 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Exploration with Self-Imitation Learning via Trajectory-Conditioned Policy
Jul 24, 2019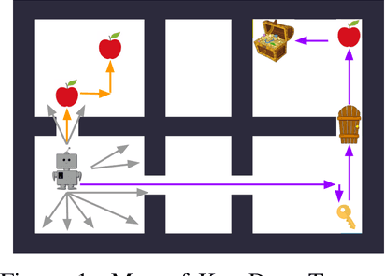
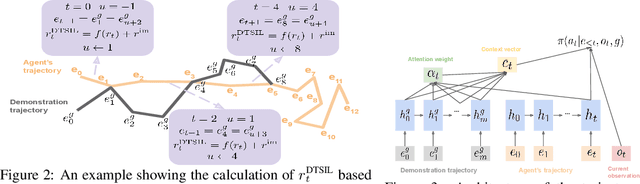
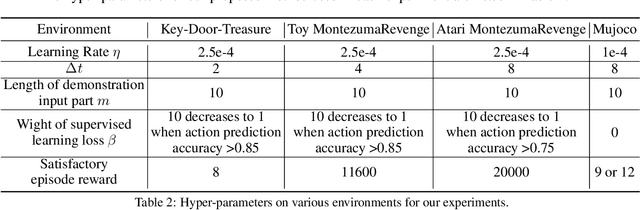
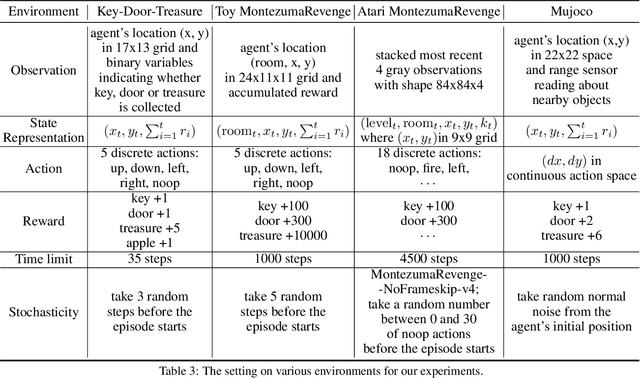
This paper proposes a method for learning a trajectory-conditioned policy to imitate diverse demonstrations from the agent's own past experiences. We demonstrate that such self-imitation drives exploration in diverse directions and increases the chance of finding a globally optimal solution in reinforcement learning problems, especially when the reward is sparse and deceptive. Our method significantly outperforms existing self-imitation learning and count-based exploration methods on various sparse-reward reinforcement learning tasks with local optima. In particular, we report a state-of-the-art score of more than 25,000 points on Montezuma's Revenge without using expert demonstrations or resetting to arbitrary states.
Contingency-Aware Exploration in Reinforcement Learning
Nov 05, 2018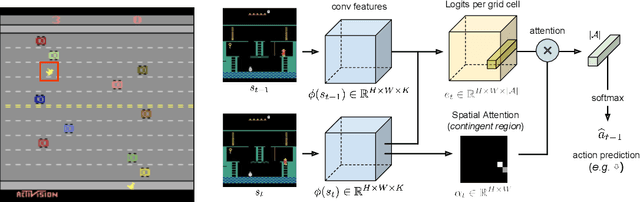
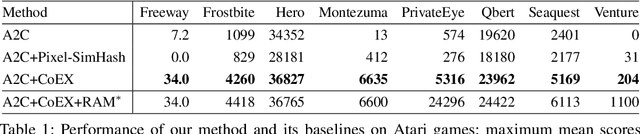
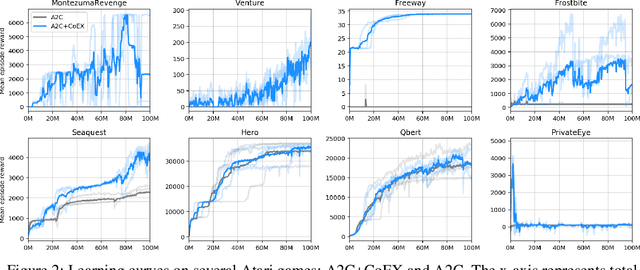
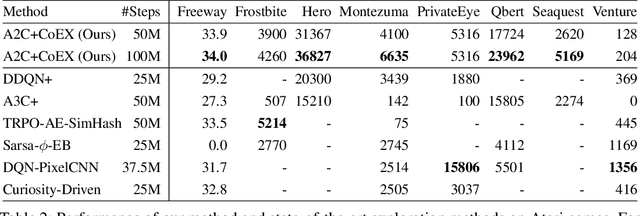
This paper investigates whether learning contingency-awareness and controllable aspects of an environment can lead to better exploration in reinforcement learning. To investigate this question, we consider an instantiation of this hypothesis evaluated on the Arcade Learning Element (ALE). In this study, we develop an attentive dynamics model (ADM) that discovers controllable elements of the observations, which are often associated with the location of the character in Atari games. The ADM is