 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTissue Concepts: supervised foundation models in computational pathology
Sep 05, 2024



Due to the increasing workload of pathologists, the need for automation to support diagnostic tasks and quantitative biomarker evaluation is becoming more and more apparent. Foundation models have the potential to improve generalizability within and across centers and serve as starting points for data efficient development of specialized yet robust AI models. However, the training foundation models themselves is usually very expensive in terms of data, computation, and time. This paper proposes a supervised training method that drastically reduces these expenses. The proposed method is based on multi-task learning to train a joint encoder, by combining 16 different classification, segmentation, and detection tasks on a total of 912,000 patches. Since the encoder is capable of capturing the properties of the samples, we term it the Tissue Concepts encoder. To evaluate the performance and generalizability of the Tissue Concepts encoder across centers, classification of whole slide images from four of the most prevalent solid cancers - breast, colon, lung, and prostate - was used. The experiments show that the Tissue Concepts model achieve comparable performance to models trained with self-supervision, while requiring only 6% of the amount of training patches. Furthermore, the Tissue Concepts encoder outperforms an ImageNet pre-trained encoder on both in-domain and out-of-domain data.
Overcoming Data Scarcity in Biomedical Imaging with a Foundational Multi-Task Model
Nov 16, 2023Foundational models, pretrained on a large scale, have demonstrated substantial success across non-medical domains. However, training these models typically requires large, comprehensive datasets, which contrasts with the smaller and more heterogeneous datasets common in biomedical imaging. Here, we propose a multi-task learning strategy that decouples the number of training tasks from memory requirements. We trained a Universal bioMedical PreTrained model (UMedPT) on a multi-task database including tomographic, microscopic, and X-ray images, with various labelling strategies such as classification, segmentation, and object detection. The UMedPT foundational model outperformed ImageNet pretraining and the previous state-of-the-art models. For tasks related to the pretraining database, it maintained its performance with only 1% of the original training data and without fine-tuning. For out-of-domain tasks it required not more than 50% of the original training data. In an external independent validation imaging features extracted using UMedPT proved to be a new standard for cross-center transferability.
The ACROBAT 2022 Challenge: Automatic Registration Of Breast Cancer Tissue
May 29, 2023The alignment of tissue between histopathological whole-slide-images (WSI) is crucial for research and clinical applications. Advances in computing, deep learning, and availability of large WSI datasets have revolutionised WSI analysis. Therefore, the current state-of-the-art in WSI registration is unclear. To address this, we conducted the ACROBAT challenge, based on the largest WSI registration dataset to date, including 4,212 WSIs from 1,152 breast cancer patients. The challenge objective was to align WSIs of tissue that was stained with routine diagnostic immunohistochemistry to its H&E-stained counterpart. We compare the performance of eight WSI registration algorithms, including an investigation of the impact of different WSI properties and clinical covariates. We find that conceptually distinct WSI registration methods can lead to highly accurate registration performances and identify covariates that impact performances across methods. These results establish the current state-of-the-art in WSI registration and guide researchers in selecting and developing methods.
