 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERA: Multimodal and Multiscale Self-Explanatory Model with Considerably Reduced Annotation for Lung Nodule Diagnosis
Apr 27, 2025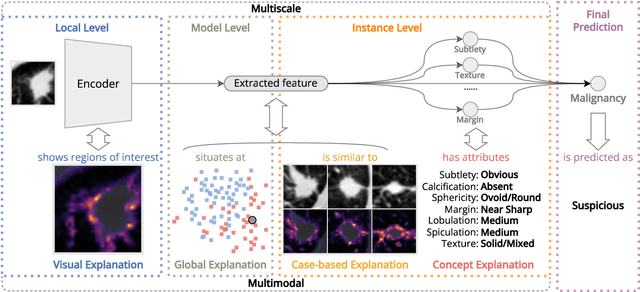
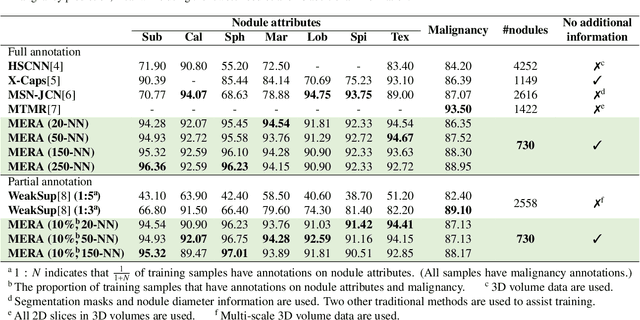
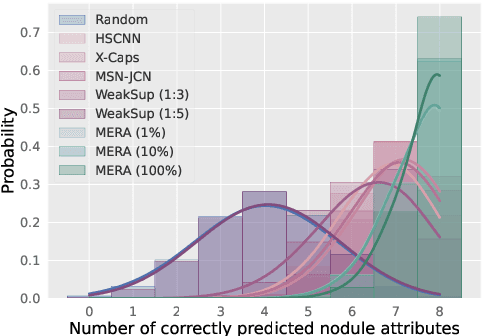
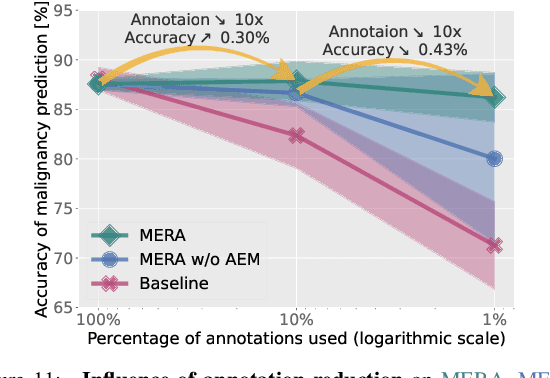
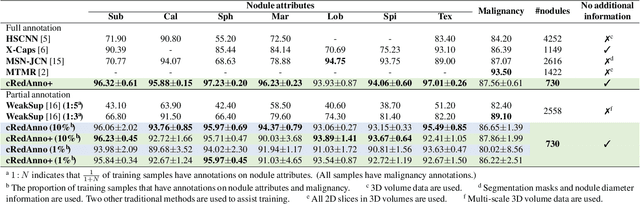
Lung cancer, a leading cause of cancer-related deaths globally, emphasises the importance of early detection for better patient outcomes. Pulmonary nodules, often early indicators of lung cancer, necessitate accurate, timely diagnosis. Despite Explainable Artificial Intelligence (XAI) advances, many existing systems struggle providing clear, comprehensive explanations, especially with limited labelled data. This study introduces MERA, a Multimodal and Multiscale self-Explanatory model designed for lung nodule diagnosis with considerably Reduced Annotation requirements. MERA integrates unsupervised and weakly supervised learning strategies (self-supervised learning techniques and Vision Transformer architecture for unsupervised feature extraction) and a hierarchical prediction mechanism leveraging sparse annotations via semi-supervised active learning in the learned latent space. MERA explains its decisions on multiple levels: model-level global explanations via semantic latent space clustering, instance-level case-based explanations showing similar instances, local visual explanations via attention maps, and concept explanations using critical nodule attributes. Evaluations on the public LIDC dataset show MERA's superior diagnostic accuracy and self-explainability. With only 1% annotated samples, MERA achieves diagnostic accuracy comparable to or exceeding state-of-the-art methods requiring full annotation. The model's inherent design delivers comprehensive, robust, multilevel explanations aligned closely with clinical practice, enhancing trustworthiness and transparency. Demonstrated viability of unsupervised and weakly supervised learning lowers the barrier to deploying diagnostic AI in broader medical domains. Our complete code is open-source available: https://github.com/diku-dk/credanno.
