 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Image Generation with Diffusion Models and Cross Class Label Learning for Polyp Classification
Feb 08, 2025



Pathologic diagnosis is a critical phase in deciding the optimal treatment procedure for dealing with colorectal cancer (CRC). Colonic polyps, precursors to CRC, can pathologically be classified into two major types: adenomatous and hyperplastic. For precise classification and early diagnosis of such polyps, the medical procedure of colonoscopy has been widely adopted paired with various imaging techniques, including narrow band imaging and white light imaging. However, the existing classification techniques mainly rely on a single imaging modality and show limited performance due to data scarcity. Recently, generative artificial intelligence has been gaining prominence in overcoming such issues. Additionally, various generation-controlling mechanisms using text prompts and images have been introduced to obtain visually appealing and desired outcomes. However, such mechanisms require class labels to make the model respond efficiently to the provided control input. In the colonoscopy domain, such controlling mechanisms are rarely explored; specifically, the text prompt is a completely uninvestigated area. Moreover, the unavailability of expensive class-wise labels for diverse sets of images limits such explorations. Therefore, we develop a novel model, PathoPolyp-Diff, that generates text-controlled synthetic images with diverse characteristics in terms of pathology, imaging modalities, and quality. We introduce cross-class label learning to make the model learn features from other classes, reducing the burdensome task of data annotation. The experimental results report an improvement of up to 7.91% in balanced accuracy using a publicly available dataset. Moreover, cross-class label learning achieves a statistically significant improvement of up to 18.33% in balanced accuracy during video-level analysis. The code is available at https://github.com/Vanshali/PathoPolyp-Diff.
