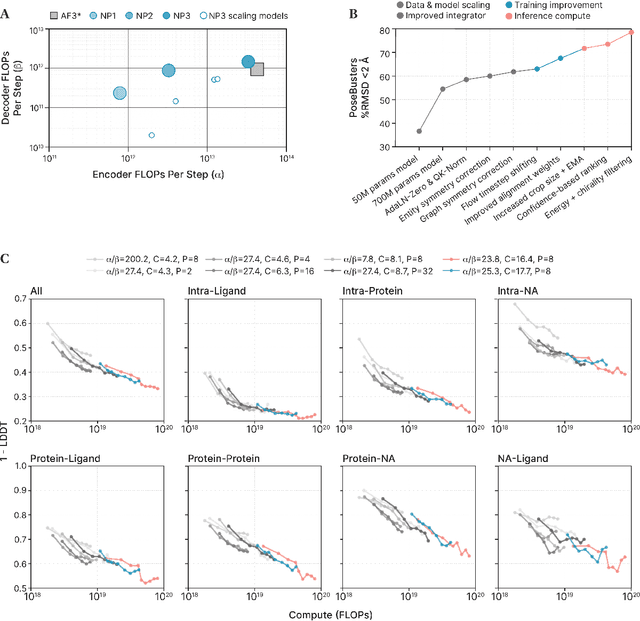
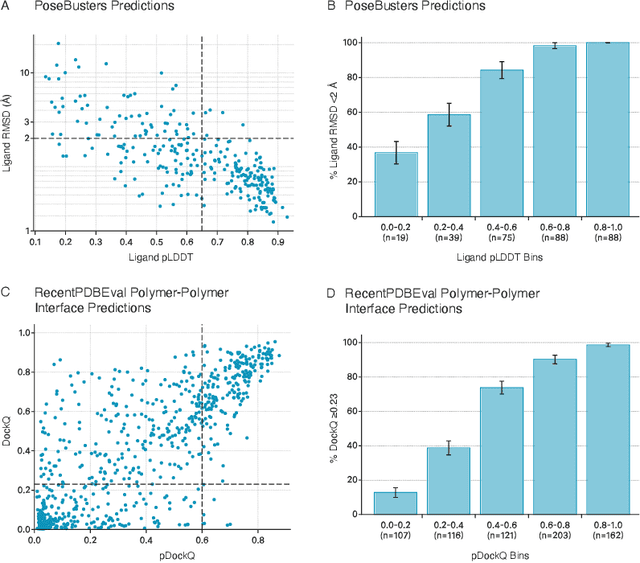
Structure determination is essential to a mechanistic understanding of diseases and the development of novel therapeutics. Machine-learning-based structure prediction methods have made significant advancements by computationally predicting protein and bioassembly structures from sequences and molecular topology alone. Despite substantial progress in the field, challenges remain to deliver structure prediction models to real-world drug discovery. Here, we present NeuralPLexer3 -- a physics-inspired flow-based generative model that achieves state-of-the-art prediction accuracy on key biomolecular interaction types and improves training and sampling efficiency compared to its predecessors and alternative methodologies. Examined through newly developed benchmarking strategies, NeuralPLexer3 excels in vital areas that are crucial to structure-based drug design, such as physical validity and ligand-induced conformational changes.
Dynamic-Backbone Protein-Ligand Structure Prediction with Multiscale Generative Diffusion Models
Sep 30, 2022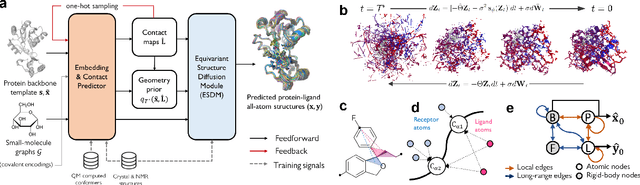
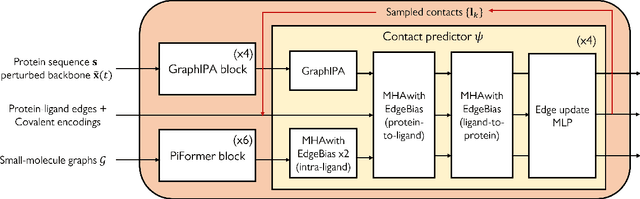
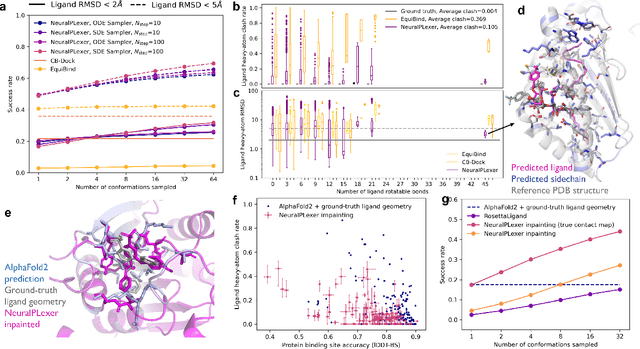
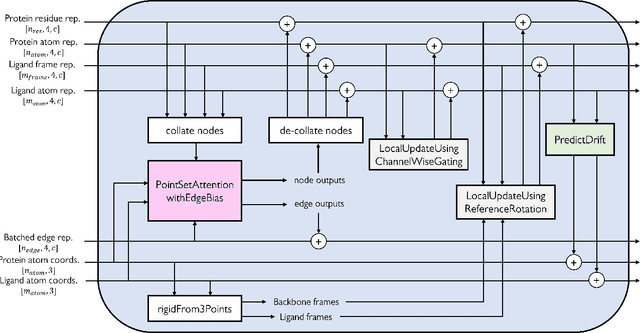
Molecular complexes formed by proteins and small-molecule ligands are ubiquitous, and predicting their 3D structures can facilitate both biological discoveries and the design of novel enzymes or drug molecules. Here we propose NeuralPLexer, a deep generative model framework to rapidly predict protein-ligand complex structures and their fluctuations using protein backbone template and molecular graph inputs. NeuralPLexer jointly samples protein and small-molecule 3D coordinates at an atomistic resolution through a generative model that incorporates biophysical constraints and inferred proximity information into a time-truncated diffusion process. The reverse-time generative diffusion process is learned by a novel stereochemistry-aware equivariant graph transformer that enables efficient, concurrent gradient field