Neural Kinematic Bases for Fluids
Apr 22, 2025



We propose mesh-free fluid simulations that exploit a kinematic neural basis for velocity fields represented by an MLP. We design a set of losses that ensures that these neural bases satisfy fundamental physical properties such as orthogonality, divergence-free, boundary alignment, and smoothness. Our neural bases can then be used to fit an input sketch of a flow, which will inherit the same fundamental properties from the bases. We then can animate such flow in real-time using standard time integrators. Our neural bases can accommodate different domains and naturally extend to three dimensions.
Locally orderless networks
Jun 19, 2024We present Locally Orderless Networks (LON) and its theoretic foundation which links it to Convolutional Neural Networks (CNN), to Scale-space histograms, and measurement theory. The key elements are a regular sampling of the bias and the derivative of the activation function. We compare LON, CNN, and Scale-space histograms on prototypical single-layer networks. We show how LON and CNN can emulate each other, how LON expands the set of functionals computable to non-linear functions such as squaring. We demonstrate simple networks which illustrate the improved performance of LON over CNN on simple tasks for estimating the gradient magnitude squared, for regressing shape area and perimeter lengths, and for explainability of individual pixels' influence on the result.
Extremely weakly-supervised blood vessel segmentation with physiologically based synthesis and domain adaptation
May 26, 2023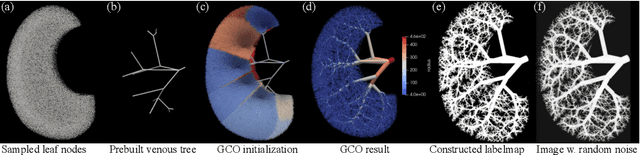


Accurate analysis and modeling of renal functions require a precise segmentation of the renal blood vessels. Micro-CT scans provide image data at higher resolutions, making more small vessels near the renal cortex visible. Although deep-learning-based methods have shown state-of-the-art performance in automatic blood vessel segmentations, they require a large amount of labeled training data. However, voxel-wise labeling in micro-CT scans is extremely time-consuming given the huge volume sizes. To mitigate the problem, we simulate synthetic renal vascular trees physiologically while generating corresponding scans of the simulated trees by training a generative model on unlabeled scans. This enables the generative model to learn the mapping implicitly without the need for explicit functions to emulate the image acquisition process. We further propose an additional segmentation branch over the generative model trained on the generated scans. We demonstrate that the model can directly segment blood vessels on real scans and validate our method on both 3D micro-CT scans of rat kidneys and a proof-of-concept experiment on 2D retinal images. Code and 3D results are available at https://github.com/miccai2023anony/RenalVesselSeg
Localise to segment: crop to improve organ at risk segmentation accuracy
Apr 10, 2023Increased organ at risk segmentation accuracy is required to reduce cost and complications for patients receiving radiotherapy treatment. Some deep learning methods for the segmentation of organs at risk use a two stage process where a localisation network first crops an image to the relevant region and then a locally specialised network segments the cropped organ of interest. We investigate the accuracy improvements brought about by such a localisation stage by comparing to a single-stage baseline network trained on full resolution images. We find that localisation approaches can improve both training time and stability and a two stage process involving both a localisation and organ segmentation network provides a significant increase in segmentation accuracy for the spleen, pancreas and heart from the Medical Segmentation Decathlon dataset. We also observe increased benefits of localisation for smaller organs. Source code that recreates the main results is available at \href{https://github.com/Abe404/localise_to_segment}{this https URL}.