Deep Feature based Cross-slide Registration
Feb 27, 2022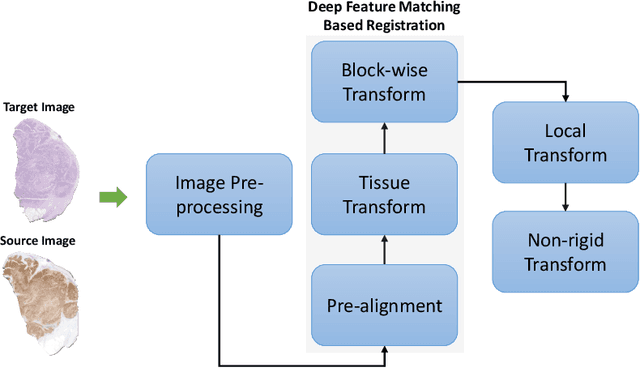
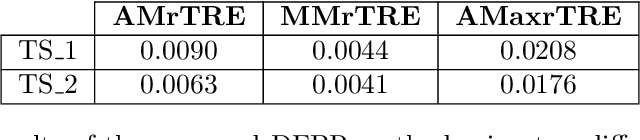
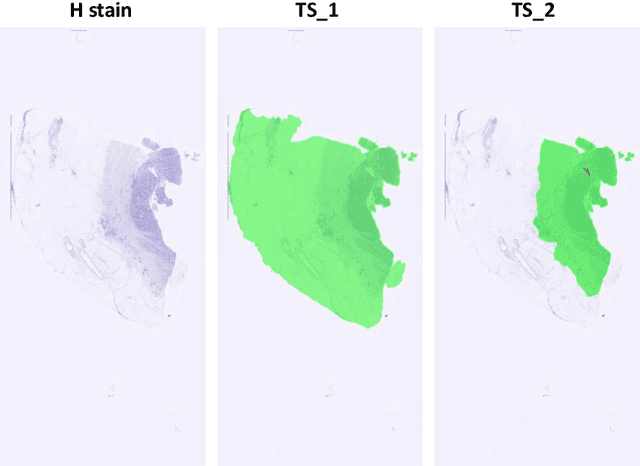
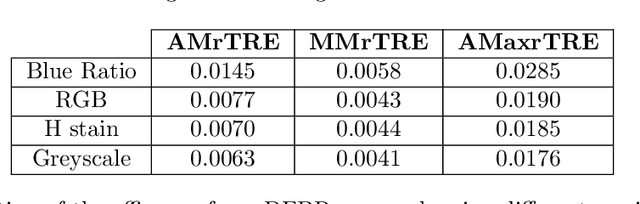
Cross-slide image analysis provides additional information by analysing the expression of different biomarkers as compared to a single slide analysis. Slides stained with different biomarkers are analysed side by side which may reveal unknown relations between the different biomarkers. During the slide preparation, a tissue section may be placed at an arbitrary orientation as compared to other sections of the same tissue block. The problem is compounded by the fact that tissue contents are likely to change from one section to the next and there may be unique artefacts on some of the slides. This makes registration of each section to a reference section of the same tissue block an important pre-requisite task before any cross-slide analysis. We propose a deep feature based registration (DFBR) method which utilises data-driven features to estimate the rigid transformation. We adopted a multi-stage strategy for improving the quality of registration. We also developed a visualisation tool to view registered pairs of WSIs at different magnifications. With the help of this tool, one can apply a transformation on the fly without the need to generate transformed source WSI in a pyramidal form. We compared the performance of data-driven features with that of hand-crafted features on the COMET dataset. Our approach can align the images with low registration errors. Generally, the success of non-rigid registration is dependent on the quality of rigid registration. To evaluate the efficacy of the DFBR method, the first two steps of the ANHIR winner's framework are replaced with our DFBR to register challenge provided image pairs. The modified framework produce comparable results to that of challenge winning team.
