 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEAR 2021: Holistic Evaluation of Audio Representations
Mar 26, 2022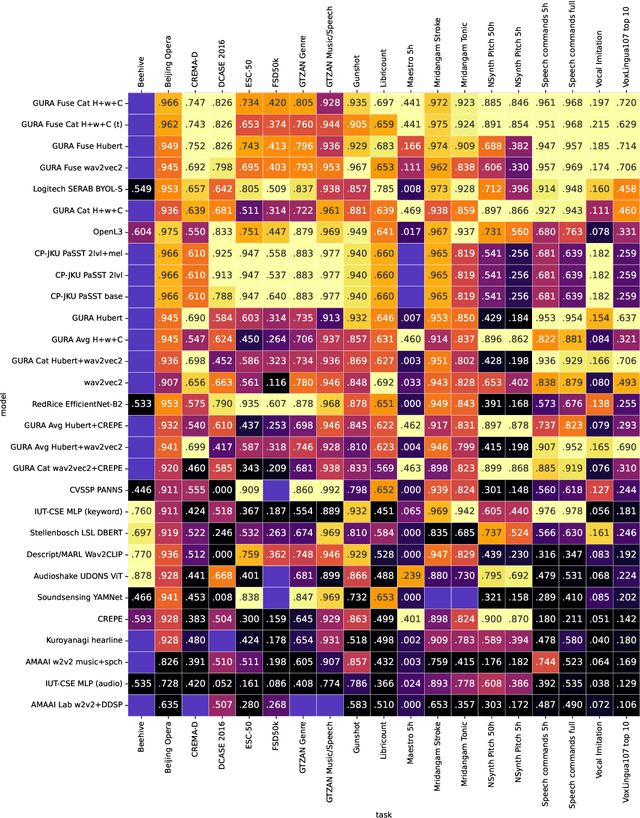
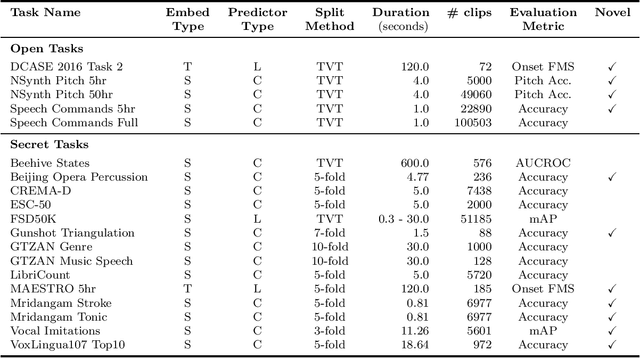

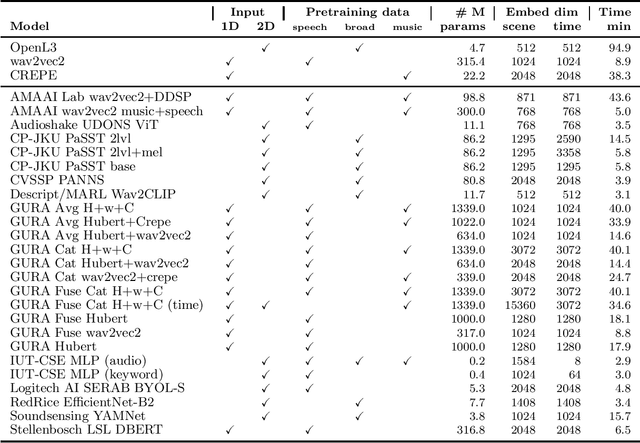
What audio embedding approach generalizes best to a wide range of downstream tasks across a variety of everyday domains without fine-tuning? The aim of the HEAR 2021 NeurIPS challenge is to develop a general-purpose audio representation that provides a strong basis for learning in a wide variety of tasks and scenarios. HEAR 2021 evaluates audio representations using a benchmark suite across a variety of domains, including speech, environmental sound, and music. In the spirit of shared exchange, each participant submitted an audio embedding model following a common API that is general-purpose, open-source, and freely available to use. Twenty-nine models by thirteen external teams were evaluated on nineteen diverse downstream tasks derived from sixteen datasets. Open evaluation code, submitted models and datasets are key contributions, enabling comprehensive and reproducible evaluation, as well as previously impossible longitudinal studies. It still remains an open question whether one single general-purpose audio representation can perform as holistically as the human ear.