Deep Learning-Assisted Localisation of Nanoparticles in synthetically generated two-photon microscopy images
Mar 17, 2023Tracking single molecules is instrumental for quantifying the transport of molecules and nanoparticles in biological samples, e.g., in brain drug delivery studies. Existing intensity-based localisation methods are not developed for imaging with a scanning microscope, typically used for in vivo imaging. Low signal-to-noise ratios, movement of molecules out-of-focus, and high motion blur on images recorded with scanning two-photon microscopy (2PM) in vivo pose a challenge to the accurate localisation of molecules. Using data-driven models is challenging due to low data volumes, typical for in vivo experiments. We developed a 2PM image simulator to supplement scarce training data. The simulator mimics realistic motion blur, background fluorescence, and shot noise observed in vivo imaging. Training a data-driven model with simulated data improves localisation quality in simulated images and shows why intensity-based methods fail.
A Hybrid Approach to Full-Scale Reconstruction of Renal Arterial Network
Mar 03, 2023The renal vasculature, acting as a resource distribution network, plays an important role in both the physiology and pathophysiology of the kidney. However, no imaging techniques allow an assessment of the structure and function of the renal vasculature due to limited spatial and temporal resolution. To develop realistic computer simulations of renal function, and to develop new image-based diagnostic methods based on artificial intelligence, it is necessary to have a realistic full-scale model of the renal vasculature. We propose a hybrid framework to build subject-specific models of the renal vascular network by using semi-automated segmentation of large arteries and estimation of cortex area from a micro-CT scan as a starting point, and by adopting the Global Constructive Optimization algorithm for generating smaller vessels. Our results show a statistical correspondence between the reconstructed data and existing anatomical data obtained from a rat kidney with respect to morphometric and hemodynamic parameters.