An objective validation of polyp and instrument segmentation methods in colonoscopy through Medico 2020 polyp segmentation and MedAI 2021 transparency challenges
Jul 30, 2023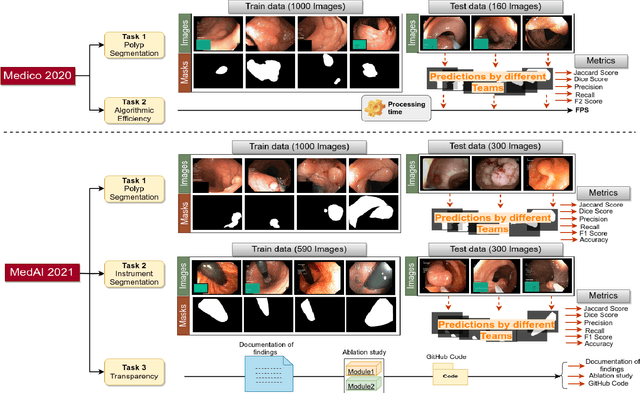
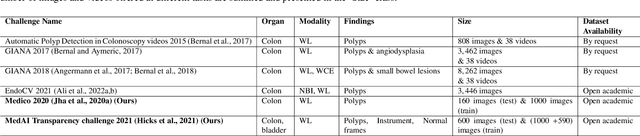
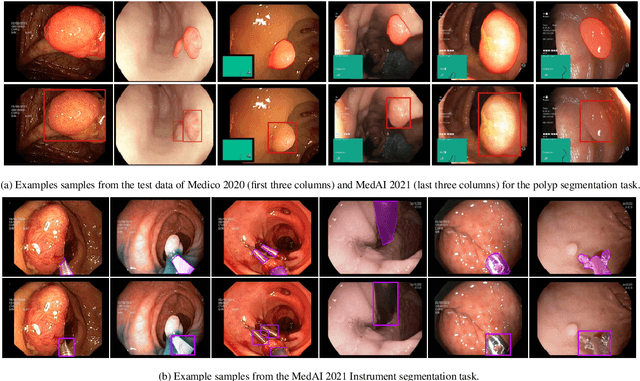
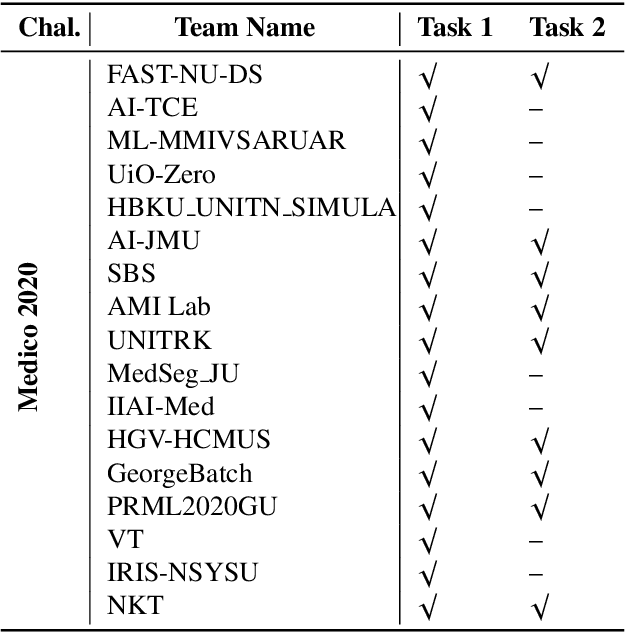
Automatic analysis of colonoscopy images has been an active field of research motivated by the importance of early detection of precancerous polyps. However, detecting polyps during the live examination can be challenging due to various factors such as variation of skills and experience among the endoscopists, lack of attentiveness, and fatigue leading to a high polyp miss-rate. Deep learning has emerged as a promising solution to this challenge as it can assist endoscopists in detecting and classifying overlooked polyps and abnormalities in real time. In addition to the algorithm's accuracy, transparency and interpretability are crucial to explaining the whys and hows of the algorithm's prediction. Further, most algorithms are developed in private data, closed source, or proprietary software, and methods lack reproducibility. Therefore, to promote the development of efficient and transparent methods, we have organized the "Medico automatic polyp segmentation (Medico 2020)" and "MedAI: Transparency in Medical Image Segmentation (MedAI 2021)" competitions. We present a comprehensive summary and analyze each contribution, highlight the strength of the best-performing methods, and discuss the possibility of clinical translations of such methods into the clinic. For the transparency task, a multi-disciplinary team, including expert gastroenterologists, accessed each submission and evaluated the team based on open-source practices, failure case analysis, ablation studies, usability and understandability