prediction for all heavy atoms in the protein-ligand complex. NeuralPLexer outperforms existing physics-based and learning-based methods on benchmarking problems including fixed-backbone blind protein-ligand docking and ligand-coupled binding site repacking. Moreover, we identify preliminary evidence that NeuralPLexer enriches bound-state-like protein structures when applied to systems where protein folding landscapes are significantly altered by the presence of ligands. Our results reveal that a data-driven approach can capture the structural cooperativity among protein and small-molecule entities, showing promise for the computational identification of novel drug targets and the end-to-end differentiable design of functional small-molecules and ligand-binding proteins.
Molecular-orbital-based Machine Learning for Open-shell and Multi-reference Systems with Kernel Addition Gaussian Process Regression
Jul 17, 2022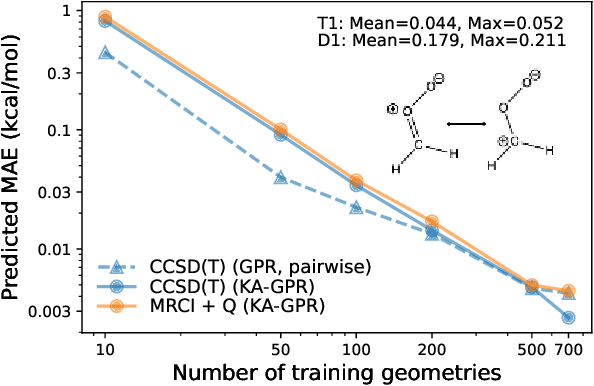
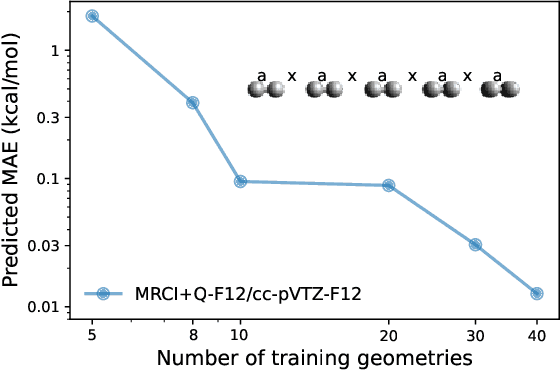
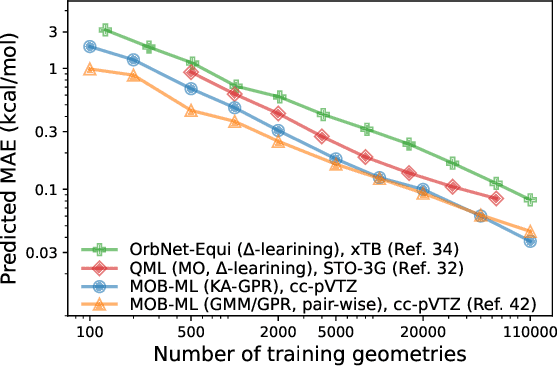
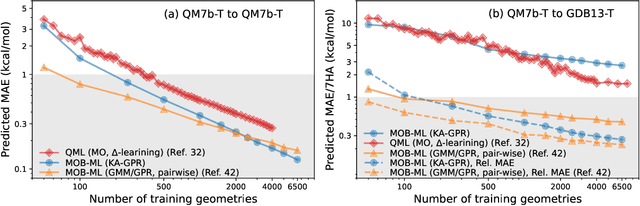
We introduce a novel machine learning strategy, kernel addition Gaussian process regression (KA-GPR), in molecular-orbital-based machine learning (MOB-ML) to learn the total correlation energies of general electronic structure theories for closed- and open-shell systems by introducing a machine learning strategy. The learning efficiency of MOB-ML (KA-GPR) is the same as the original MOB-ML method for the smallest criegee molecule, which is a closed-shell molecule with multi-reference characters. In addition, the prediction accuracies of different small free radicals could reach the chemical accuracy of 1 kcal/mol by training on one example structure. Accurate potential energy surfaces for the H10 chain (closed-shell) and water OH bond dissociation (open-shell) could also be generated by MOB-ML (KA-GPR). To explore the breadth of chemical systems that KA-GPR can describe, we further apply MOB-ML to accurately predict the large benchmark datasets for closed- (QM9, QM7b-T, GDB-13-T) and open-shell (QMSpin) molecules.
