 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Annotation Need in Self-Explanatory Models for Lung Nodule Diagnosis
Jun 27, 2022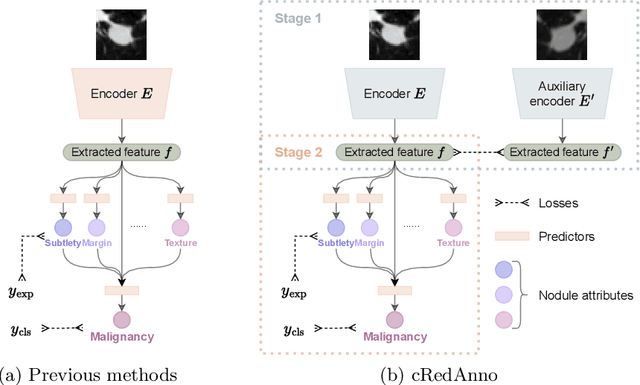
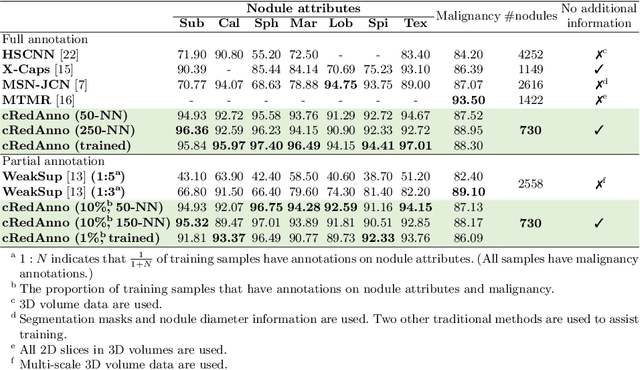
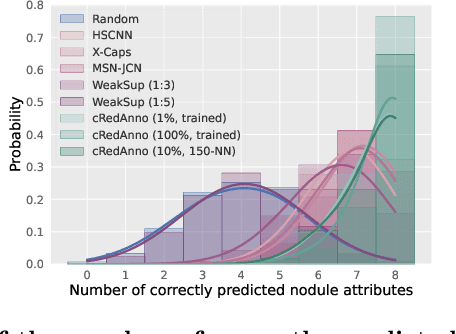

Feature-based self-explanatory methods explain their classification in terms of human-understandable features. In the medical imaging community, this semantic matching of clinical knowledge adds significantly to the trustworthiness of the AI. However, the cost of additional annotation of features remains a pressing issue. We address this problem by proposing cRedAnno, a data-/annotation-efficient self-explanatory approach for lung nodule diagnosis. cRedAnno considerably reduces the annotation need by introducing self-supervised contrastive learning to alleviate the burden of learning most parameters from annotation, replacing end-to-end training with two-stage training. When training with hundreds of nodule samples and only 1% of their annotations, cRedAnno achieves competitive accuracy in predicting malignancy, meanwhile significantly surpassing most previous works in predicting nodule attributes. Visualisation of the learned space further indicates that the correlation between the clustering of malignancy and nodule attributes coincides with clinical knowledge. Our complete code is open-source available: https://github.com/ludles/credanno.