Deep Learning based Prediction of MSI in Colorectal Cancer via Prediction of the Status of MMR Markers
Feb 24, 2022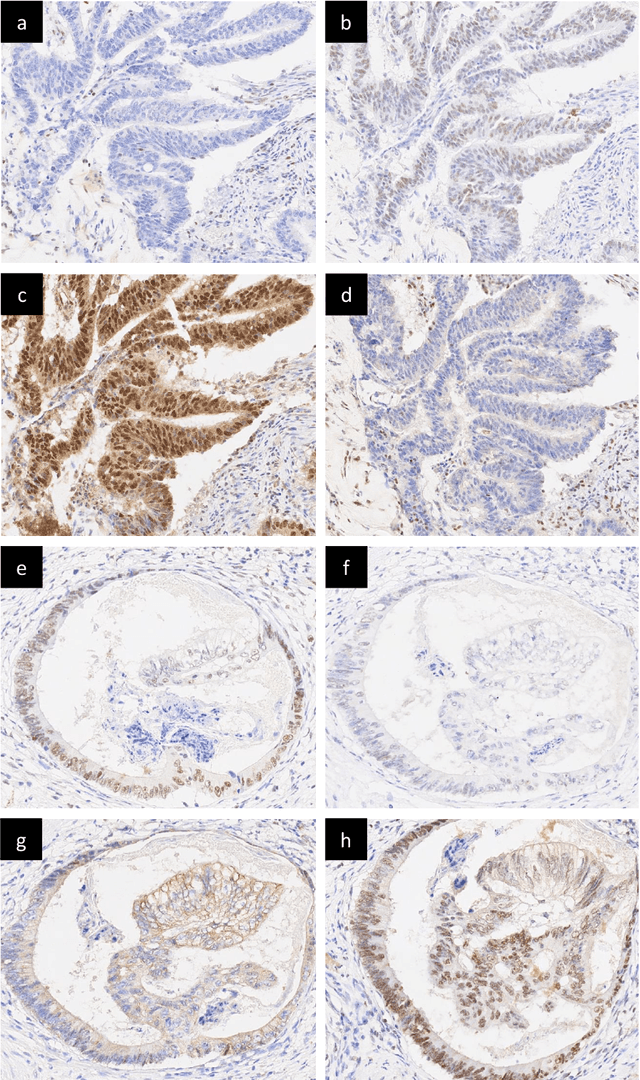

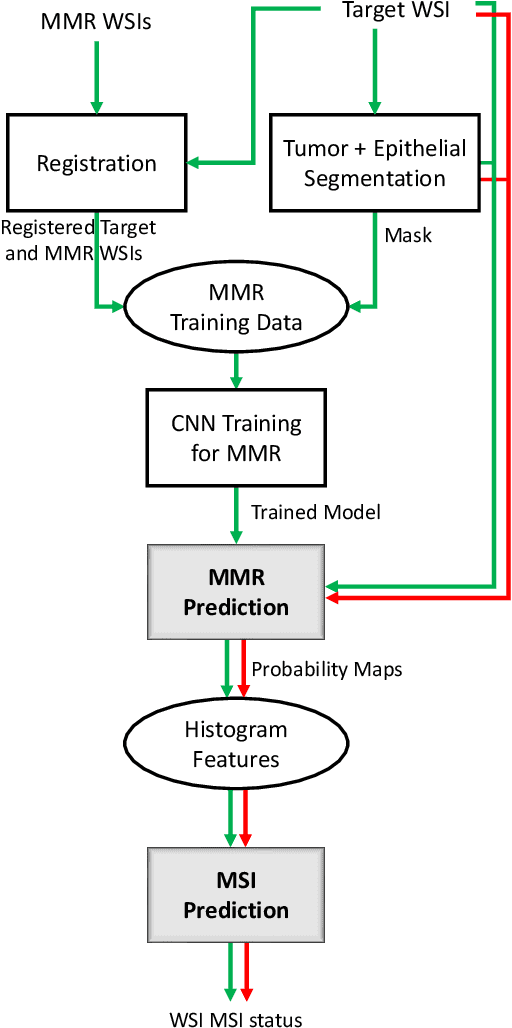
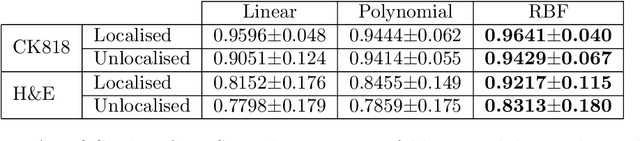
An accurate diagnosis and profiling of tumour are critical to the best treatment choices for cancer patients. In addition to the cancer type and its aggressiveness, molecular heterogeneity also plays a vital role in treatment selection. MSI or MMR deficiency is one of the well-studied aberrations in terms of molecular changes. Colorectal cancer patients with MMR deficiency respond well to immunotherapy, hence assessment of the relevant molecular markers can assist clinicians in making optimal treatment selections for patients. Immunohistochemistry is one of the ways for identifying these molecular changes which requires additional sections of tumour tissue. Introduction of automated methods that can predict MSI or MMR status from a target image without the need for additional sections can substantially reduce the cost associated with it. In this work, we present our work on predicting MSI status in a two-stage process using a single target slide either stained with CK818 or H\&E. First, we train a multi-headed convolutional neural network model where each head is responsible for predicting one of the MMR protein expressions. To this end, we perform registration of MMR slides to the target slide as a pre-processing step. In the second stage, statistical features computed from the MMR prediction maps are used for the final MSI prediction. Our results demonstrate that MSI classification can be improved on incorporating fine-grained MMR labels in comparison to the previous approaches in which coarse labels (MSI/MSS) are utilised.