Molecular Dipole Moment Learning via Rotationally Equivariant Gaussian Process Regression with Derivatives in Molecular-orbital-based Machine Learning
May 31, 2022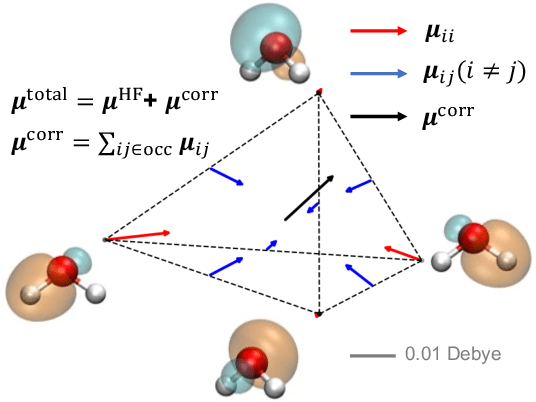
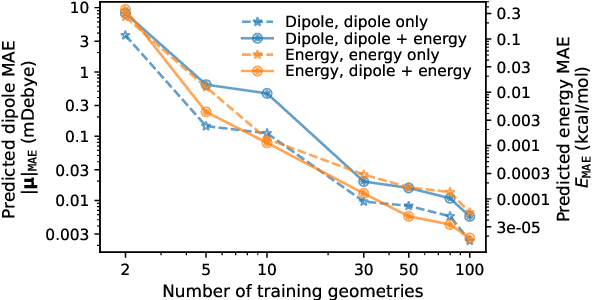
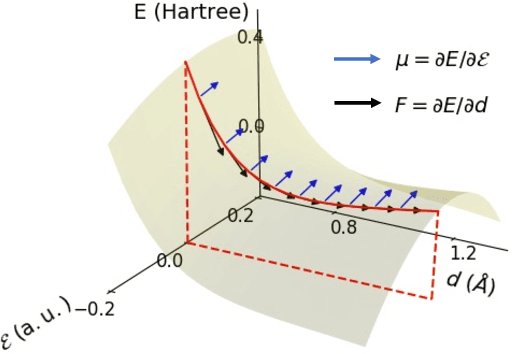
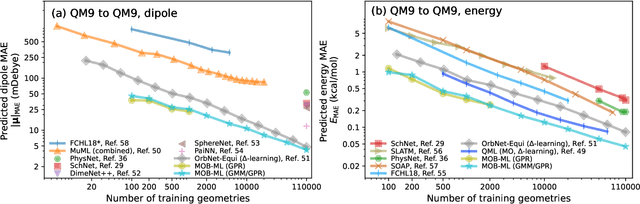
This study extends the accurate and transferable molecular-orbital-based machine learning (MOB-ML) approach to modeling the contribution of electron correlation to dipole moments at the cost of Hartree-Fock computations. A molecular-orbital-based (MOB) pairwise decomposition of the correlation part of the dipole moment is applied, and these pair dipole moments could be further regressed as a universal function of molecular orbitals (MOs). The dipole MOB features consist of the energy MOB features and their responses to electric fields. An interpretable and rotationally equivariant Gaussian process regression (GPR) with derivatives algorithm is introduced to learn the dipole moment more efficiently. The proposed problem setup, feature design, and ML algorithm are shown to provide highly-accurate models for both dipole moment and energies on water and fourteen small molecules. To demonstrate the ability of MOB-ML to function as generalized density-matrix functionals for molecular dipole moments and energies of organic molecules, we further apply the proposed MOB-ML approach to train and test the molecules from the QM9 dataset. The application of local scalable GPR with Gaussian mixture model unsupervised clustering (GMM/GPR) scales up MOB-ML to a large-data regime while retaining the prediction accuracy. In addition, compared with literature results, MOB-ML provides the best test MAEs of 4.21 mDebye and 0.045 kcal/mol for dipole moment and energy models, respectively, when training on 110000 QM9 molecules. The excellent transferability of the resulting QM9 models is also illustrated by the accurate predictions for four different series of peptides.
