 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Controller-Recognizer Framework: How necessary is recognition for control?
Paper and Code
Feb 09, 2016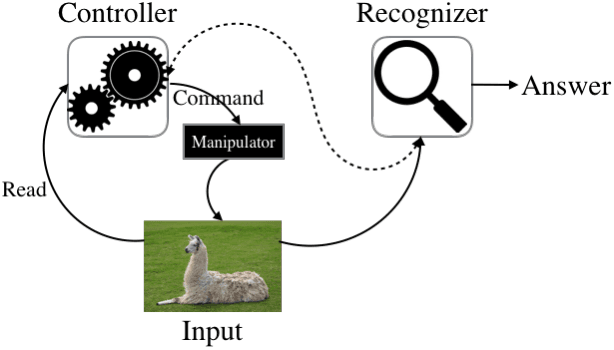
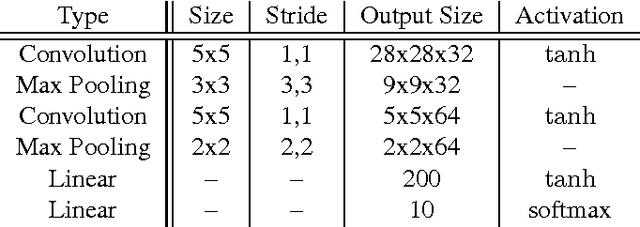
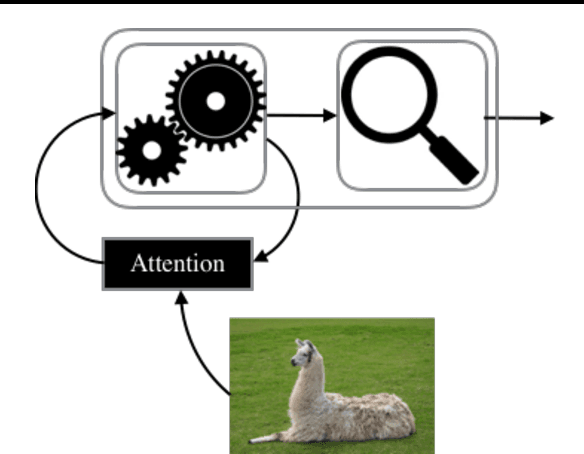
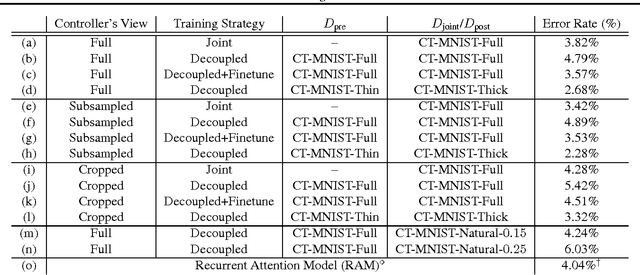
Recently there has been growing interest in building active visual object recognizers, as opposed to the usual passive recognizers which classifies a given static image into a predefined set of object categories. In this paper we propose to generalize these recently proposed end-to-end active visual recognizers into a controller-recognizer framework. A model in the controller-recognizer framework consists of a controller, which interfaces with an external manipulator, and a recognizer which classifies the visual input adjusted by the manipulator. We describe two most recently proposed controller-recognizer models: recurrent attention model and spatial transformer network as representative examples of controller-recognizer models. Based on this description we observe that most existing end-to-end controller-recognizers tightly, or completely, couple a controller and recognizer. We ask a question whether this tight coupling is necessary, and try to answer this empirically by building a controller-recognizer model with a decoupled controller and recognizer. Our experiments revealed that it is not always necessary to tightly couple them and that by decoupling a controller and recognizer, there is a possibility of building a generic controller that is pretrained and works together with any subsequent recognizer.