of evaluations to gain a deeper understanding of the models' credibility for clinical deployment. Through the comprehensive analysis of the challenge, we not only highlight the advancements in polyp and surgical instrument segmentation but also encourage qualitative evaluation for building more transparent and understandable AI-based colonoscopy systems.
GastroVision: A Multi-class Endoscopy Image Dataset for Computer Aided Gastrointestinal Disease Detection
Jul 16, 2023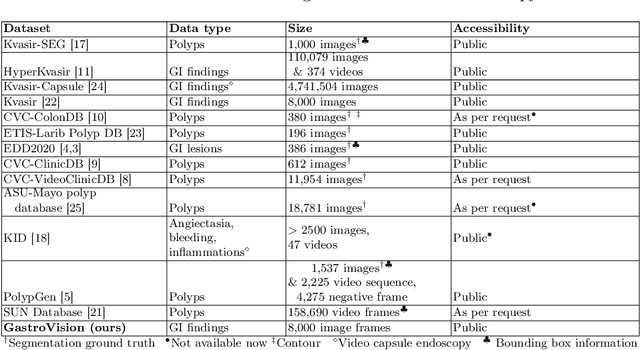
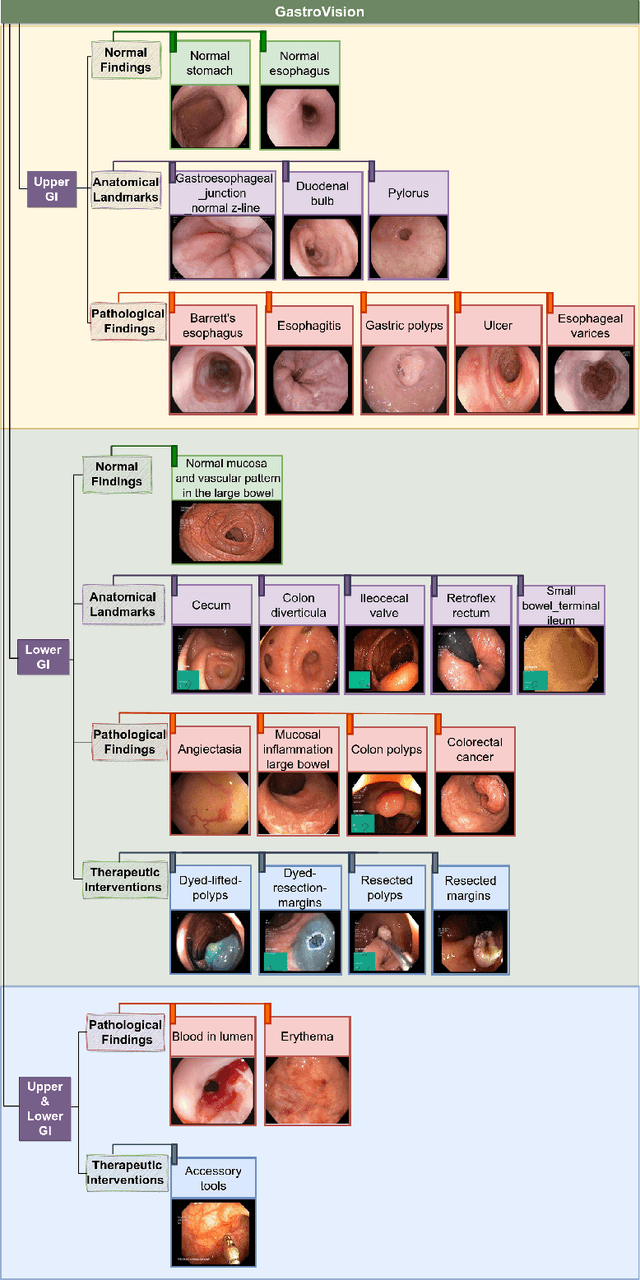
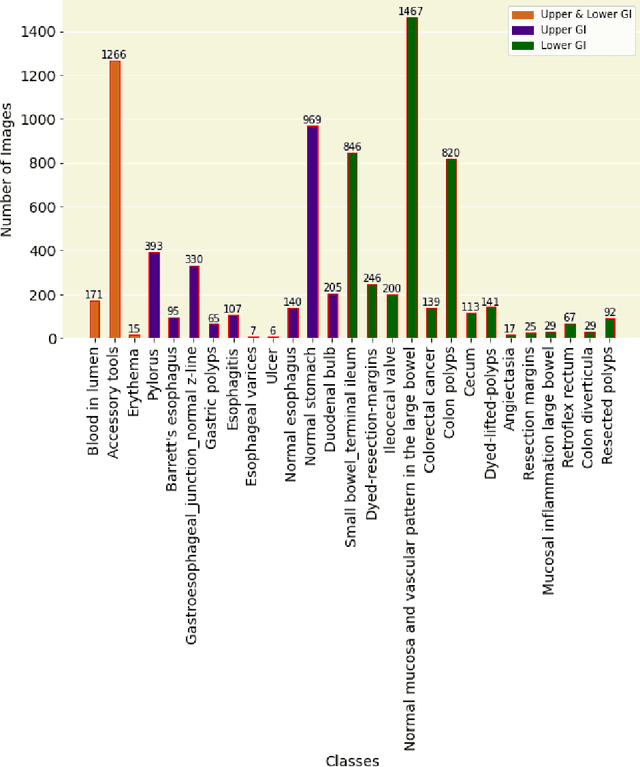
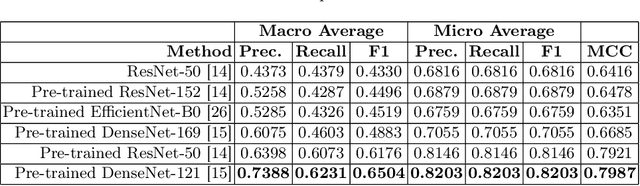
Integrating real-time artificial intelligence (AI) systems in clinical practices faces challenges such as scalability and acceptance. These challenges include data availability, biased outcomes, data quality, lack of transparency, and underperformance on unseen datasets from different distributions. The scarcity of large-scale, precisely labeled, and diverse datasets are the major challenge for clinical integration. This scarcity is also due to the legal restrictions and extensive manual efforts required for accurate annotations from clinicians. To address these challenges, we present GastroVision, a multi-center open-access gastrointestinal (GI) endoscopy dataset that includes different anatomical landmarks, pathological abnormalities, polyp removal cases and normal findings (a total of 24 classes) from the GI tract. The dataset comprises 8,000 images acquired from B{\ae}rum Hospital in Norway and Karolinska University in Sweden and was annotated and verified by experienced GI endoscopists. Furthermore, we validate the significance of our dataset with extensive benchmarking based on the popular deep learning based baseline models. We believe our dataset can facilitate the development of AI-based algorithms for GI disease detection and classification. Our dataset is available at https://osf.io/84e7f/.