Accurate Molecular-Orbital-Based Machine Learning Energies via Unsupervised Clustering of Chemical Space
Apr 21, 2022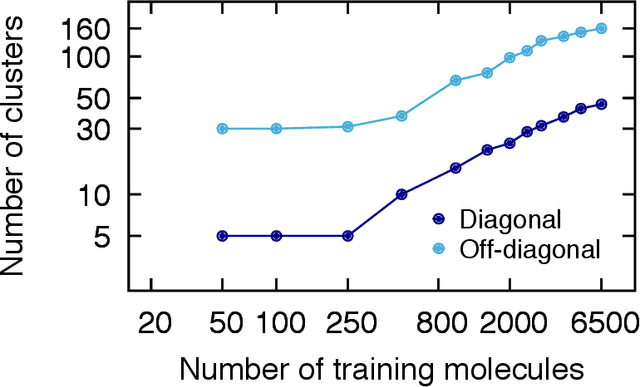
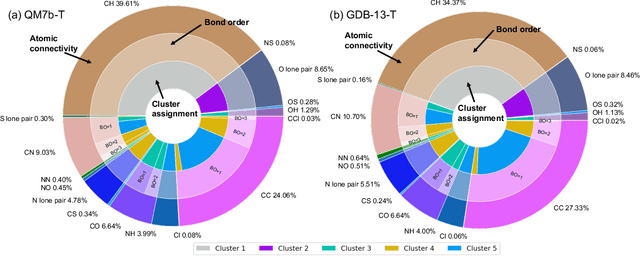
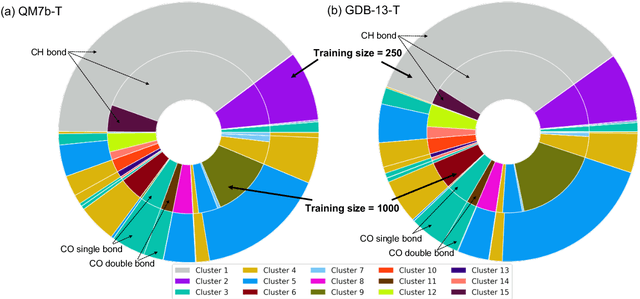
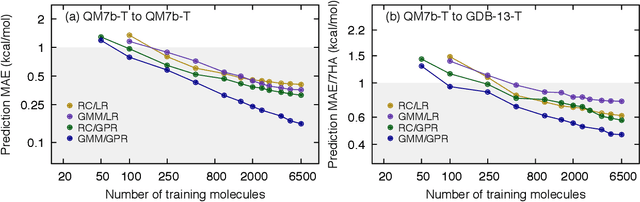
We introduce an unsupervised clustering algorithm to improve training efficiency and accuracy in predicting energies using molecular-orbital-based machine learning (MOB-ML). This work determines clusters via the Gaussian mixture model (GMM) in an entirely automatic manner and simplifies an earlier supervised clustering approach [J. Chem. Theory Comput., 15, 6668 (2019)] by eliminating both the necessity for user-specified parameters and the training of an additional classifier. Unsupervised clustering results from GMM have the advantage of accurately reproducing chemically intuitive groupings of frontier molecular orbitals and having improved performance with an increasing number of training examples. The resulting clusters from supervised or unsupervised clustering is further combined with scalable Gaussian process regression (GPR) or linear regression (LR) to learn molecular energies accurately by generating a local regression model in each cluster. Among all four combinations of regressors and clustering methods, GMM combined with scalable exact Gaussian process regression (GMM/GPR) is the most efficient training protocol for MOB-ML. The numerical tests of molecular energy learning on thermalized datasets of drug-like molecules demonstrate the improved accuracy, transferability, and learning efficiency of GMM/GPR over not only other training protocols for MOB-ML, i.e., supervised regression-clustering combined with GPR(RC/GPR) and GPR without clustering. GMM/GPR also provide the best molecular energy predictions compared with the ones from literature on the same benchmark datasets. With a lower scaling, GMM/GPR has a 10.4-fold speedup in wall-clock training time compared with scalable exact GPR with a training size of 6500 QM7b-T molecules.