trained in a self-supervised fashion to predict the actions taken by the agent. The learned contingency information is used as a part of the state representation for exploration purposes. We demonstrate that combining A2C with count-based exploration using our representation achieves impressive results on a set of notoriously challenging Atari games due to sparse rewards. For example, we report a state-of-the-art score of >6600 points on Montezuma's Revenge without using expert demonstrations, explicit high-level information (e.g., RAM states), or supervised data. Our experiments confirm that indeed contingency-awareness is an extremely powerful concept for tackling exploration problems in reinforcement learning and opens up interesting research questions for further investigations.
A Robust Adaptive Stochastic Gradient Method for Deep Learning
Mar 02, 2017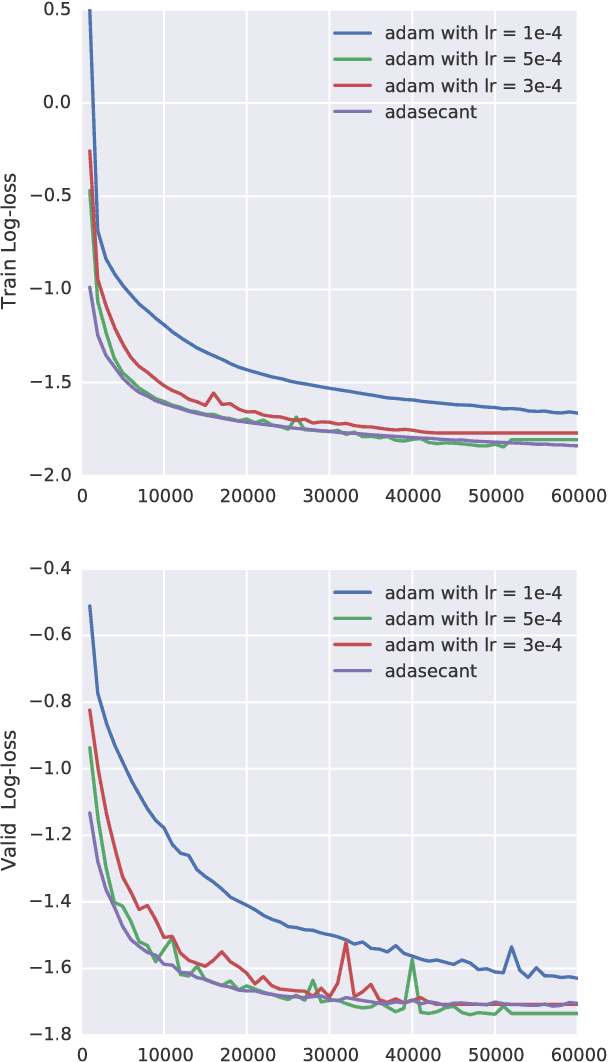

Stochastic gradient algorithms are the main focus of large-scale optimization problems and led to important successes in the recent advancement of the deep learning algorithms. The convergence of SGD depends on the careful choice of learning rate and the amount of the noise in stochastic estimates of the gradients. In this paper, we propose an adaptive learning rate algorithm, which utilizes stochastic curvature information of the loss function for automatically tuning the learning rates. The information about the element-wise curvature of the loss function is estimated from the local statistics of the stochastic first order gradients. We further propose a new variance reduction technique to speed up the convergence. In our experiments with deep neural networks, we obtained better performance compared to the popular stochastic gradient algorithms.