Can Adversarial Networks Make Uninformative Colonoscopy Video Frames Clinically Informative?
Apr 04, 2023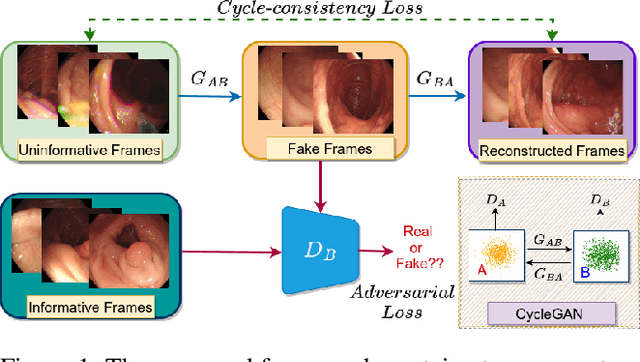
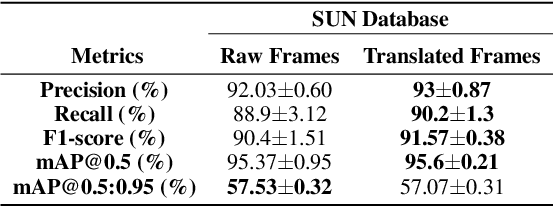
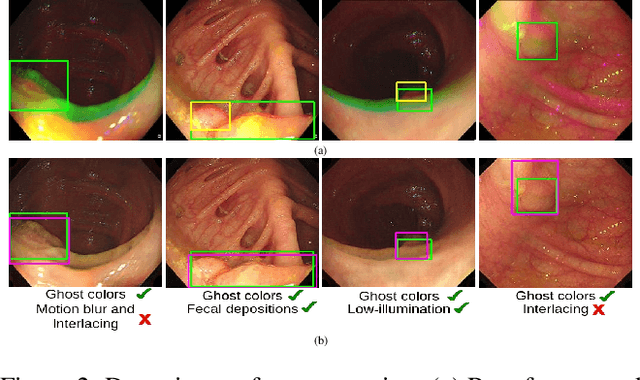
Various artifacts, such as ghost colors, interlacing, and motion blur, hinder diagnosing colorectal cancer (CRC) from videos acquired during colonoscopy. The frames containing these artifacts are called uninformative frames and are present in large proportions in colonoscopy videos. To alleviate the impact of artifacts, we propose an adversarial network based framework to convert uninformative frames to clinically relevant frames. We examine the effectiveness of the proposed approach by evaluating the translated frames for polyp detection using YOLOv5. Preliminary results present improved detection performance along with elegant qualitative outcomes. We also examine the failure cases to determine the directions for future work.