Molecular Energy Learning Using Alternative Blackbox Matrix-Matrix Multiplication Algorithm for Exact Gaussian Process
Sep 20, 2021
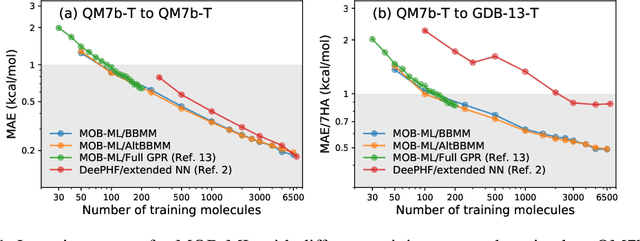

We present an application of the blackbox matrix-matrix multiplication (BBMM) algorithm to scale up the Gaussian Process (GP) training of molecular energies in the molecular-orbital based machine learning (MOB-ML) framework. An alternative implementation of BBMM (AltBBMM) is also proposed to train more efficiently (over four-fold speedup) with the same accuracy and transferability as the original BBMM implementation. The training of MOB-ML was limited to 220 molecules, and BBMM and AltBBMM scale the training of MOB-ML up by over 30 times to 6500 molecules (more than a million pair energies). The accuracy and transferability of both algorithms are examined on the benchmark datasets of organic molecules with 7 and 13 heavy atoms. These lower-scaling implementations of the GP preserve the state-of-the-art learning efficiency in the low-data regime while extending it to the large-data regime with better accuracy than other available machine learning works on molecular energies.
UNiTE: Unitary N-body Tensor Equivariant Network with Applications to Quantum Chemistry
Jun 06, 2021
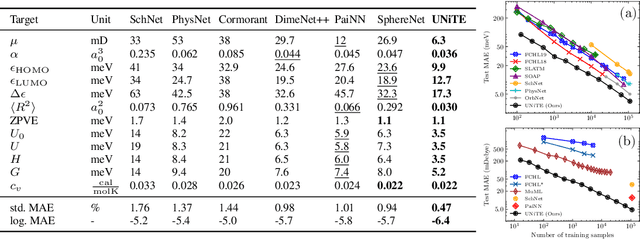
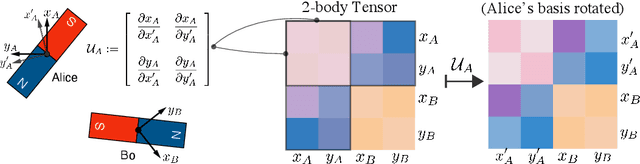
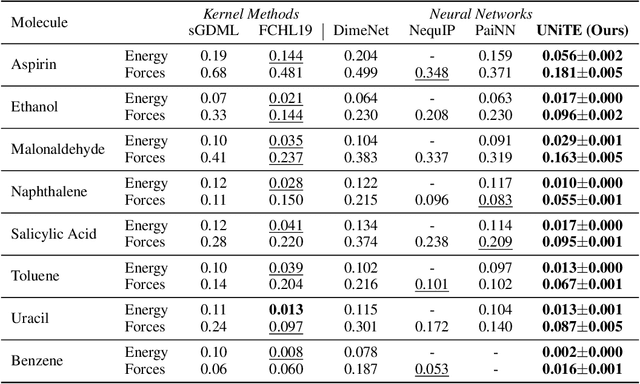
Equivariant neural networks have been successful in incorporating various types of symmetries, but are mostly limited to vector representations of geometric objects. Despite the prevalence of higher-order tensors in various application domains, e.g. in quantum chemistry, equivariant neural networks for general tensors remain unexplored. Previous strategies for learning equivariant functions on tensors mostly rely on expensive tensor factorization which is not scalable when the dimensionality of the problem becomes large. In this work, we propose unitary $N$-body tensor equivariant neural network (UNiTE), an architecture for a general class of symmetric tensors called $N$-body tensors. The proposed neural network is equivariant with respect to the actions of a unitary group, such as the group of 3D rotations. Furthermore, it has a linear time complexity with respect to the number of non-zero elements in the tensor. We also introduce a normalization method, viz., Equivariant Normalization, to improve generalization of the neural network while preserving symmetry. When applied to quantum chemistry, UNiTE outperforms all state-of-the-art machine learning methods of that domain with over 110% average improvements on multiple benchmarks. Finally, we show that UNiTE achieves a robust zero-shot generalization performance on diverse down stream chemistry tasks, while being three orders of magnitude faster than conventional numerical methods with competitive accuracy.