High-resolution Image Registration of Consecutive and Re-stained Sections in Histopathology
Jun 24, 2021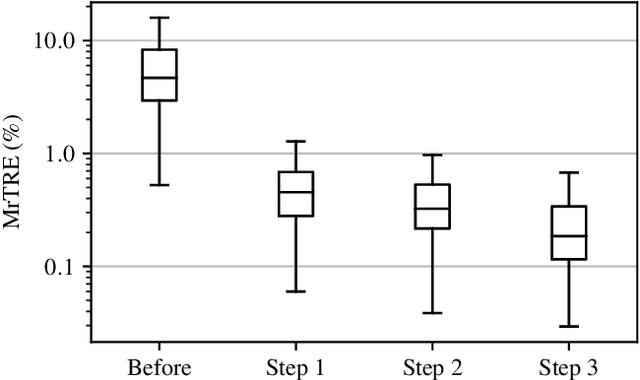
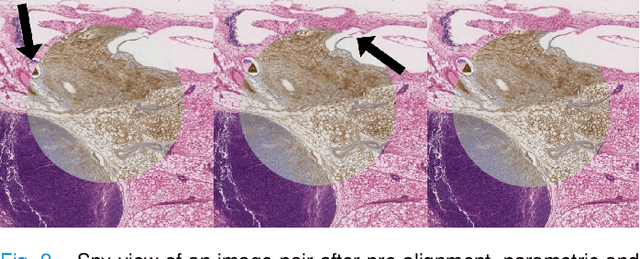
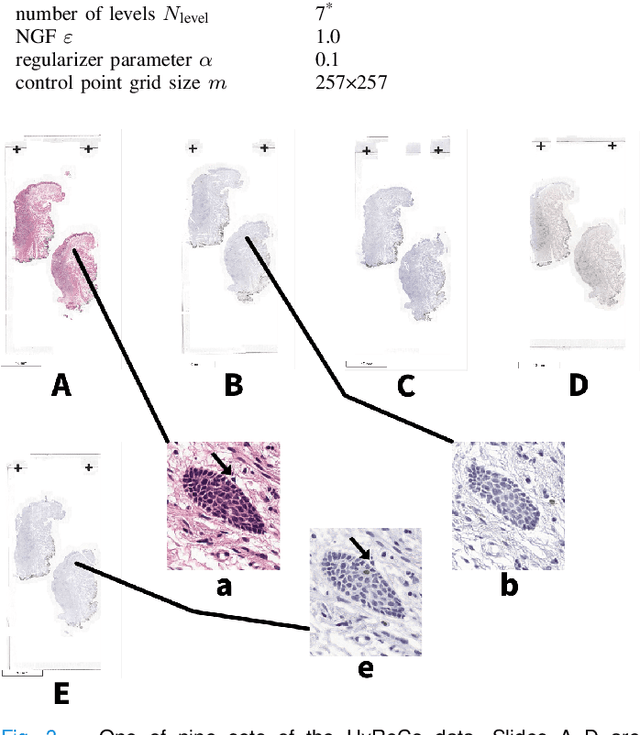
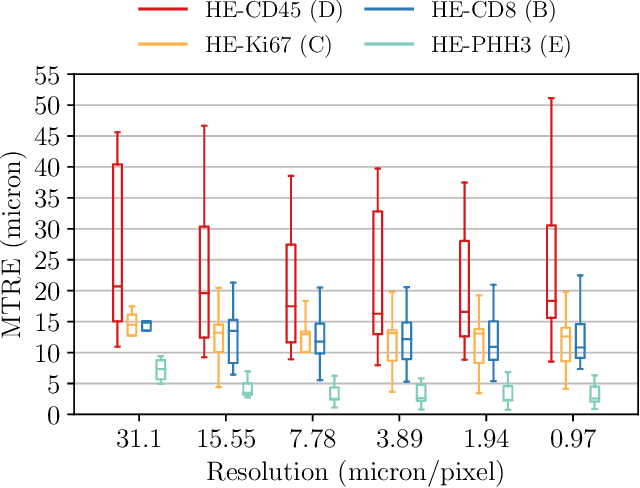
We compare variational image registration in consectutive and re-stained sections from histopathology. We present a fully-automatic algorithm for non-parametric (nonlinear) image registration and apply it to a previously existing dataset from the ANHIR challenge (230 slide pairs, consecutive sections) and a new dataset (hybrid re-stained and consecutive, 81 slide pairs, ca. 3000 landmarks) which is made publicly available. Registration hyperparameters are obtained in the ANHIR dataset and applied to the new dataset without modification. In the new dataset, landmark errors after registration range from 13.2 micrometers for consecutive sections to 1 micrometer for re-stained sections. We observe that non-parametric registration leads to lower landmark errors in both cases, even though the effect is smaller in re-stained sections. The nucleus-level alignment after non-parametric registration of re-stained sections provides a valuable tool to generate automatic ground-truth for machine learning applications in histopathology.
