 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
Generalizing Verifiable Instruction Following
Jul 03, 2025A crucial factor for successful human and AI interaction is the ability of language models or chatbots to follow human instructions precisely. A common feature of instructions are output constraints like ``only answer with yes or no" or ``mention the word `abrakadabra' at least 3 times" that the user adds to craft a more useful answer. Even today's strongest models struggle with fulfilling such constraints. We find that most models strongly overfit on a small set of verifiable constraints from the benchmarks that test these abilities, a skill called precise instruction following, and are not able to generalize well to unseen output constraints. We introduce a new benchmark, IFBench, to evaluate precise instruction following generalization on 58 new, diverse, and challenging verifiable out-of-domain constraints. In addition, we perform an extensive analysis of how and on what data models can be trained to improve precise instruction following generalization. Specifically, we carefully design constraint verification modules and show that reinforcement learning with verifiable rewards (RLVR) significantly improves instruction following. In addition to IFBench, we release 29 additional new hand-annotated training constraints and verification functions, RLVR training prompts, and code.
2 OLMo 2 Furious
Dec 31, 2024



We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from T\"ulu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly -- models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
TÜLU 3: Pushing Frontiers in Open Language Model Post-Training
Nov 22, 2024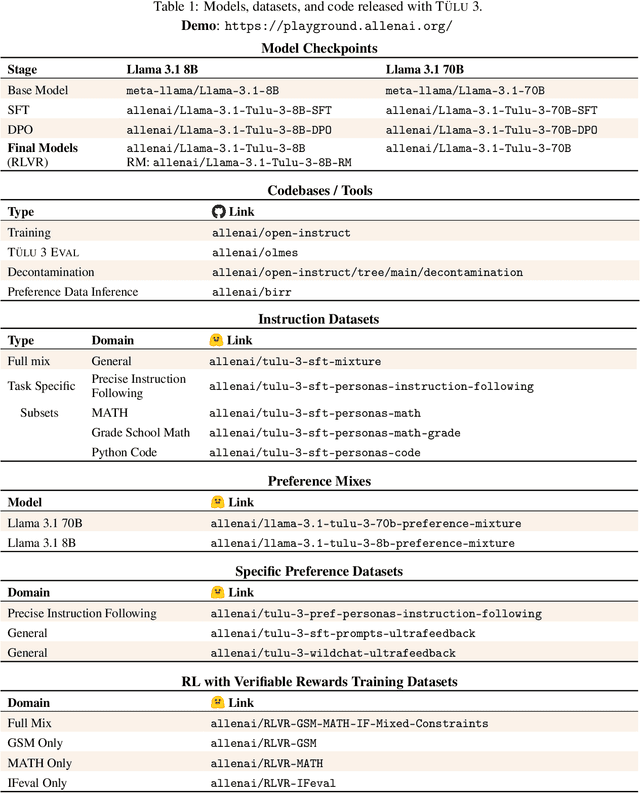



Language model post-training is applied to refine behaviors and unlock new skills across a wide range of recent language models, but open recipes for applying these techniques lag behind proprietary ones. The underlying training data and recipes for post-training are simultaneously the most important pieces of the puzzle and the portion with the least transparency. To bridge this gap, we introduce T\"ULU 3, a family of fully-open state-of-the-art post-trained models, alongside its data, code, and training recipes, serving as a comprehensive guide for modern post-training techniques. T\"ULU 3, which builds on Llama 3.1 base models, achieves results surpassing the instruct versions of Llama 3.1, Qwen 2.5, Mistral, and even closed models such as GPT-4o-mini and Claude 3.5-Haiku. The training algorithms for our models include supervised finetuning (SFT), Direct Preference Optimization (DPO), and a novel method we call Reinforcement Learning with Verifiable Rewards (RLVR). With T\"ULU 3, we introduce a multi-task evaluation scheme for post-training recipes with development and unseen evaluations, standard benchmark implementations, and substantial decontamination of existing open datasets on said benchmarks. We conclude with analysis and discussion of training methods that did not reliably improve performance. In addition to the T\"ULU 3 model weights and demo, we release the complete recipe -- including datasets for diverse core skills, a robust toolkit for data curation and evaluation, the training code and infrastructure, and, most importantly, a detailed report for reproducing and further adapting the T\"ULU 3 approach to more domains.
QuRating: Selecting High-Quality Data for Training Language Models
Feb 15, 2024Selecting high-quality pre-training data is important for creating capable language models, but existing methods rely on simple heuristics. We introduce QuRating, a method for selecting pre-training data that captures the abstract qualities of texts which humans intuitively perceive. In this paper, we investigate four qualities - writing style, required expertise, facts & trivia, and educational value. We find that LLMs are able to discern these qualities and observe that they are better at making pairwise judgments of texts than at rating the quality of a text directly. We train a QuRater model to learn scalar ratings from pairwise judgments, and use it to annotate a 260B training corpus with quality ratings for each of the four criteria. In our experiments, we select 30B tokens according to the different quality ratings and train 1.3B-parameter language models on the selected data. We find that it is important to balance quality and diversity, as selecting only the highest-rated documents leads to poor results. When we sample using quality ratings as logits over documents, our models achieve lower perplexity and stronger in-context learning performance than baselines. Beyond data selection, we use the quality ratings to construct a training curriculum which improves performance without changing the training dataset. We extensively analyze the quality ratings and discuss their characteristics, biases, and wider implications.