Mollifying Networks
Aug 17, 2016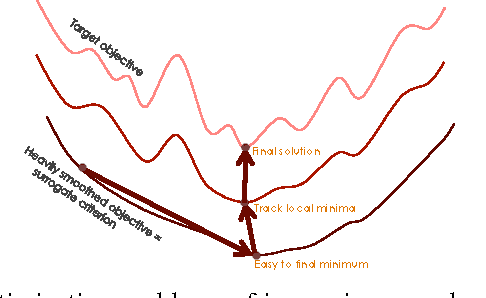

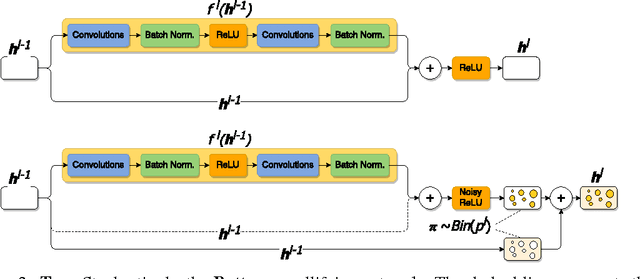
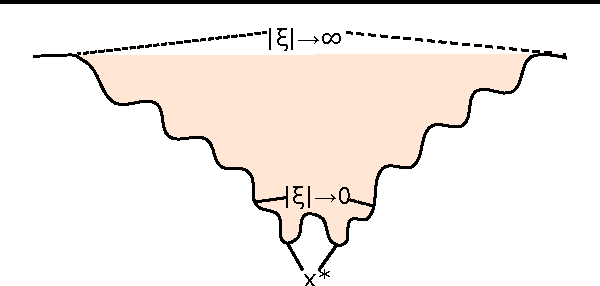
The optimization of deep neural networks can be more challenging than traditional convex optimization problems due to the highly non-convex nature of the loss function, e.g. it can involve pathological landscapes such as saddle-surfaces that can be difficult to escape for algorithms based on simple gradient descent. In this paper, we attack the problem of optimization of highly non-convex neural networks by starting with a smoothed -- or \textit{mollified} -- objective function that gradually has a more non-convex energy landscape during the training. Our proposition is inspired by the recent studies in continuation methods: similar to curriculum methods, we begin learning an easier (possibly convex) objective function and let it evolve during the training, until it eventually goes back to being the original, difficult to optimize, objective function. The complexity of the mollified networks is controlled by a single hyperparameter which is annealed during the training. We show improvements on various difficult optimization tasks and establish a relationship with recent works on continuation methods for neural networks and mollifiers.
Noisy Activation Functions
Apr 03, 2016


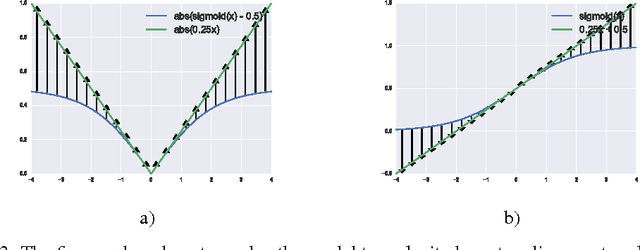
Common nonlinear activation functions used in neural networks can cause training difficulties due to the saturation behavior of the activation function, which may hide dependencies that are not visible to vanilla-SGD (using first order gradients only). Gating mechanisms that use softly saturating activation functions to emulate the discrete switching of digital logic circuits are good examples of this. We propose to exploit the injection of appropriate noise so that the gradients may flow easily, even if the noiseless application of the activation function would yield zero gradient. Large noise will dominate the noise-free gradient and allow stochastic gradient descent toexplore more. By adding noise only to the problematic parts of the activation function, we allow the optimization procedure to explore the boundary between the degenerate (saturating) and the well-behaved parts of the activation function. We also establish connections to simulated annealing, when the amount of noise is annealed down, making it easier to optimize hard objective functions. We find experimentally that replacing such saturating activation functions by noisy variants helps training in many contexts, yielding state-of-the-art or competitive results on different datasets and task, especially when training seems to be the most difficult, e.g., when curriculum learning is necessary to obtain good results.