Multi-task learning for electronic structure to predict and explore molecular potential energy surfaces
Nov 11, 2020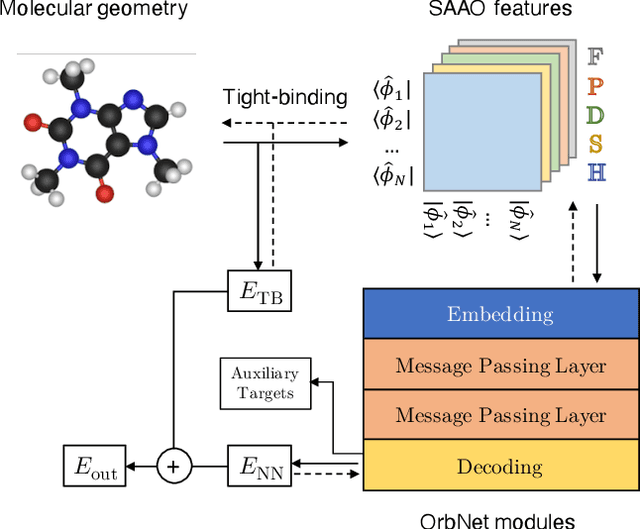

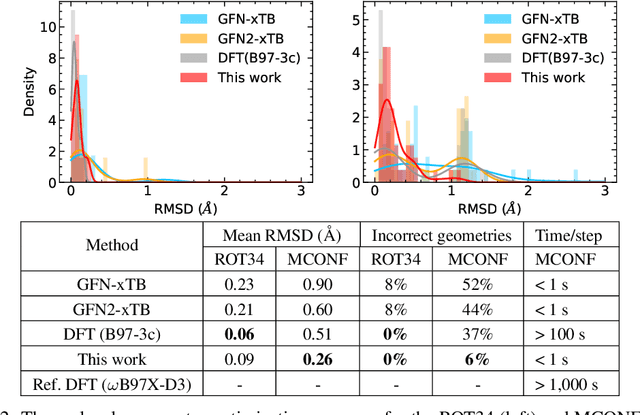
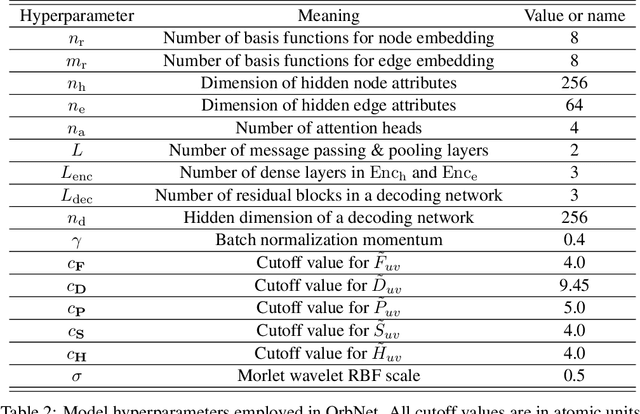
We refine the OrbNet model to accurately predict energy, forces, and other response properties for molecules using a graph neural-network architecture based on features from low-cost approximated quantum operators in the symmetry-adapted atomic orbital basis. The model is end-to-end differentiable due to the derivation of analytic gradients for all electronic structure terms, and is shown to be transferable across chemical space due to the use of domain-specific features. The learning efficiency is improved by incorporating physically motivated constraints on the electronic structure through multi-task learning. The model outperforms existing methods on energy prediction tasks for the QM9 dataset and for molecular geometry optimizations on conformer datasets, at a computational cost that is thousand-fold or more reduced compared to conventional quantum-chemistry calculations (such as density functional theory) that offer similar accuracy.
