 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMollifying Networks
Paper and Code
Aug 17, 2016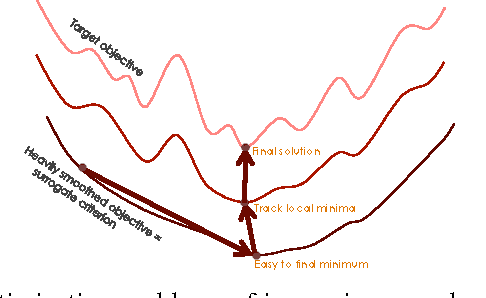

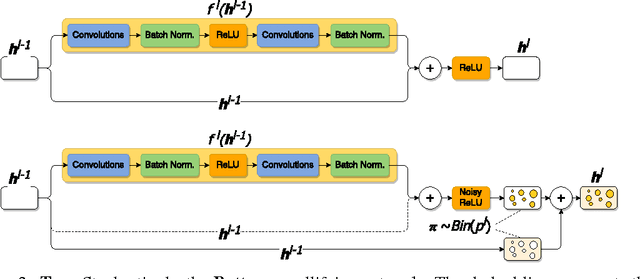
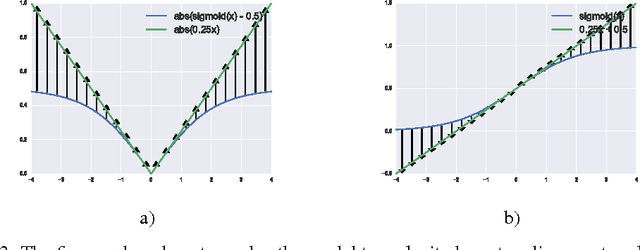
The optimization of deep neural networks can be more challenging than traditional convex optimization problems due to the highly non-convex nature of the loss function, e.g. it can involve pathological landscapes such as saddle-surfaces that can be difficult to escape for algorithms based on simple gradient descent. In this paper, we attack the problem of optimization of highly non-convex neural networks by starting with a smoothed -- or \textit{mollified} -- objective function that gradually has a more non-convex energy landscape during the training. Our proposition is inspired by the recent studies in continuation methods: similar to curriculum methods, we begin learning an easier (possibly convex) objective function and let it evolve during the training, until it eventually goes back to being the original, difficult to optimize, objective function. The complexity of the mollified networks is controlled by a single hyperparameter which is annealed during the training. We show improvements on various difficult optimization tasks and establish a relationship with recent works on continuation methods for neural networks and mollifiers.