Efficient Context Integration through Factorized Pyramidal Learning for Ultra-Lightweight Semantic Segmentation
Feb 23, 2023



Semantic segmentation is a pixel-level prediction task to classify each pixel of the input image. Deep learning models, such as convolutional neural networks (CNNs), have been extremely successful in achieving excellent performances in this domain. However, mobile application, such as autonomous driving, demand real-time processing of incoming stream of images. Hence, achieving efficient architectures along with enhanced accuracy is of paramount importance. Since, accuracy and model size of CNNs are intrinsically contentious in nature, the challenge is to achieve a decent trade-off between accuracy and model size. To address this, we propose a novel Factorized Pyramidal Learning (FPL) module to aggregate rich contextual information in an efficient manner. On one hand, it uses a bank of convolutional filters with multiple dilation rates which leads to multi-scale context aggregation; crucial in achieving better accuracy. On the other hand, parameters are reduced by a careful factorization of the employed filters; crucial in achieving lightweight models. Moreover, we decompose the spatial pyramid into two stages which enables a simple and efficient feature fusion within the module to solve the notorious checkerboard effect. We also design a dedicated Feature-Image Reinforcement (FIR) unit to carry out the fusion operation of shallow and deep features with the downsampled versions of the input image. This gives an accuracy enhancement without increasing model parameters. Based on the FPL module and FIR unit, we propose an ultra-lightweight real-time network, called FPLNet, which achieves state-of-the-art accuracy-efficiency trade-off. More specifically, with only less than 0.5 million parameters, the proposed network achieves 66.93\% and 66.28\% mIoU on Cityscapes validation and test set, respectively. Moreover, FPLNet has a processing speed of 95.5 frames per second (FPS).
Extraction of Key-frames of Endoscopic Videos by using Depth Information
Jun 30, 2021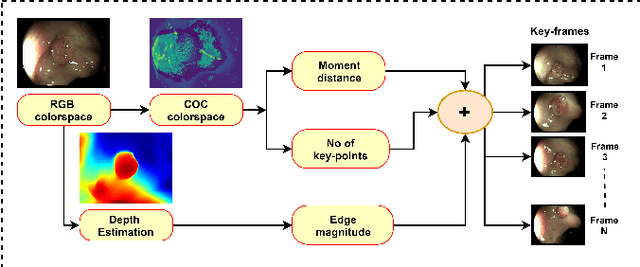
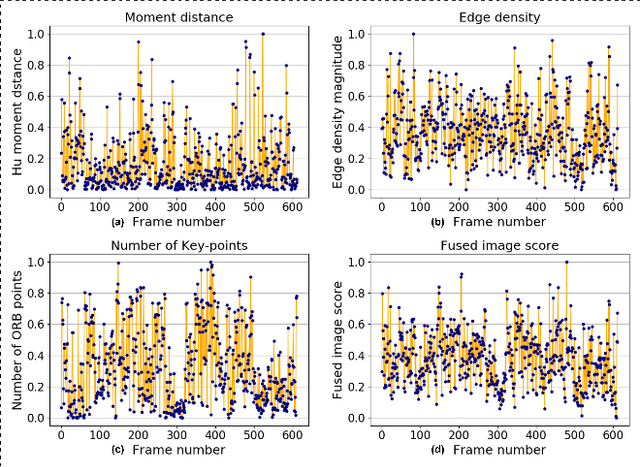
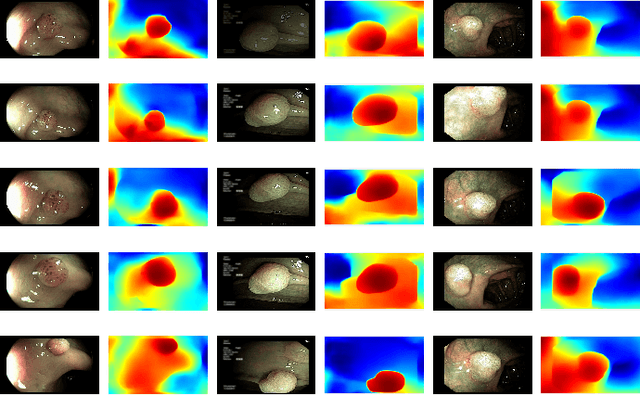

A deep learning-based monocular depth estimation (MDE) technique is proposed for selection of most informative frames (key frames) of an endoscopic video. In most of the cases, ground truth depth maps of polyps are not readily available and that is why the transfer learning approach is adopted in our method. An endoscopic modalities generally capture thousands of frames. In this scenario, it is quite important to discard low-quality and clinically irrelevant frames of an endoscopic video while the most informative frames should be retained for clinical diagnosis. In this view, a key-frame selection strategy is proposed by utilizing the depth information of polyps. In our method, image moment, edge magnitude, and key-points are considered for adaptively selecting the key frames. One important application of our proposed method could be the 3D reconstruction of polyps with the help of extracted key frames. Also, polyps are localized with the help of extracted depth maps.