cRedAnno+: Annotation Exploitation in Self-Explanatory Lung Nodule Diagnosis
Nov 07, 2022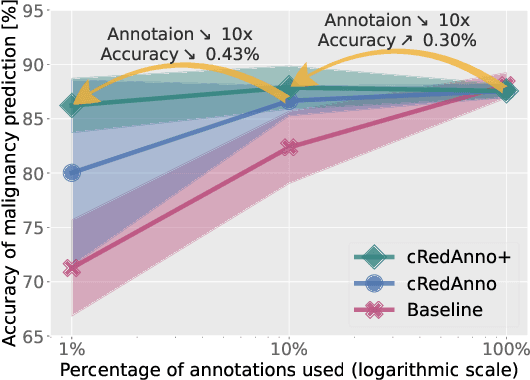
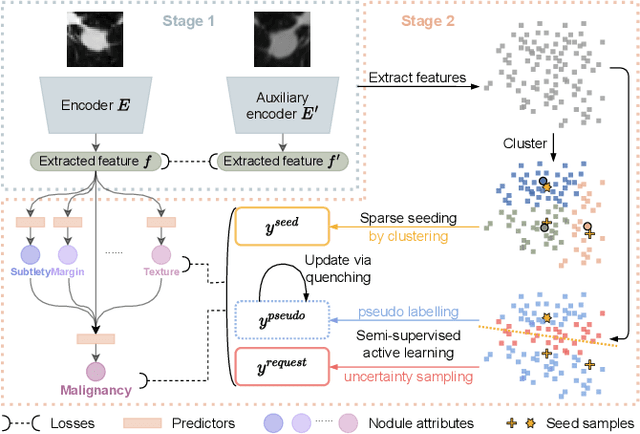
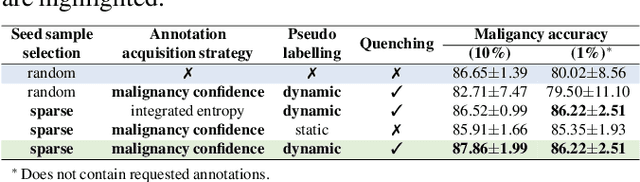
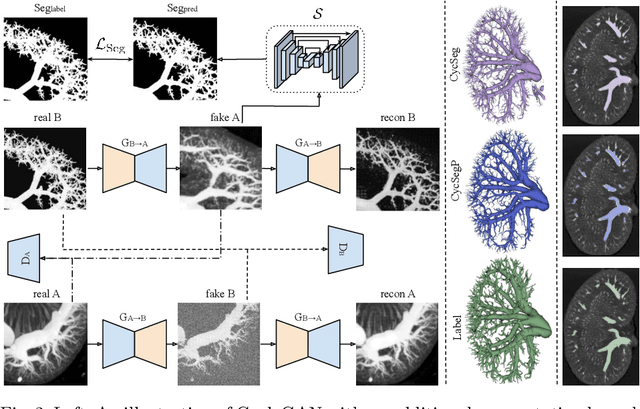
Recently, attempts have been made to reduce annotation requirements in feature-based self-explanatory models for lung nodule diagnosis. As a representative, cRedAnno achieves competitive performance with considerably reduced annotation needs by introducing self-supervised contrastive learning to do unsupervised feature extraction. However, it exhibits unstable performance under scarce annotation conditions. To improve the accuracy and robustness of cRedAnno, we propose an annotation exploitation mechanism by conducting semi-supervised active learning with sparse seeding and training quenching in the learned semantically meaningful reasoning space to jointly utilise the extracted features, annotations, and unlabelled data. The proposed approach achieves comparable or even higher malignancy prediction accuracy with 10x fewer annotations, meanwhile showing better robustness and nodule attribute prediction accuracy under the condition of 1% annotations. Our complete code is open-source available: https://github.com/diku-dk/credanno.
Auto-segmentation of Hip Joints using MultiPlanar UNet with Transfer learning
Aug 18, 2022
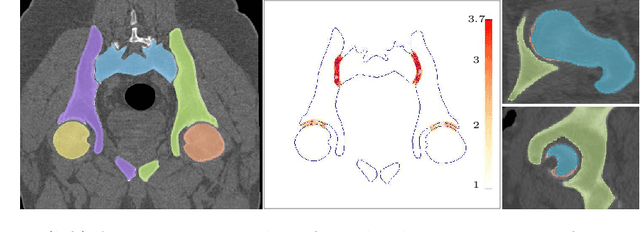
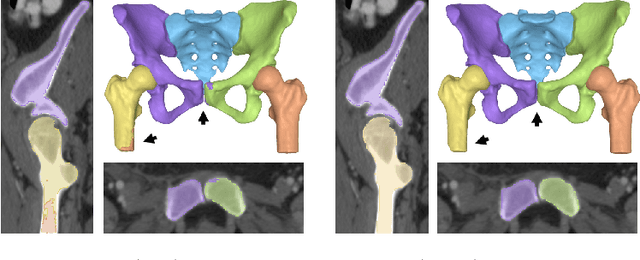
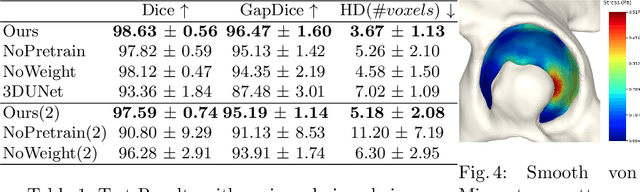
Accurate geometry representation is essential in developing finite element models. Although generally good, deep-learning segmentation approaches with only few data have difficulties in accurately segmenting fine features, e.g., gaps and thin structures. Subsequently, segmented geometries need labor-intensive manual modifications to reach a quality where they can be used for simulation purposes. We propose a strategy that uses transfer learning to