 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidence-Grounded Subspecialty Reasoning: Evaluating a Curated Clinical Intelligence Layer on the 2025 Endocrinology Board-Style Examination
Feb 17, 2026Background: Large language models have demonstrated strong performance on general medical examinations, but subspecialty clinical reasoning remains challenging due to rapidly evolving guidelines and nuanced evidence hierarchies. Methods: We evaluated January Mirror, an evidence-grounded clinical reasoning system, against frontier LLMs (GPT-5, GPT-5.2, Gemini-3-Pro) on a 120-question endocrinology board-style examination. Mirror integrates a curated endocrinology and cardiometabolic evidence corpus with a structured reasoning architecture to generate evidence-linked outputs. Mirror operated under a closed-evidence constraint without external retrieval. Comparator LLMs had real-time web access to guidelines and primary literature. Results: Mirror achieved 87.5% accuracy (105/120; 95% CI: 80.4-92.3%), exceeding a human reference of 62.3% and frontier LLMs including GPT-5.2 (74.6%), GPT-5 (74.0%), and Gemini-3-Pro (69.8%). On the 30 most difficult questions (human accuracy less than 50%), Mirror achieved 76.7% accuracy. Top-2 accuracy was 92.5% for Mirror versus 85.25% for GPT-5.2. Conclusions: Mirror provided evidence traceability: 74.2% of outputs cited at least one guideline-tier source, with 100% citation accuracy on manual verification. Curated evidence with explicit provenance can outperform unconstrained web retrieval for subspecialty clinical reasoning and supports auditability for clinical deployment.
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
VeriFact: Verifying Facts in LLM-Generated Clinical Text with Electronic Health Records
Jan 28, 2025Methods to ensure factual accuracy of text generated by large language models (LLM) in clinical medicine are lacking. VeriFact is an artificial intelligence system that combines retrieval-augmented generation and LLM-as-a-Judge to verify whether LLM-generated text is factually supported by a patient's medical history based on their electronic health record (EHR). To evaluate this system, we introduce VeriFact-BHC, a new dataset that decomposes Brief Hospital Course narratives from discharge summaries into a set of simple statements with clinician annotations for whether each statement is supported by the patient's EHR clinical notes. Whereas highest agreement between clinicians was 88.5%, VeriFact achieves up to 92.7% agreement when compared to a denoised and adjudicated average human clinican ground truth, suggesting that VeriFact exceeds the average clinician's ability to fact-check text against a patient's medical record. VeriFact may accelerate the development of LLM-based EHR applications by removing current evaluation bottlenecks.
Large Language Model Capabilities in Perioperative Risk Prediction and Prognostication
Jan 03, 2024We investigate whether general-domain large language models such as GPT-4 Turbo can perform risk stratification and predict post-operative outcome measures using a description of the procedure and a patient's clinical notes derived from the electronic health record. We examine predictive performance on 8 different tasks: prediction of ASA Physical Status Classification, hospital admission, ICU admission, unplanned admission, hospital mortality, PACU Phase 1 duration, hospital duration, and ICU duration. Few-shot and chain-of-thought prompting improves predictive performance for several of the tasks. We achieve F1 scores of 0.50 for ASA Physical Status Classification, 0.81 for ICU admission, and 0.86 for hospital mortality. Performance on duration prediction tasks were universally poor across all prompt strategies. Current generation large language models can assist clinicians in perioperative risk stratification on classification tasks and produce high-quality natural language summaries and explanations.
MedAlign: A Clinician-Generated Dataset for Instruction Following with Electronic Medical Records
Aug 27, 2023
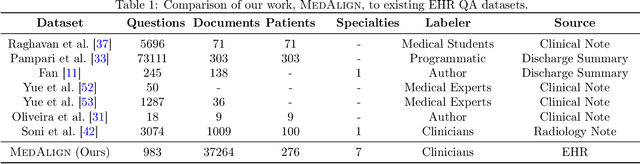


The ability of large language models (LLMs) to follow natural language instructions with human-level fluency suggests many opportunities in healthcare to reduce administrative burden and improve quality of care. However, evaluating LLMs on realistic text generation tasks for healthcare remains challenging. Existing question answering datasets for electronic health record (EHR) data fail to capture the complexity of information needs and documentation burdens experienced by clinicians. To address these challenges, we introduce MedAlign, a benchmark dataset of 983 natural language instructions for EHR data. MedAlign is curated by 15 clinicians (7 specialities), includes clinician-written reference responses for 303 instructions, and provides 276 longitudinal EHRs for grounding instruction-response pairs. We used MedAlign to evaluate 6 general domain LLMs, having clinicians rank the accuracy and quality of each LLM response. We found high error rates, ranging from 35% (GPT-4) to 68% (MPT-7B-Instruct), and an 8.3% drop in accuracy moving from 32k to 2k context lengths for GPT-4. Finally, we report correlations between clinician rankings and automated natural language generation metrics as a way to rank LLMs without human review. We make MedAlign available under a research data use agreement to enable LLM evaluations on tasks aligned with clinician needs and preferences.