Learning Coulomb Diamonds in Large Quantum Dot Arrays
May 03, 2022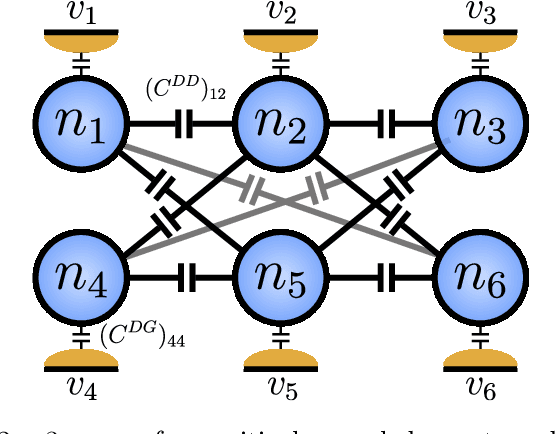
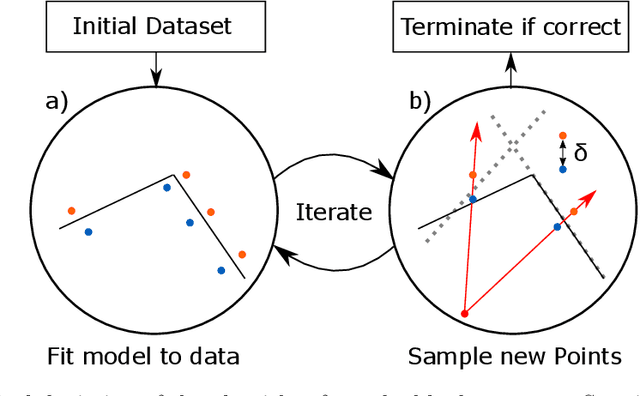
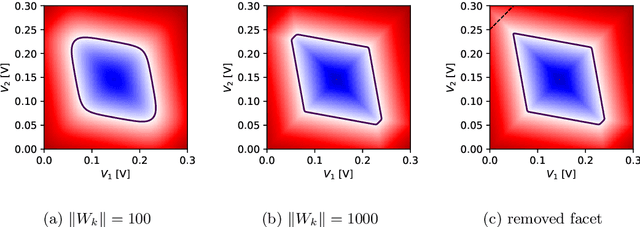
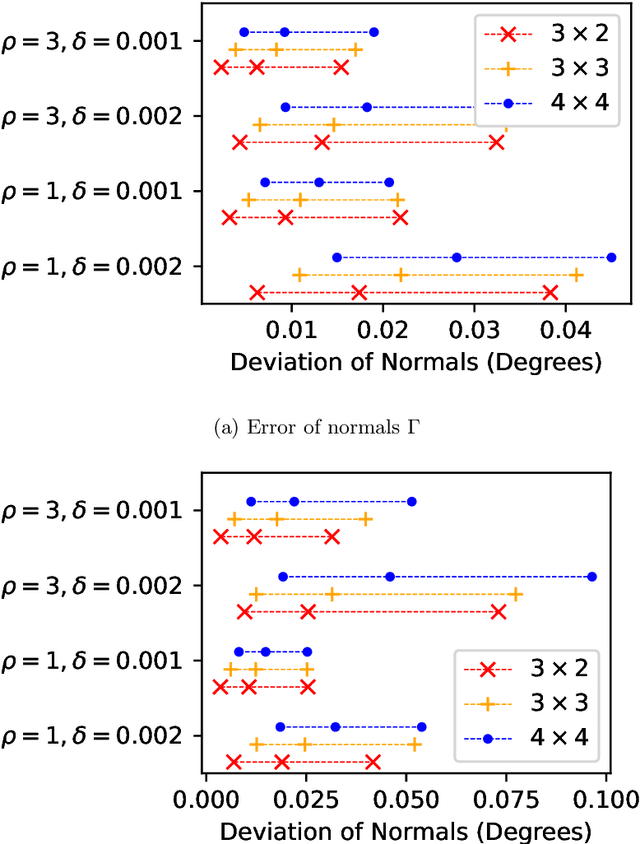
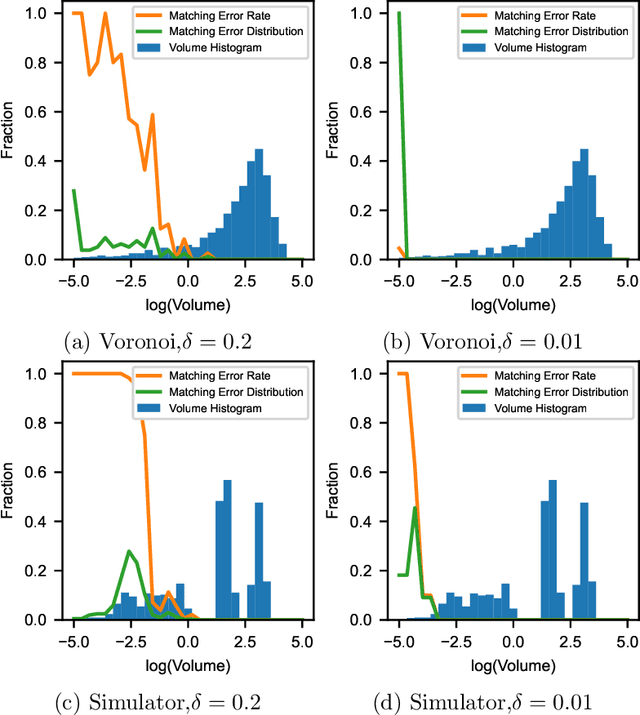
We introduce an algorithm that is able to find the facets of Coulomb diamonds in quantum dot arrays. We simulate these arrays using the constant-interaction model, and rely only on one-dimensional raster scans (rays) to learn a model of the device using regularized maximum likelihood estimation. This allows us to determine, for a given charge state of the device, which transitions exist and what the compensated gate voltages for these are. For smaller devices the simulator can also be used to compute the exact boundaries of the Coulomb diamonds, which we use to assess that our algorithm correctly finds the vast majority of transitions with high precision.