Virtual staining for mitosis detection in Breast Histopathology
Mar 17, 2020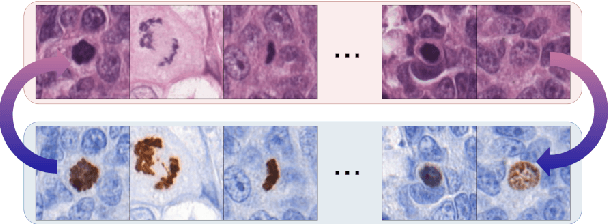
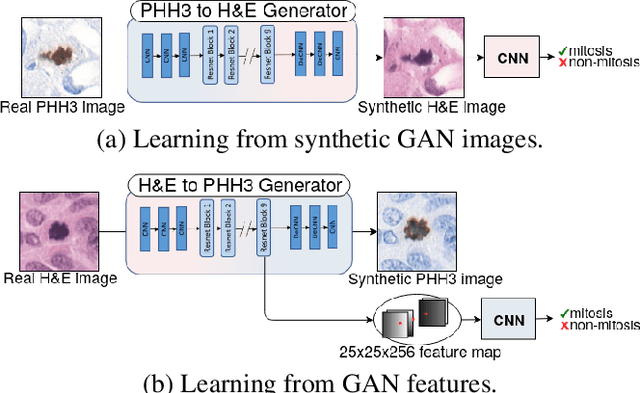
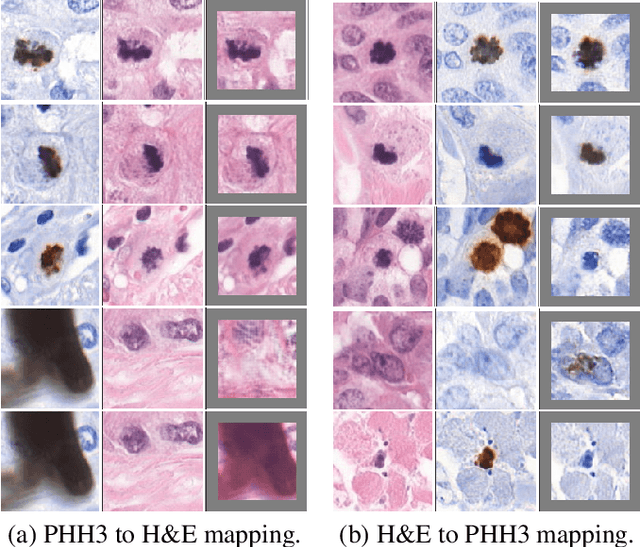
We propose a virtual staining methodology based on Generative Adversarial Networks to map histopathology images of breast cancer tissue from H&E stain to PHH3 and vice versa. We use the resulting synthetic images to build Convolutional Neural Networks (CNN) for automatic detection of mitotic figures, a strong prognostic biomarker used in routine breast cancer diagnosis and grading. We propose several scenarios, in which CNN trained with synthetically generated histopathology images perform on par with or even better than the same baseline model trained with real images. We discuss the potential of this application to scale the number of training samples without the need for manual annotations.