ACDC: A Structured Efficient Linear Layer
Mar 19, 2016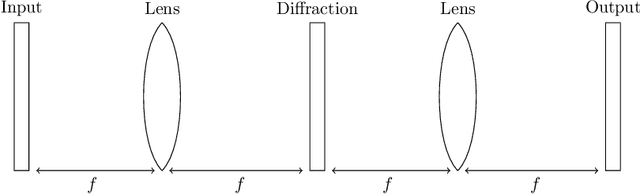
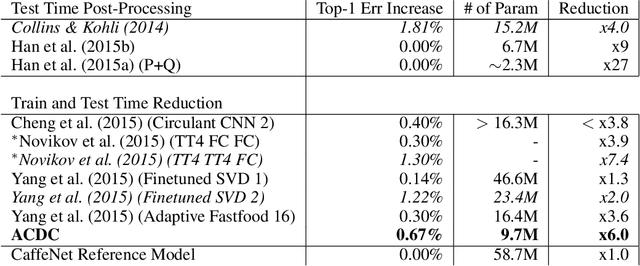
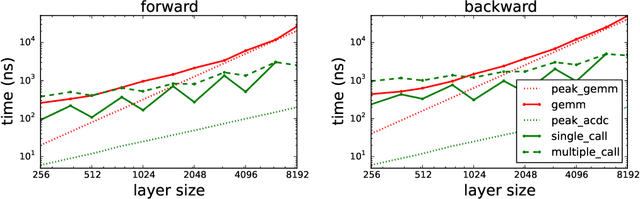
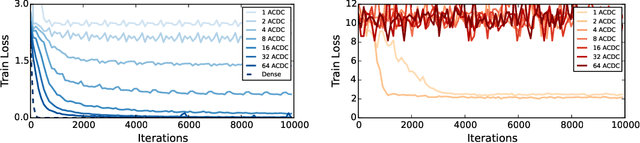
The linear layer is one of the most pervasive modules in deep learning representations. However, it requires $O(N^2)$ parameters and $O(N^2)$ operations. These costs can be prohibitive in mobile applications or prevent scaling in many domains. Here, we introduce a deep, differentiable, fully-connected neural network module composed of diagonal matrices of parameters, $\mathbf{A}$ and $\mathbf{D}$, and the discrete cosine transform $\mathbf{C}$. The core module, structured as $\mathbf{ACDC^{-1}}$, has $O(N)$ parameters and incurs $O(N log N )$ operations. We present theoretical results showing how deep cascades of ACDC layers approximate linear layers. ACDC is, however, a stand-alone module and can be used in combination with any other types of module. In our experiments, we show that it can indeed be successfully interleaved with ReLU modules in convolutional neural networks for image recognition. Our experiments also study critical factors in the training of these structured modules, including initialization and depth. Finally, this paper also provides a connection between structured linear transforms used in deep learning and the field of Fourier optics, illustrating how ACDC could in principle be implemented with lenses and diffractive elements.
A Controller-Recognizer Framework: How necessary is recognition for control?
Feb 09, 2016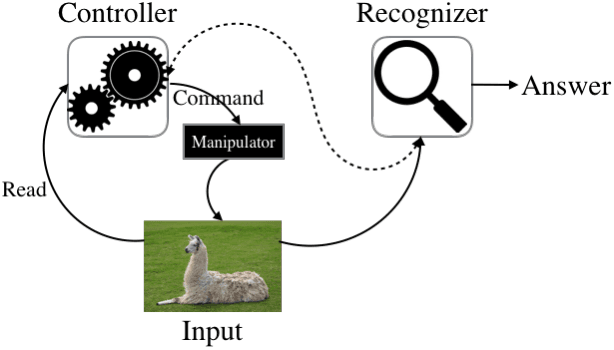
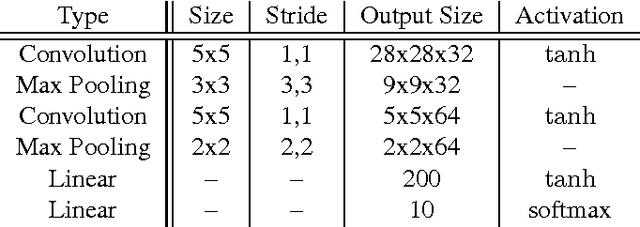
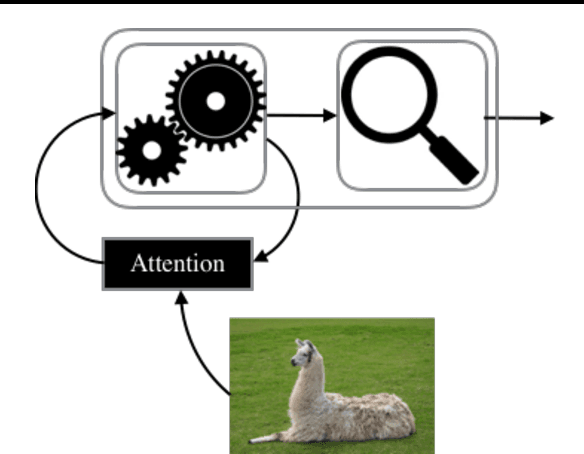
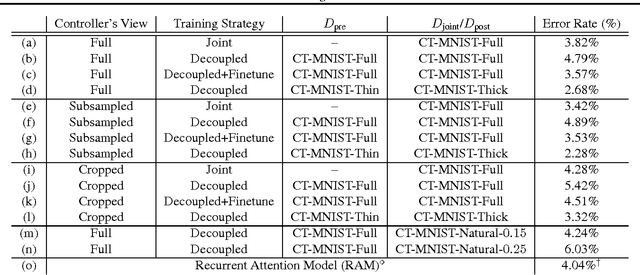