Estimation of Convex Polytopes for Automatic Discovery of Charge State Transitions in Quantum Dot Arrays
Aug 20, 2021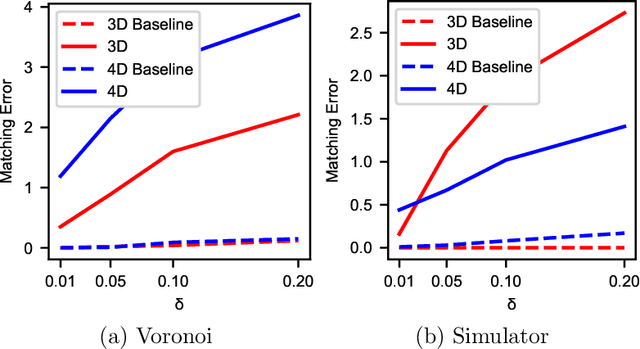
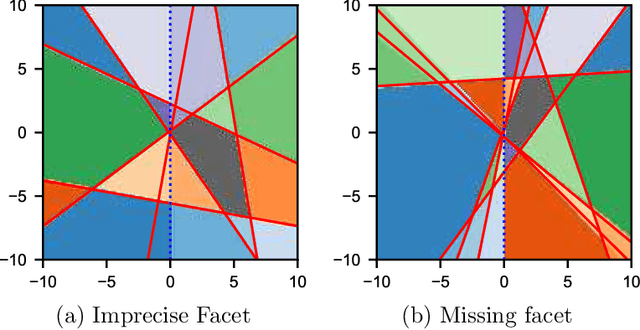
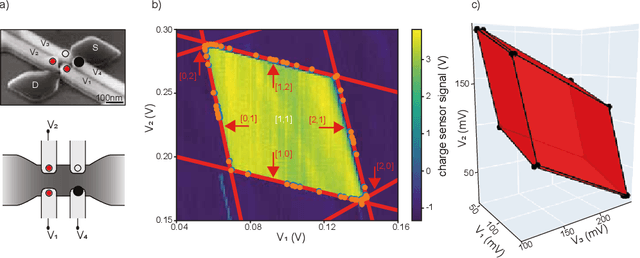
In spin based quantum dot arrays, a leading technology for quantum computation applications, material or fabrication imprecisions affect the behaviour of the device, which is compensated via tuning parameters. Automatic tuning of these device parameters constitutes a formidable challenge for machine-learning. Here, we present the first practical algorithm for controlling the transition of electrons in a spin qubit array. We exploit a connection to computational geometry and phrase the task as estimating a convex polytope from measurements. Our proposed algorithm uses active learning, to find the count, shapes and sizes of all facets of a given polytope. We test our algorithm on artifical polytopes as well as a real 2x2 spin qubit array. Our results show that we can reliably find the facets of the polytope, including small facets with sizes on the order of the measurement precision. We discuss the implications of the NP-hardness of the underlying estimation problem and outline design considerations, limitations and tuning strategies for controlling future large-scale spin qubit devices.