Feature-weighted elastic net: using "features of features" for better prediction
Jun 02, 2020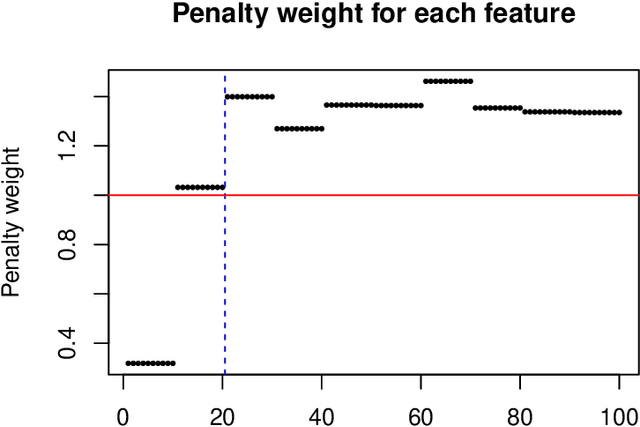
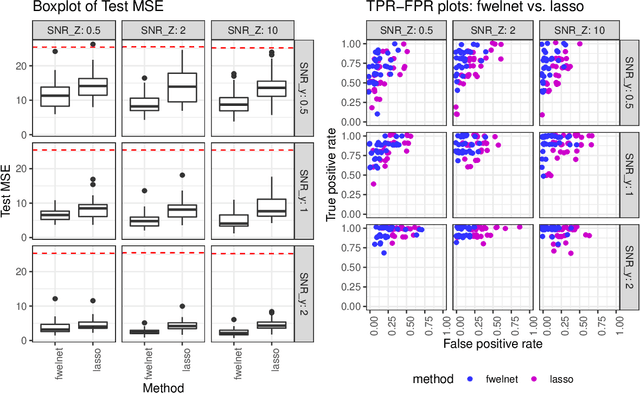
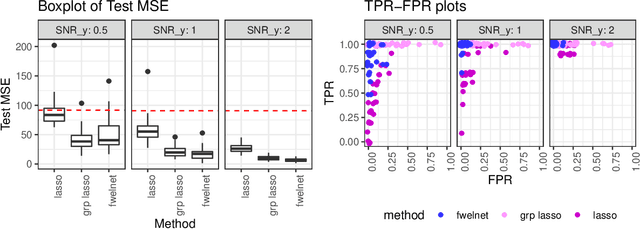
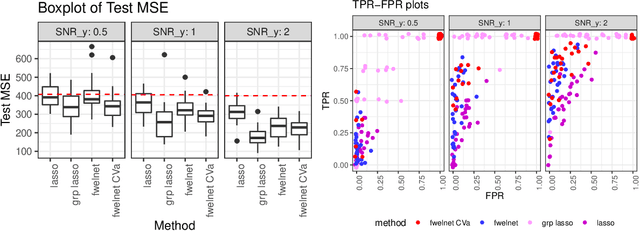
In some supervised learning settings, the practitioner might have additional information on the features used for prediction. We propose a new method which leverages this additional information for better prediction. The method, which we call the feature-weighted elastic net ("fwelnet"), uses these "features of features" to adapt the relative penalties on the feature coefficients in the elastic net penalty. In our simulations, fwelnet outperforms the lasso in terms of test mean squared error and usually gives an improvement in true positive rate or false positive rate for feature selection. We also apply this method to early prediction of preeclampsia, where fwelnet outperforms the lasso in terms of 10-fold cross-validated area under the curve (0.86 vs. 0.80). We also provide a connection between fwelnet and the group lasso and suggest how fwelnet might be used for multi-task learning.