reuse datasets with poor segmentation combined with an interactive learning step where fine-tuning of the data results in anatomically accurate segmentations suitable for simulations. We use a modified MultiPlanar UNet that is pre-trained using inferior hip joint segmentation combined with a dedicated loss function to learn the gap regions and post-processing to correct tiny inaccuracies on symmetric classes due to rotational invariance. We demonstrate this robust yet conceptually simple approach applied with clinically validated results on publicly available computed tomography scans of hip joints. Code and resulting 3D models are available at: https://github.com/MICCAI2022-155/AuToSeg}
Reducing Annotation Need in Self-Explanatory Models for Lung Nodule Diagnosis
Jun 27, 2022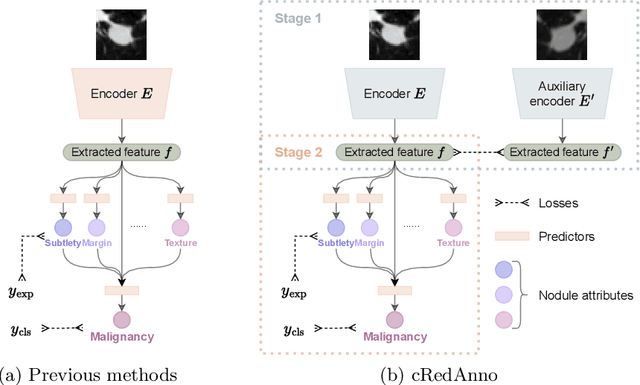
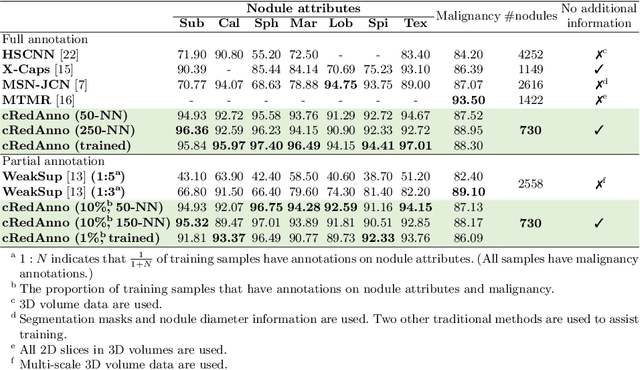
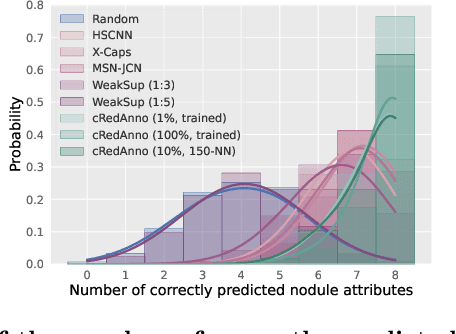

Feature-based self-explanatory methods explain their classification in terms of human-understandable features. In the medical imaging community, this semantic matching of clinical knowledge adds significantly to the trustworthiness of the AI. However, the cost of additional annotation of features remains a pressing issue. We address this problem by proposing cRedAnno, a data-/annotation-efficient self-explanatory approach for lung nodule diagnosis. cRedAnno considerably reduces the annotation need by introducing self-supervised contrastive learning to alleviate the burden of learning most parameters from annotation, replacing end-to-end training with two-stage training. When training with hundreds of nodule samples and only 1% of their annotations, cRedAnno achieves competitive accuracy in predicting malignancy, meanwhile significantly surpassing most previous works in predicting nodule attributes. Visualisation of the learned space further indicates that the correlation between the clustering of malignancy and nodule attributes coincides with clinical knowledge. Our complete code is open-source available: https://github.com/ludles/credanno.