Spot the Difference: Topological Anomaly Detection via Geometric Alignment
Jun 09, 2021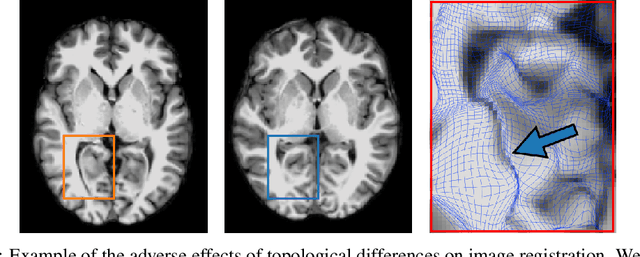
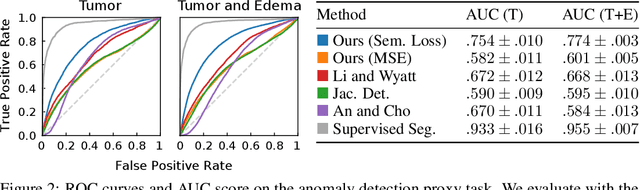
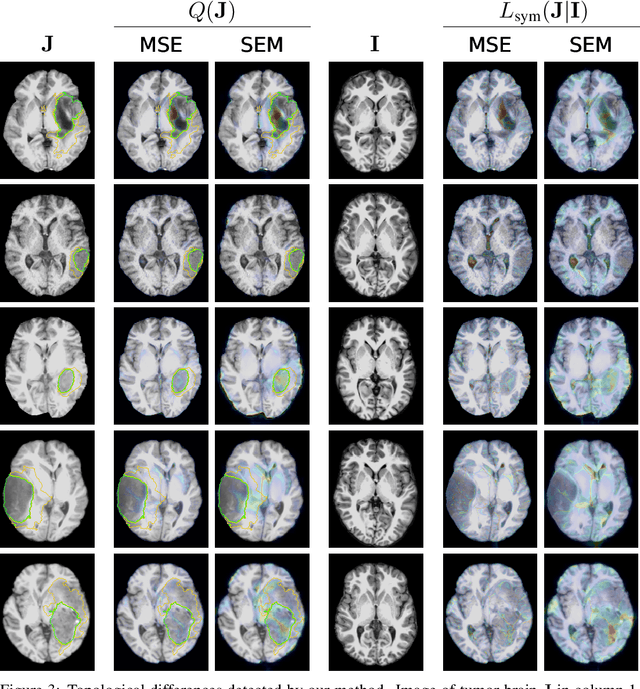
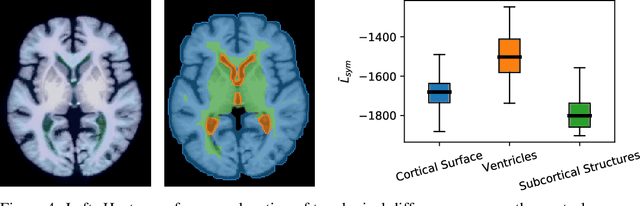
Geometric alignment appears in a variety of applications, ranging from domain adaptation, optimal transport, and normalizing flows in machine learning; optical flow and learned augmentation in computer vision and deformable registration within biomedical imaging. A recurring challenge is the alignment of domains whose topology is not the same; a problem that is routinely ignored, potentially introducing bias in downstream analysis. As a first step towards solving such alignment problems, we propose an unsupervised topological difference detection algorithm. The model is based on a conditional variational auto-encoder and detects topological anomalies with regards to a reference alongside the registration step. We consider both a) topological changes in the image under spatial variation and b) unexpected transformations. Our approach is validated on a proxy task of unsupervised anomaly detection in images.
Semi-supervised, Topology-Aware Segmentation of Tubular Structures from Live Imaging 3D Microscopy
May 20, 2021



Motivated by a challenging tubular network segmentation task, this paper tackles two commonly encountered problems in biomedical imaging: Topological consistency of the segmentation, and limited annotations. We propose a topological score which measures both topological and geometric consistency between the predicted and ground truth segmentations, applied for model selection and validation. We apply our topological score in three scenarios: i. a U-net ii. a U-net pretrained on an autoencoder, and iii. a semisupervised U-net architecture, which offers a straightforward approach to jointly training the network both as an autoencoder and a segmentation algorithm. This allows us to utilize un-annotated data for training a representation that generalizes across test data variability, in spite of our annotated training data having very limited variation. Our contributions are validated on a challenging segmentation task, locating tubular structures in the fetal pancreas from noisy live imaging confocal microscopy.
