 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCI-Bench: Benchmarking Contextual Integrity of AI Assistants on Synthetic Data
Sep 20, 2024



Advances in generative AI point towards a new era of personalized applications that perform diverse tasks on behalf of users. While general AI assistants have yet to fully emerge, their potential to share personal data raises significant privacy challenges. This paper introduces CI-Bench, a comprehensive synthetic benchmark for evaluating the ability of AI assistants to protect personal information during model inference. Leveraging the Contextual Integrity framework, our benchmark enables systematic assessment of information flow across important context dimensions, including roles, information types, and transmission principles. We present a novel, scalable, multi-step synthetic data pipeline for generating natural communications, including dialogues and emails. Unlike previous work with smaller, narrowly focused evaluations, we present a novel, scalable, multi-step data pipeline that synthetically generates natural communications, including dialogues and emails, which we use to generate 44 thousand test samples across eight domains. Additionally, we formulate and evaluate a naive AI assistant to demonstrate the need for further study and careful training towards personal assistant tasks. We envision CI-Bench as a valuable tool for guiding future language model development, deployment, system design, and dataset construction, ultimately contributing to the development of AI assistants that align with users' privacy expectations.
RLPF: Reinforcement Learning from Prediction Feedback for User Summarization with LLMs
Sep 06, 2024



LLM-powered personalization agent systems employ Large Language Models (LLMs) to predict users' behavior from their past activities. However, their effectiveness often hinges on the ability to effectively leverage extensive, long user historical data due to its inherent noise and length of such data. Existing pretrained LLMs may generate summaries that are concise but lack the necessary context for downstream tasks, hindering their utility in personalization systems. To address these challenges, we introduce Reinforcement Learning from Prediction Feedback (RLPF). RLPF fine-tunes LLMs to generate concise, human-readable user summaries that are optimized for downstream task performance. By maximizing the usefulness of the generated summaries, RLPF effectively distills extensive user history data while preserving essential information for downstream tasks. Our empirical evaluation demonstrates significant improvements in both extrinsic downstream task utility and intrinsic summary quality, surpassing baseline methods by up to 22% on downstream task performance and achieving an up to 84.59% win rate on Factuality, Abstractiveness, and Readability. RLPF also achieves a remarkable 74% reduction in context length while improving performance on 16 out of 19 unseen tasks and/or datasets, showcasing its generalizability. This approach offers a promising solution for enhancing LLM personalization by effectively transforming long, noisy user histories into informative and human-readable representations.
UserSumBench: A Benchmark Framework for Evaluating User Summarization Approaches
Aug 30, 2024



Large language models (LLMs) have shown remarkable capabilities in generating user summaries from a long list of raw user activity data. These summaries capture essential user information such as preferences and interests, and therefore are invaluable for LLM-based personalization applications, such as explainable recommender systems. However, the development of new summarization techniques is hindered by the lack of ground-truth labels, the inherent subjectivity of user summaries, and human evaluation which is often costly and time-consuming. To address these challenges, we introduce \UserSumBench, a benchmark framework designed to facilitate iterative development of LLM-based summarization approaches. This framework offers two key components: (1) A reference-free summary quality metric. We show that this metric is effective and aligned with human preferences across three diverse datasets (MovieLens, Yelp and Amazon Review). (2) A novel robust summarization method that leverages time-hierarchical summarizer and self-critique verifier to produce high-quality summaries while eliminating hallucination. This method serves as a strong baseline for further innovation in summarization techniques.
User-LLM: Efficient LLM Contextualization with User Embeddings
Feb 21, 2024Large language models (LLMs) have revolutionized natural language processing. However, effectively incorporating complex and potentially noisy user interaction data remains a challenge. To address this, we propose User-LLM, a novel framework that leverages user embeddings to contextualize LLMs. These embeddings, distilled from diverse user interactions using self-supervised pretraining, capture latent user preferences and their evolution over time. We integrate these user embeddings with LLMs through cross-attention and soft-prompting, enabling LLMs to dynamically adapt to user context. Our comprehensive experiments on MovieLens, Amazon Review, and Google Local Review datasets demonstrate significant performance gains across various tasks. Notably, our approach outperforms text-prompt-based contextualization on long sequence tasks and tasks that require deep user understanding while being computationally efficient. We further incorporate Perceiver layers to streamline the integration between user encoders and LLMs, reducing computational demands.
Massively Scalable Inverse Reinforcement Learning in Google Maps
May 24, 2023
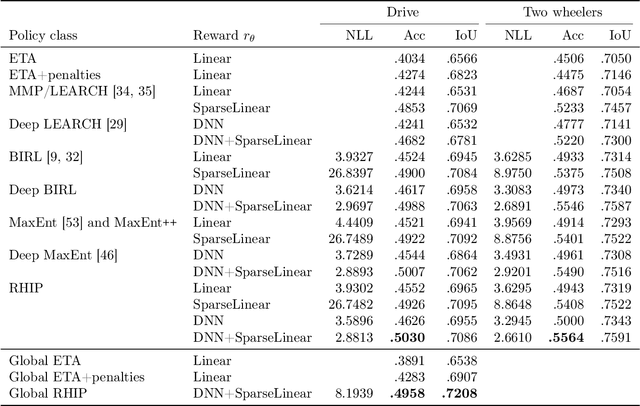
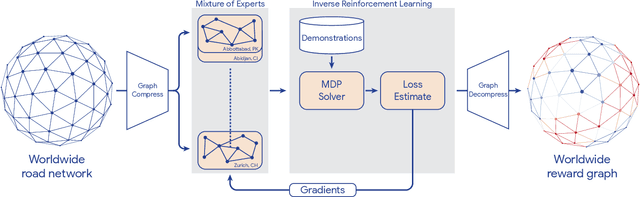