Recently there has been growing interest in building active visual object recognizers, as opposed to the usual passive recognizers which classifies a given static image into a predefined set of object categories. In this paper we propose to generalize these recently proposed end-to-end active visual recognizers into a controller-recognizer framework. A model in the controller-recognizer framework consists of a controller, which interfaces with an external manipulator, and a recognizer which classifies the visual input adjusted by the manipulator. We describe two most recently proposed controller-recognizer models: recurrent attention model and spatial transformer network as representative examples of controller-recognizer models. Based on this description we observe that most existing end-to-end controller-recognizers tightly, or completely, couple a controller and recognizer. We ask a question whether this tight coupling is necessary, and try to answer this empirically by building a controller-recognizer model with a decoupled controller and recognizer. Our experiments revealed that it is not always necessary to tightly couple them and that by decoupling a controller and recognizer, there is a possibility of building a generic controller that is pretrained and works together with any subsequent recognizer.
ADASECANT: Robust Adaptive Secant Method for Stochastic Gradient
Nov 01, 2015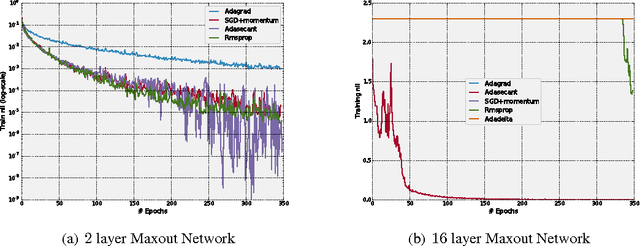
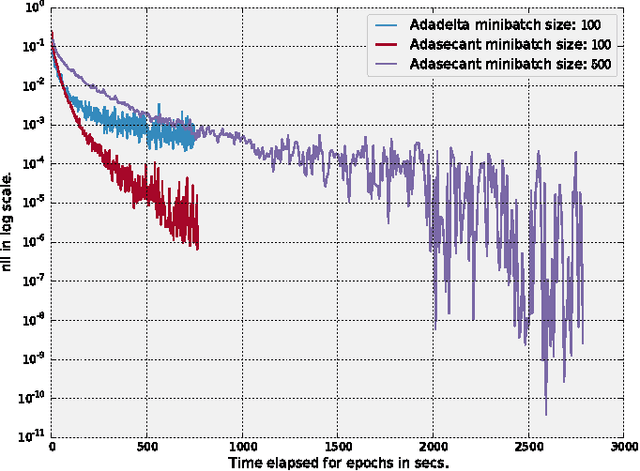
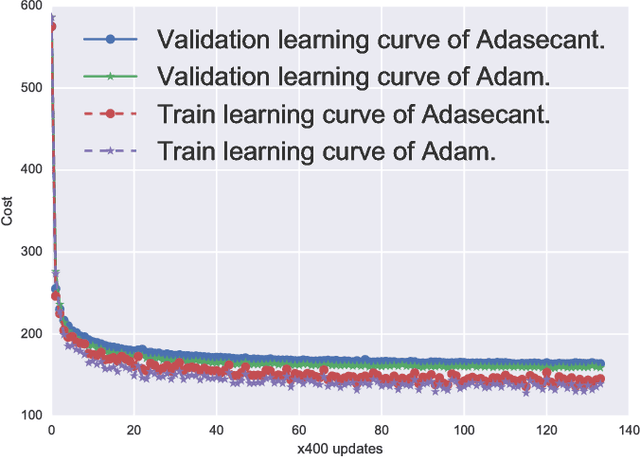
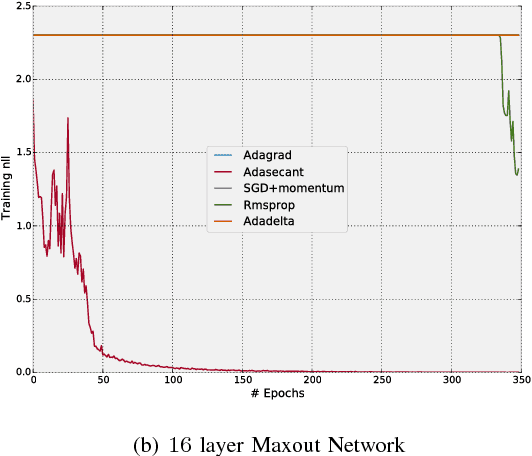