Semantic similarity metrics for learned image registration
Apr 20, 2021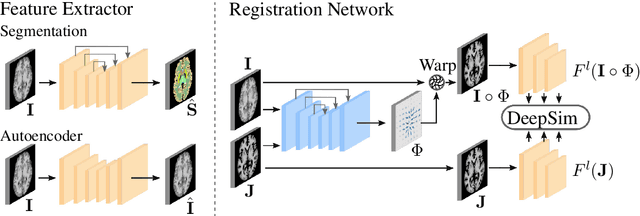
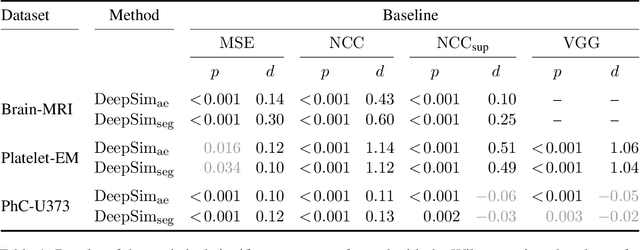
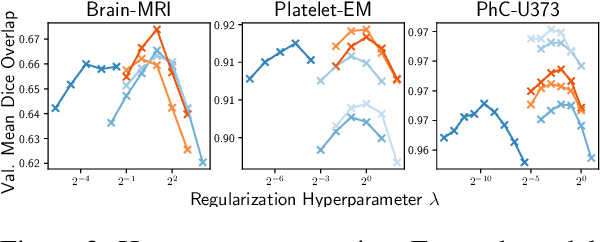
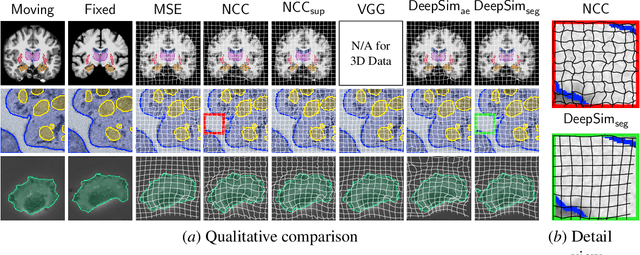
We propose a semantic similarity metric for image registration. Existing metrics like Euclidean Distance or Normalized Cross-Correlation focus on aligning intensity values, giving difficulties with low intensity contrast or noise. Our approach learns dataset-specific features that drive the optimization of a learning-based registration model. We train both an unsupervised approach using an auto-encoder, and a semi-supervised approach using supplemental segmentation data to extract semantic features for image registration. Comparing to existing methods across multiple image modalities and applications, we achieve consistently high registration accuracy. A learned invariance to noise gives smoother transformations on low-quality images.
Is segmentation uncertainty useful?
Mar 30, 2021
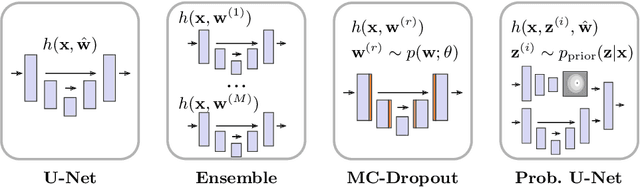
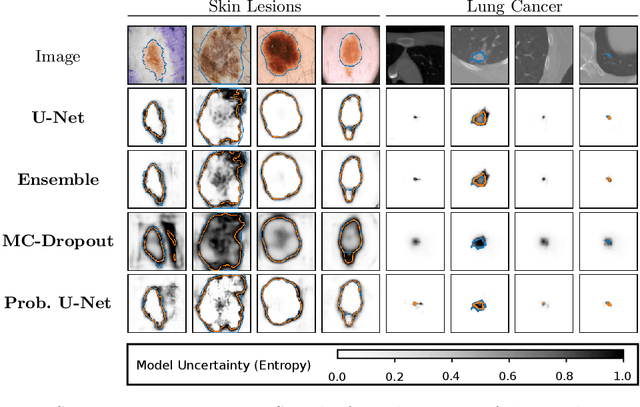
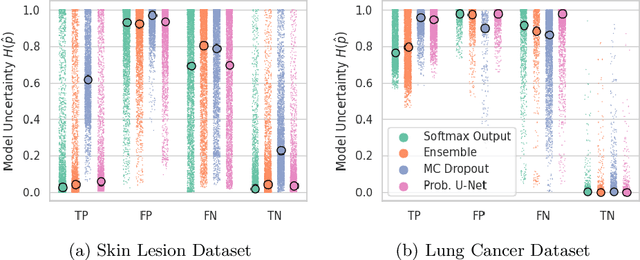
Probabilistic image segmentation encodes varying prediction confidence and inherent ambiguity in the segmentation problem. While different probabilistic segmentation models are designed to capture different aspects of segmentation uncertainty and ambiguity, these modelling differences are rarely discussed in the context of applications of uncertainty. We consider two common use cases of segmentation uncertainty, namely assessment of segmentation quality and active learning. We consider four established strategies for probabilistic segmentation, discuss their modelling capabilities, and investigate their performance in these two tasks. We find that for all models and both tasks, returned uncertainty correlates positively with segmentation error, but does not prove to be useful for active learning.