Optimizing for humans' latent preferences is a grand challenge in route recommendation, where globally-scalable solutions remain an open problem. Although past work created increasingly general solutions for the application of inverse reinforcement learning (IRL), these have not been successfully scaled to world-sized MDPs, large datasets, and highly parameterized models; respectively hundreds of millions of states, trajectories, and parameters. In this work, we surpass previous limitations through a series of advancements focused on graph compression, parallelization, and problem initialization based on dominant eigenvectors. We introduce Receding Horizon Inverse Planning (RHIP), which generalizes existing work and enables control of key performance trade-offs via its planning horizon. Our policy achieves a 16-24% improvement in global route quality, and, to our knowledge, represents the largest instance of IRL in a real-world setting to date. Our results show critical benefits to more sustainable modes of transportation (e.g. two-wheelers), where factors beyond journey time (e.g. route safety) play a substantial role. We conclude with ablations of key components, negative results on state-of-the-art eigenvalue solvers, and identify future opportunities to improve scalability via IRL-specific batching strategies.
Smartphone-based Hard-braking Event Detection at Scale for Road Safety Services
Feb 04, 2022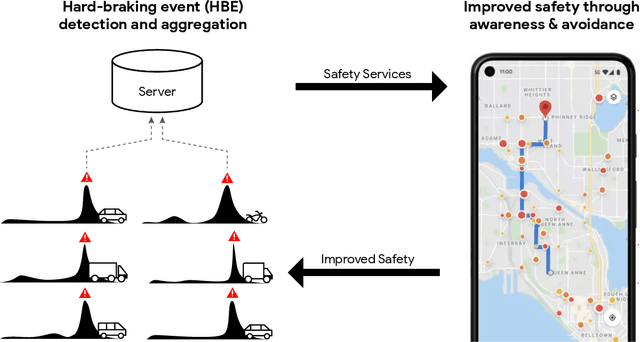
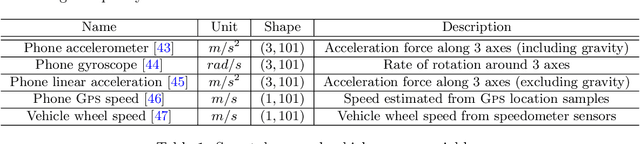
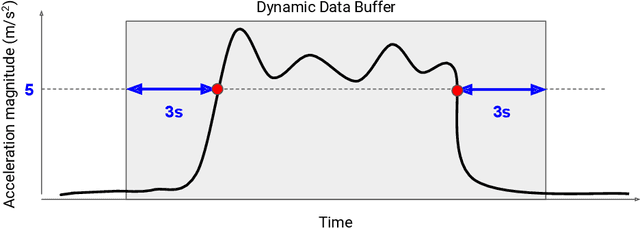