OrbNet: Deep Learning for Quantum Chemistry Using Symmetry-Adapted Atomic-Orbital Features
Jul 15, 2020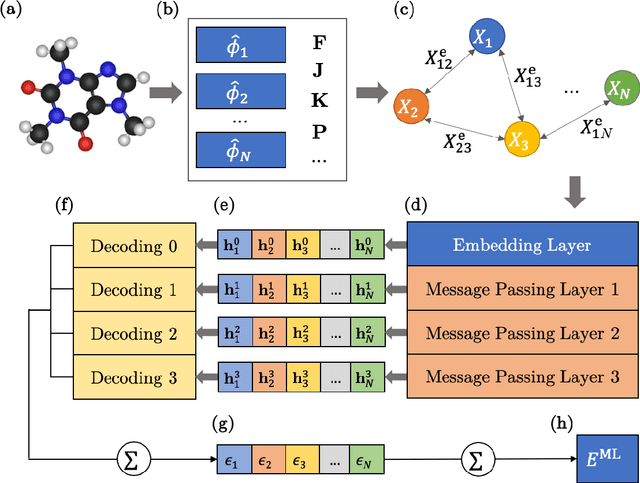
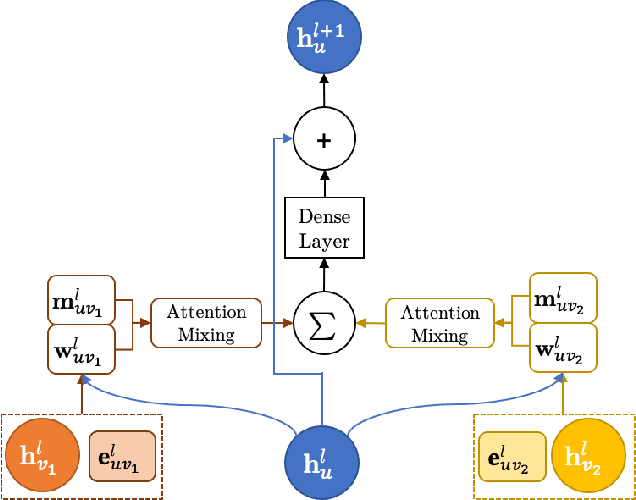
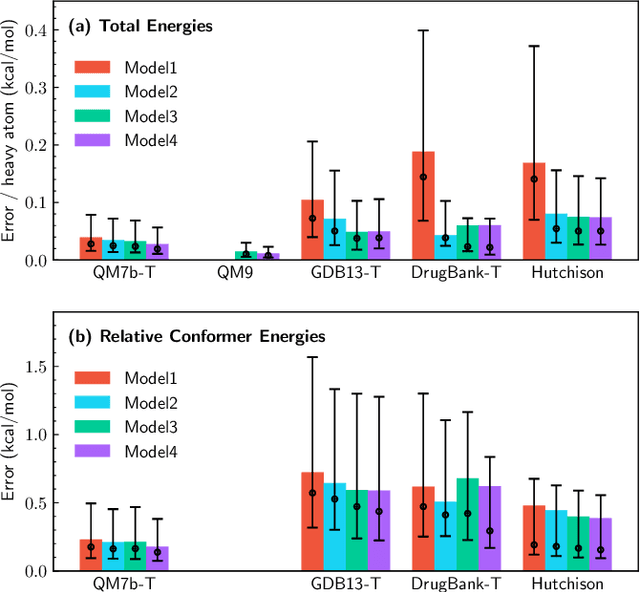
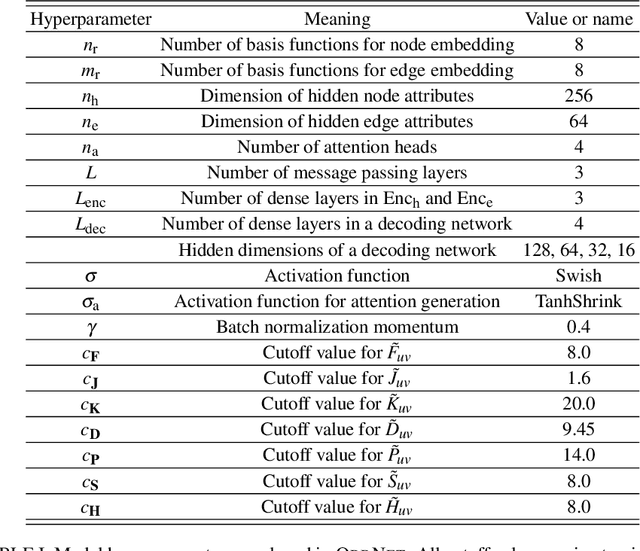
We introduce a machine learning method in which energy solutions from the Schrodinger equation are predicted using symmetry adapted atomic orbitals features and a graph neural-network architecture. \textsc{OrbNet} is shown to outperform existing methods in terms of learning efficiency and transferability for the prediction of density functional theory results while employing low-cost features that are obtained from semi-empirical electronic structure calculations. For applications to datasets of drug-like molecules, including QM7b-T, QM9, GDB-13-T, DrugBank, and the conformer benchmark dataset of Folmsbee and Hutchison, \textsc{OrbNet} predicts energies within chemical accuracy of DFT at a computational cost that is thousand-fold or more reduced.