Multimodal Variational Autoencoders for Semi-Supervised Learning: In Defense of Product-of-Experts
Jan 18, 2021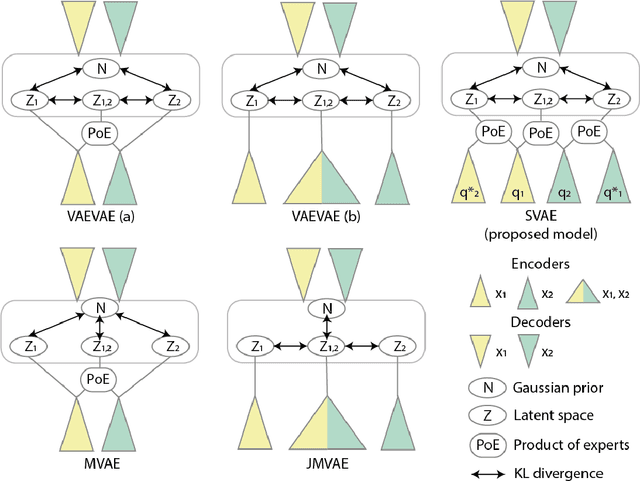
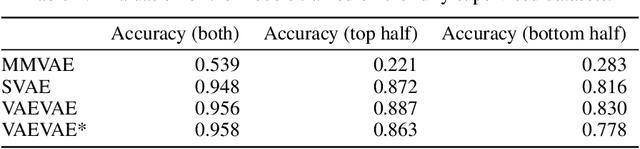

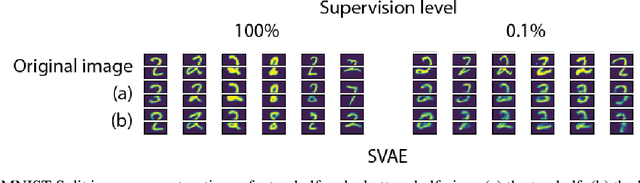
Multimodal generative models should be able to learn a meaningful latent representation that enables a coherent joint generation of all modalities (e.g., images and text). Many applications also require the ability to accurately sample modalities conditioned on observations of a subset of the modalities. Often not all modalities may be observed for all training data points, so semi-supervised learning should be possible. In this study, we evaluate a family of product-of-experts (PoE) based variational autoencoders that have these desired properties. We include a novel PoE based architecture and training procedure. An empirical evaluation shows that the PoE based models can outperform an additive mixture-of-experts (MoE) approach. Our experiments support the intuition that PoE models are more suited for a conjunctive combination of modalities while MoEs are more suited for a disjunctive fusion.
DeepSim: Semantic similarity metrics for learned image registration
Nov 11, 2020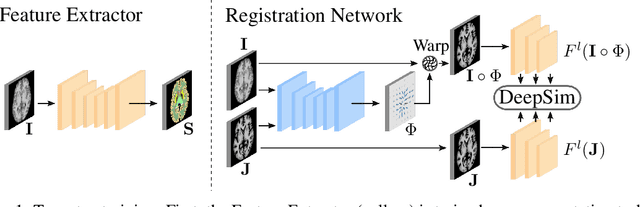
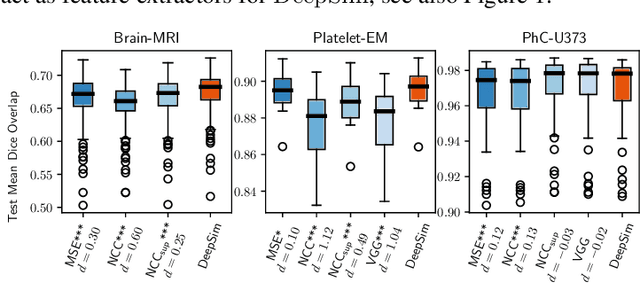
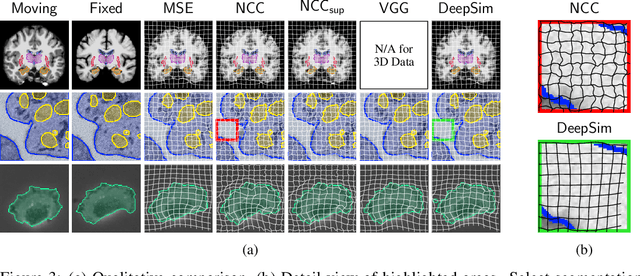
We propose a semantic similarity metric for image registration. Existing metrics like euclidean distance or normalized cross-correlation focus on aligning intensity values, giving difficulties with low intensity contrast or noise. Our semantic approach learns dataset-specific features that drive the optimization of a learning-based registration model. Comparing to existing unsupervised and supervised methods across multiple image modalities and applications, we achieve consistently high registration accuracy and faster convergence than state of the art, and the learned invariance to noise gives smoother transformations on low-quality images.