Experience Grounds Language
Apr 21, 2020Successful linguistic communication relies on a shared experience of the world, and it is this shared experience that makes utterances meaningful. Despite the incredible effectiveness of language processing models trained on text alone, today's best systems still make mistakes that arise from a failure to relate language to the physical world it describes and to the social interactions it facilitates. Natural Language Processing is a diverse field, and progress throughout its development has come from new representational theories, modeling techniques, data collection paradigms, and tasks. We posit that the present success of representation learning approaches trained on large text corpora can be deeply enriched from the parallel tradition of research on the contextual and social nature of language. In this article, we consider work on the contextual foundations of language: grounding, embodiment, and social interaction. We describe a brief history and possible progression of how contextual information can factor into our representations, with an eye towards how this integration can move the field forward and where it is currently being pioneered. We believe this framing will serve as a roadmap for truly contextual language understanding.
Deep Neural Networks Rival the Representation of Primate IT Cortex for Core Visual Object Recognition
Jun 12, 2014
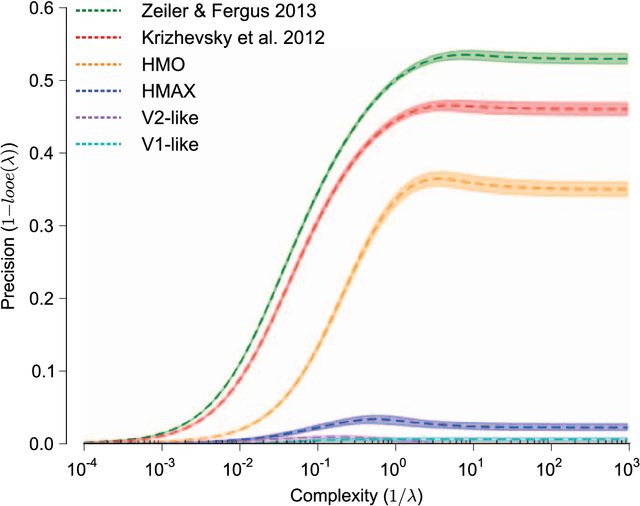
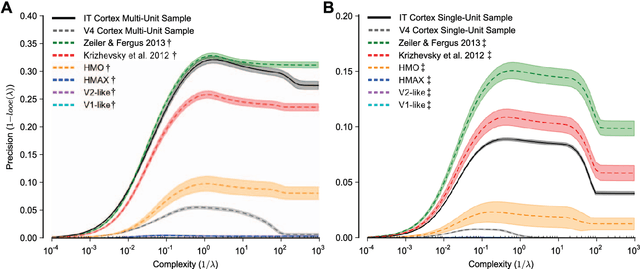
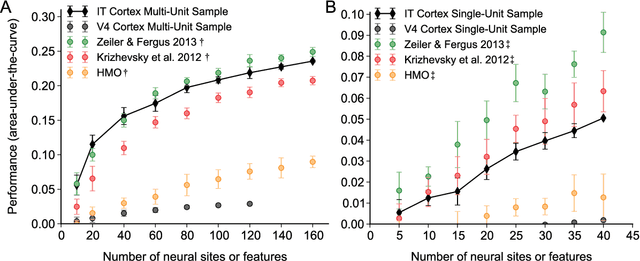
The primate visual system achieves remarkable visual object recognition performance even in brief presentations and under changes to object exemplar, geometric transformations, and background variation (a.k.a. core visual object recognition). This remarkable performance is mediated by the representation formed in inferior temporal (IT) cortex. In parallel, recent advances in machine learning have led to ever higher performing models of object recognition using artificial deep neural networks (DNNs). It remains unclear, however, whether the representational performance of DNNs rivals that of the brain. To accurately produce such a comparison, a major difficulty has been a unifying metric that accounts for experimental limitations such as the amount of noise, the number of neural recording sites, and the number trials, and computational limitations such as the complexity of the decoding classifier and the number of classifier training examples. In this work we perform a direct comparison that corrects for these experimental limitations and computational considerations. As part of our methodology, we propose an extension of "kernel analysis" that measures the generalization accuracy as a function of representational complexity. Our evaluations show that, unlike previous bio-inspired models, the latest DNNs rival the representational performance of IT cortex on this visual object recognition task. Furthermore, we show that models that perform well on measures of representational performance also perform well on measures of representational similarity to IT and on measures of predicting individual IT multi-unit responses. Whether these DNNs rely on computational mechanisms similar to the primate visual system is yet to be determined, but, unlike all previous bio-inspired models, that possibility cannot be ruled out merely on representational performance grounds.