Road crashes are the sixth leading cause of lost disability-adjusted life-years (DALYs) worldwide. One major challenge in traffic safety research is the sparsity of crashes, which makes it difficult to achieve a fine-grain understanding of crash causations and predict future crash risk in a timely manner. Hard-braking events have been widely used as a safety surrogate due to their relatively high prevalence and ease of detection with embedded vehicle sensors. As an alternative to using sensors fixed in vehicles, this paper presents a scalable approach for detecting hard-braking events using the kinematics data collected from smartphone sensors. We train a Transformer-based machine learning model for hard-braking event detection using concurrent sensor readings from smartphones and vehicle sensors from drivers who connect their phone to the vehicle while navigating in Google Maps. The detection model shows superior performance with a $0.83$ Area under the Precision-Recall Curve (PR-AUC), which is $3.8\times$better than a GPS speed-based heuristic model, and $166.6\times$better than an accelerometer-based heuristic model. The detected hard-braking events are strongly correlated with crashes from publicly available datasets, supporting their use as a safety surrogate. In addition, we conduct model fairness and selection bias evaluation to ensure that the safety benefits are equally shared. The developed methodology can benefit many safety applications such as identifying safety hot spots at road network level, evaluating the safety of new user interfaces, as well as using routing to improve traffic safety.
Examining COVID-19 Forecasting using Spatio-Temporal Graph Neural Networks
Jul 06, 2020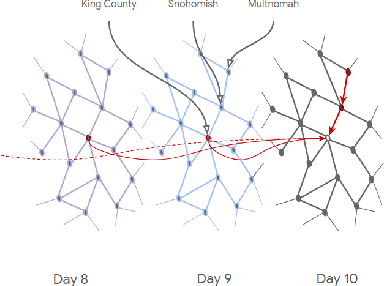
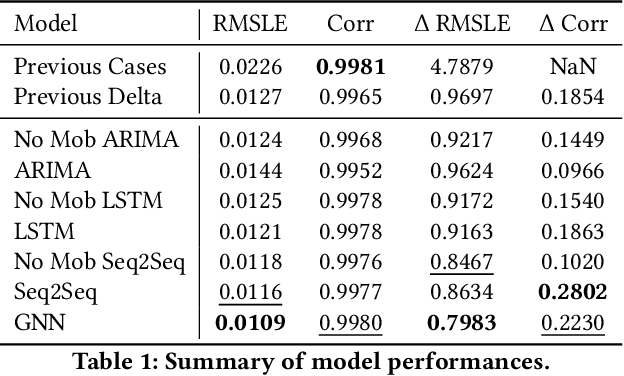
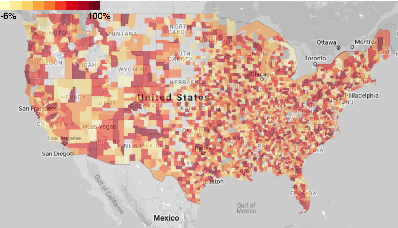
In this work, we examine a novel forecasting approach for COVID-19 case prediction that uses Graph Neural Networks and mobility data. In contrast to existing time series forecasting models, the proposed approach learns from a single large-scale spatio-temporal graph, where nodes represent the region-level human mobility, spatial edges represent the human mobility based inter-region connectivity, and temporal edges represent node features through time. We evaluate this approach on the US county level COVID-19 dataset, and demonstrate that the rich spatial and temporal information leveraged by the graph neural network allows the model to learn complex dynamics. We show a 6% reduction of RMSLE and an absolute Pearson Correlation improvement from 0.9978 to 0.998 compared to the best performing baseline models. This novel source of information combined with graph based deep learning approaches can be a powerful tool to understand the spread and evolution of COVID-19. We encourage others to further develop a novel modeling paradigm for infectious disease based on GNNs and high resolution mobility data.
Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case
Jan 23, 2020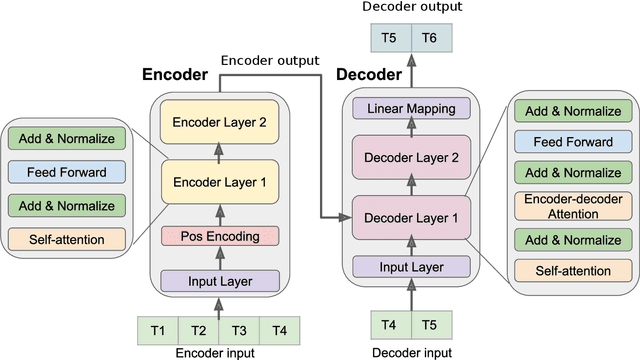


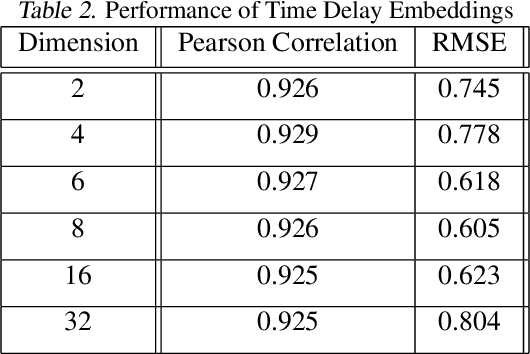
In this paper, we present a new approach to time series forecasting. Time series data are prevalent in many scientific and engineering disciplines. Time series forecasting is a crucial task in modeling time series data, and is an important area of machine learning. In this work we developed a novel method that employs Transformer-based machine learning models to forecast time series data. This approach works by leveraging self-attention mechanisms to learn complex patterns and dynamics from time series data. Moreover, it is a generic framework and can be applied to univariate and multivariate time series data, as well as time series embeddings. Using influenza-like illness (ILI) forecasting as a case study, we show that the forecasting results produced by our approach are favorably comparable to the state-of-the-art.