Stochastic gradient algorithms have been the main focus of large-scale learning problems and they led to important successes in machine learning. The convergence of SGD depends on the careful choice of learning rate and the amount of the noise in stochastic estimates of the gradients. In this paper, we propose a new adaptive learning rate algorithm, which utilizes curvature information for automatically tuning the learning rates. The information about the element-wise curvature of the loss function is estimated from the local statistics of the stochastic first order gradients. We further propose a new variance reduction technique to speed up the convergence. In our preliminary experiments with deep neural networks, we obtained better performance compared to the popular stochastic gradient algorithms.
Deep Fried Convnets
Jul 17, 2015
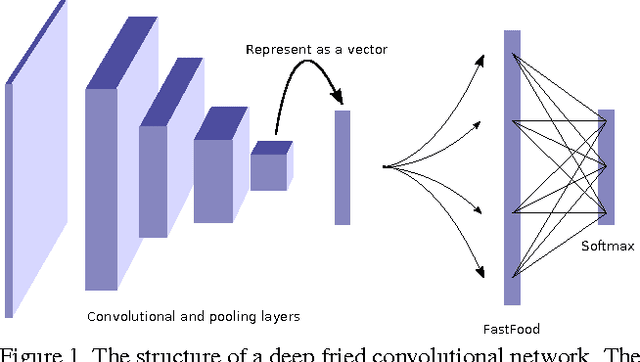
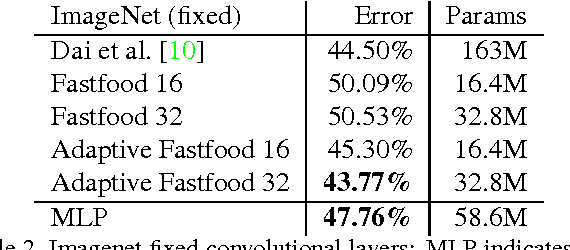
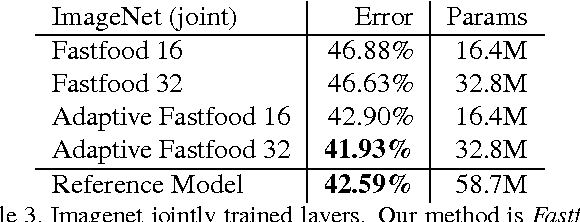
The fully connected layers of a deep convolutional neural network typically contain over 90% of the network parameters, and consume the majority of the memory required to store the network parameters. Reducing the number of parameters while preserving essentially the same predictive performance is critically important for operating deep neural networks in memory constrained environments such as GPUs or embedded devices. In this paper we show how kernel methods, in particular a single Fastfood layer, can be used to replace all fully connected layers in a deep convolutional neural network. This novel Fastfood layer is also end-to-end trainable in conjunction with convolutional layers, allowing us to combine them into a new architecture, named deep fried convolutional networks, which substantially reduces the memory footprint of convolutional networks trained on MNIST and ImageNet with no drop in predictive performance.