The Neural Representation Benchmark and its Evaluation on Brain and Machine
Jan 25, 2013
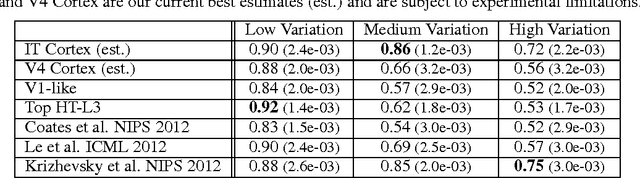
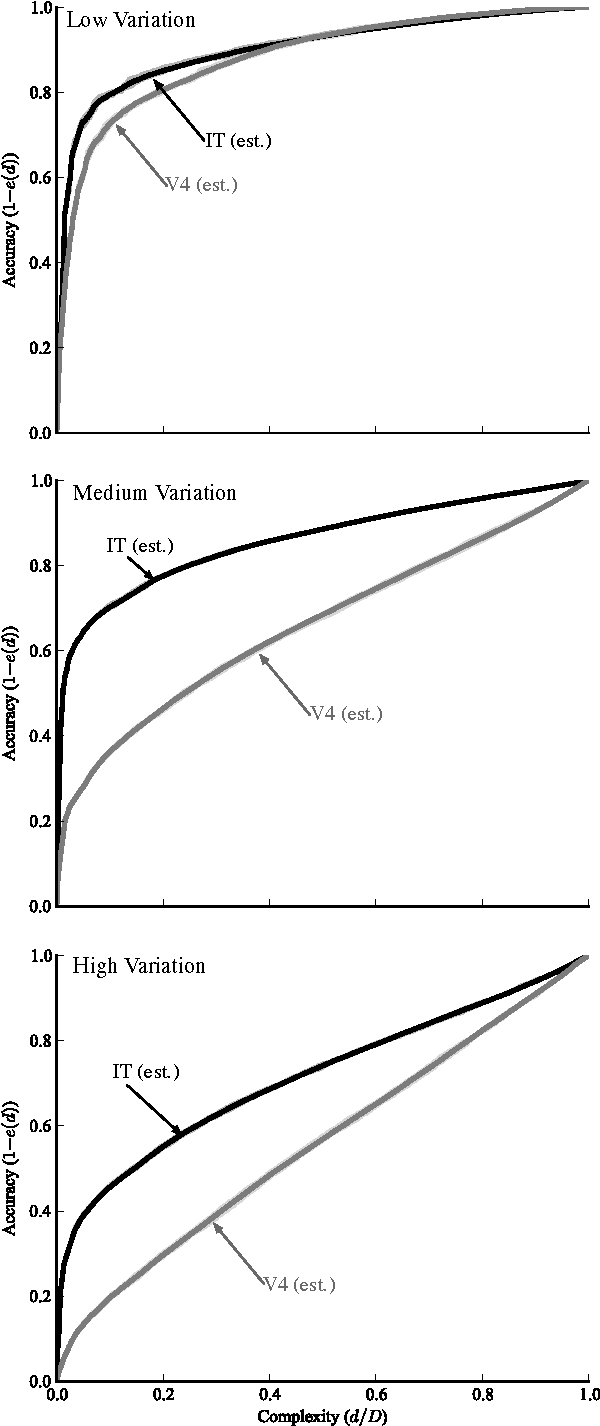
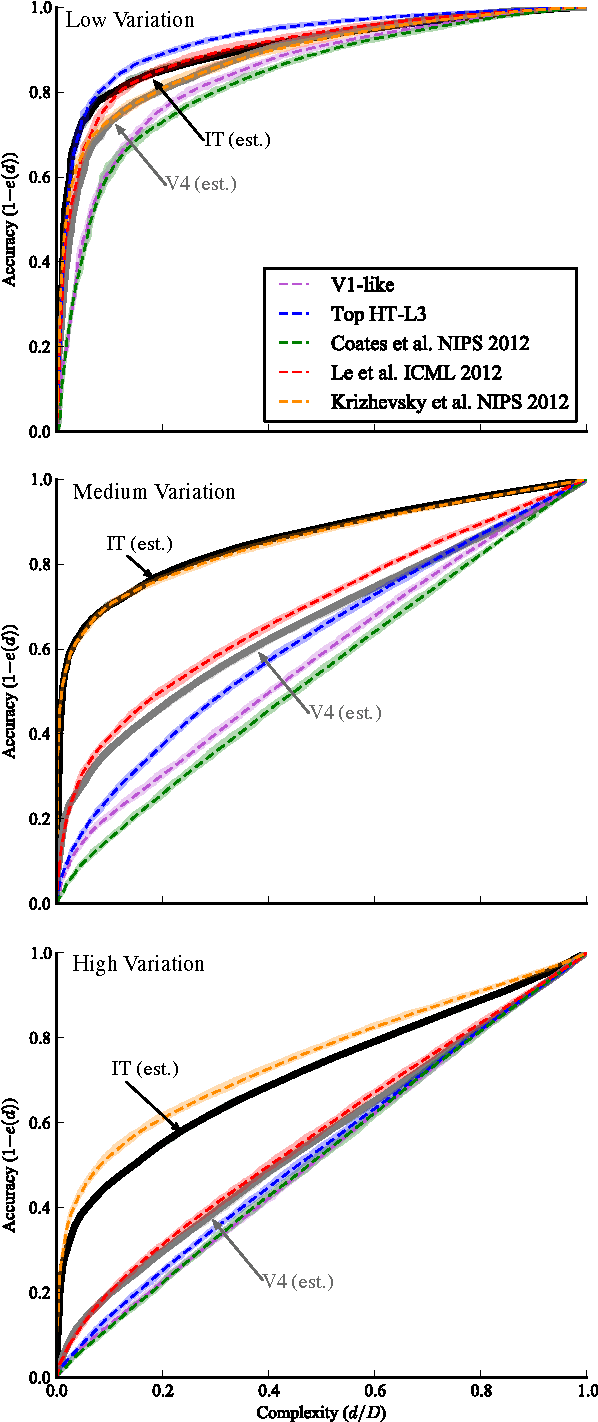
A key requirement for the development of effective learning representations is their evaluation and comparison to representations we know to be effective. In natural sensory domains, the community has viewed the brain as a source of inspiration and as an implicit benchmark for success. However, it has not been possible to directly test representational learning algorithms directly against the representations contained in neural systems. Here, we propose a new benchmark for visual representations on which we have directly tested the neural representation in multiple visual cortical areas in macaque (utilizing data from [Majaj et al., 2012]), and on which any computer vision algorithm that produces a feature space can be tested. The benchmark measures the effectiveness of the neural or machine representation by computing the classification loss on the ordered eigendecomposition of a kernel matrix [Montavon et al., 2011]. In our analysis we find that the neural representation in visual area IT is superior to visual area V4. In our analysis of representational learning algorithms, we find that three-layer models approach the representational performance of V4 and the algorithm in [Le et al., 2012] surpasses the performance of V4. Impressively, we find that a recent supervised algorithm [Krizhevsky et al., 2012] achieves performance comparable to that of IT for an intermediate level of image variation difficulty, and surpasses IT at a higher difficulty level. We believe this result represents a major milestone: it is the first learning algorithm we have found that exceeds our current estimate of IT representation performance. We hope that this benchmark will assist the community in matching the representational performance of visual cortex and will serve as an initial rallying point for further correspondence between representations derived in brains and machines.