Two-stream Fusion Model for Dynamic Hand Gesture Recognition using 3D-CNN and 2D-CNN Optical Flow guided Motion Template
Jul 17, 2020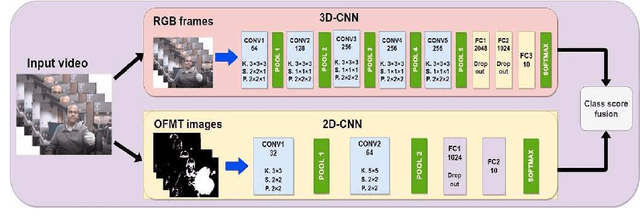



The use of hand gestures can be a useful tool for many applications in the human-computer interaction community. In a broad range of areas hand gesture techniques can be applied specifically in sign language recognition, robotic surgery, etc. In the process of hand gesture recognition, proper detection, and tracking of the moving hand become challenging due to the varied shape and size of the hand. Here the objective is to track the movement of the hand irrespective of the shape, size, and color of the hand. And, for this, a motion template guided by optical flow (OFMT) is proposed. OFMT is a compact representation of the motion information of a gesture encoded into a single image. In the experimentation, different datasets using bare hand with an open palm, and folded palm wearing green-glove are used, and in both cases, we could generate the OFMT images with equal precision. Recently, deep network-based techniques have shown impressive improvements as compared to conventional hand-crafted feature-based techniques. Moreover, in the literature, it is seen that the use of different streams with informative input data helps to increase the performance in the recognition accuracy. This work basically proposes a two-stream fusion model for hand gesture recognition and a compact yet efficient motion template based on optical flow. Specifically, the two-stream network consists of two layers: a 3D convolutional neural network (C3D) that takes gesture videos as input and a 2D-CNN that takes OFMT images as input. C3D has shown its efficiency in capturing spatio-temporal information of a video. Whereas OFMT helps to eliminate irrelevant gestures providing additional motion information. Though each stream can work independently, they are combined with a fusion scheme to boost the recognition results. We have shown the efficiency of the proposed two-stream network on two databases.
Pseudo vs. True Defect Classification in Printed Circuits Boards using Wavelet Features
Oct 24, 2013
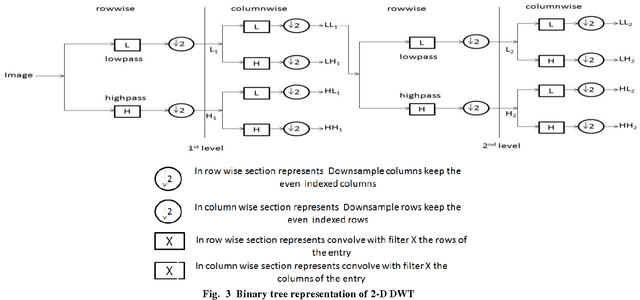

In recent years, Printed Circuit Boards (PCB) have become the backbone of a large number of consumer electronic devices leading to a surge in their production. This has made it imperative to employ automatic inspection systems to identify manufacturing defects in PCB before they are installed in the respective systems. An important task in this regard is the classification of defects as either true or pseudo defects, which decides if the PCB is to be re-manufactured or not. This work proposes a novel approach to detect most common defects in the PCBs. The problem has been approached by employing highly discriminative features based on multi-scale wavelet transform, which are further boosted by using a kernalized version of the support vector machines (SVM). A real world printed circuit board dataset has been used for quantitative analysis. Experimental results demonstrated the efficacy of the proposed method.