Convergence Analysis of the Hessian Estimation Evolution Strategy
Sep 06, 2020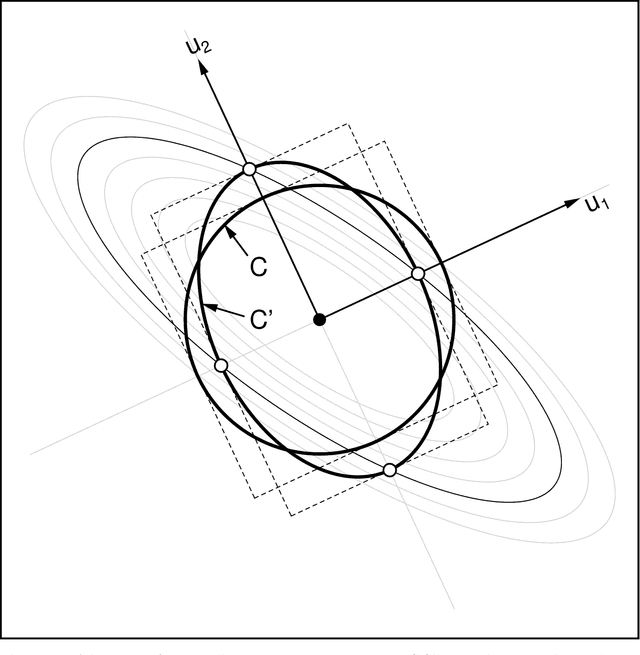
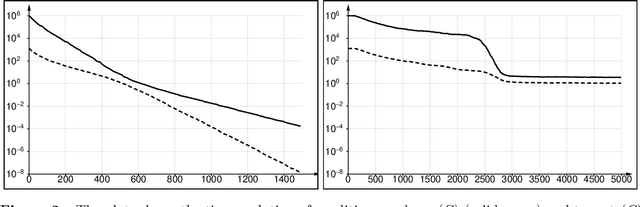
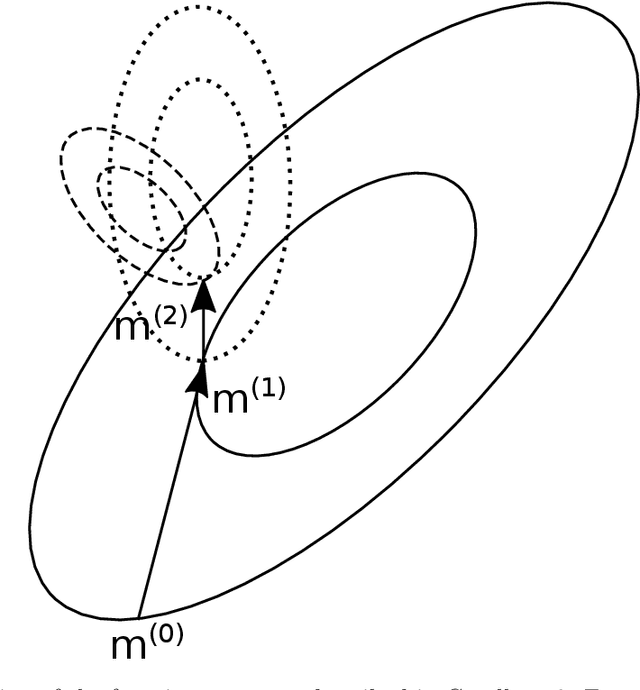
The class of algorithms called Hessian Estimation Evolution Strategies (HE-ESs) update the covariance matrix of their sampling distribution by directly estimating the curvature of the objective function. The approach is practically efficient, as attested by respectable performance on the BBOB testbed, even on rather irregular functions. In this paper we formally prove two strong guarantees for the (1+4)-HE-ES, a minimal elitist member of the family: stability of the covariance matrix update, and as a consequence, linear convergence on all convex quadratic problems at a rate that is independent of the problem instance.