Regression-clustering for Improved Accuracy and Training Cost with Molecular-Orbital-Based Machine Learning
Sep 09, 2019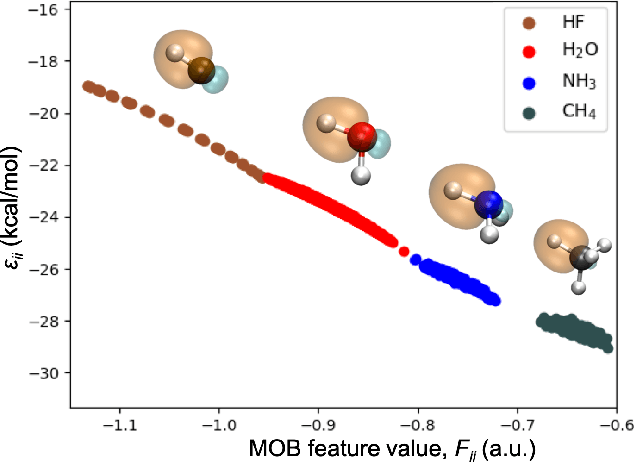
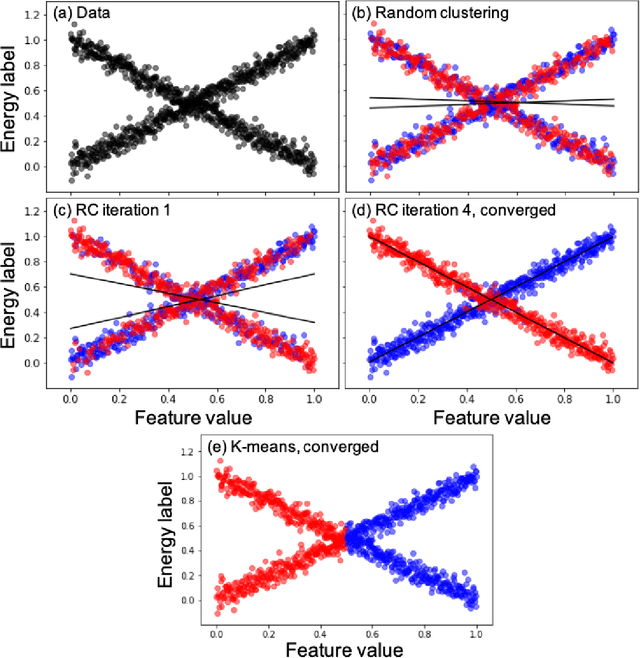
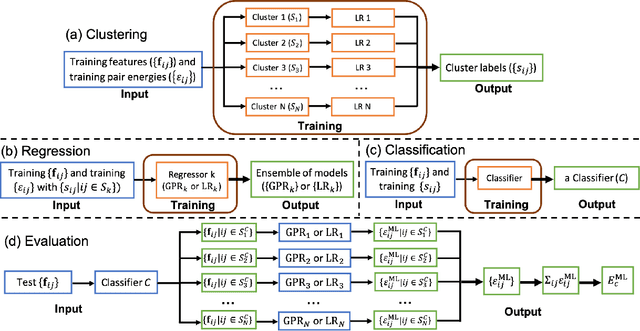
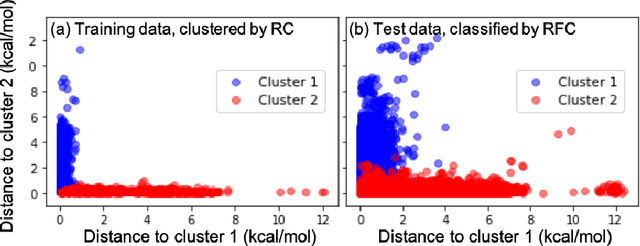
Machine learning (ML) in the representation of molecular-orbital-based (MOB) features has been shown to be an accurate and transferable approach to the prediction of post-Hartree-Fock correlation energies. Previous applications of MOB-ML employed Gaussian Process Regression (GPR), which provides good prediction accuracy with small training sets; however, the cost of GPR training scales cubically with the amount of data and becomes a computational bottleneck for large training sets. In the current work, we address this problem by introducing a clustering/regression/classification implementation of MOB-ML. In a first step, regression clustering (RC) is used to partition the training data to best fit an ensemble of linear regression (LR) models; in a second step, each cluster is regressed independently, using either LR or GPR; and in a third step, a random forest classifier (RFC) is trained for the prediction of cluster assignments based on MOB feature values. Upon inspection, RC is found to recapitulate chemically intuitive groupings of the frontier molecular orbitals, and the combined RC/LR/RFC and RC/GPR/RFC implementations of MOB-ML are found to provide good prediction accuracy with greatly reduced wall-clock training times. For a dataset of thermalized geometries of 7211 organic molecules of up to seven heavy atoms, both implementations reach chemical accuracy (1 kcal/mol error) with only 300 training molecules, while providing 35000-fold and 4500-fold reductions in the wall-clock training time, respectively, compared to MOB-ML without clustering. The resulting models are also demonstrated to retain transferability for the prediction of large-molecule energies with only small-molecule training data. Finally, it is shown that capping the number of training datapoints per cluster leads to further improvements in prediction accuracy with negligible increases in wall-clock training time.