Robust, fast and accurate: a 3-step method for automatic histological image registration
Mar 29, 2019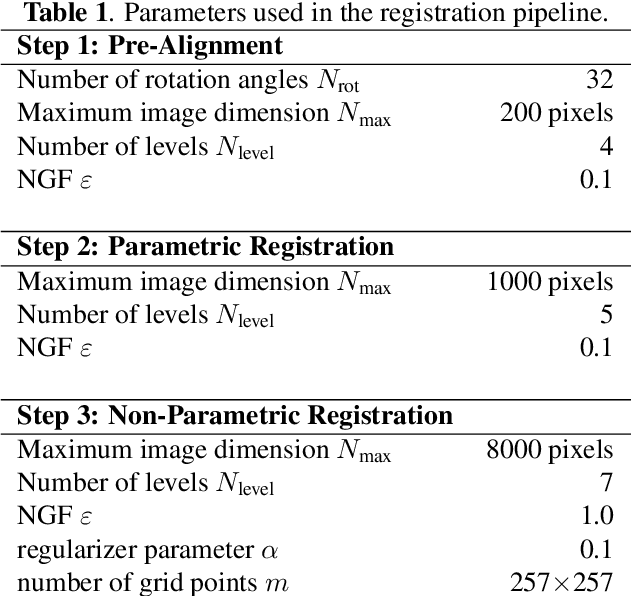
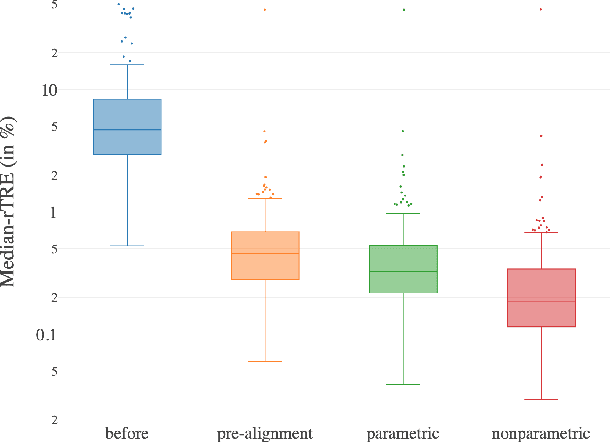
We present a 3-step registration pipeline for differently stained histological serial sections that consists of 1) a robust pre-alignment, 2) a parametric registration computed on coarse resolution images, and 3) an accurate nonlinear registration. In all three steps the NGF distance measure is minimized with respect to an increasingly flexible transformation. We apply the method in the ANHIR image registration challenge and evaluate its performance on the training data. The presented method is robust (error reduction in 99.6% of the cases), fast (runtime 4 seconds) and accurate (median relative target registration error 0.19%).
Epithelium segmentation using deep learning in H&E-stained prostate specimens with immunohistochemistry as reference standard
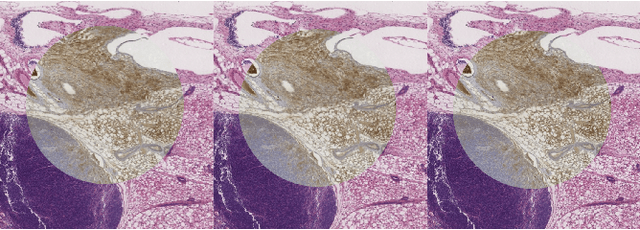
Aug 17, 2018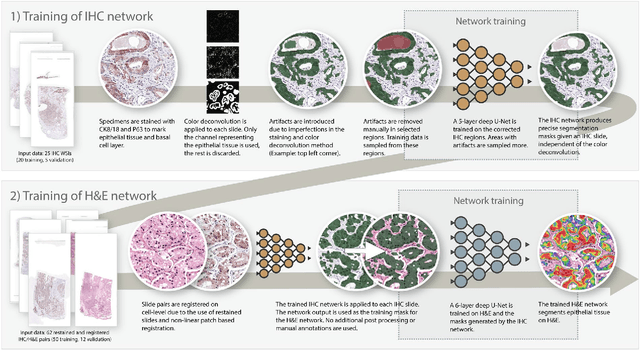
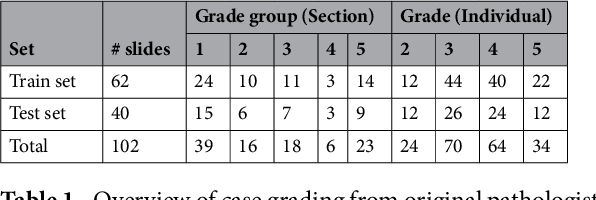
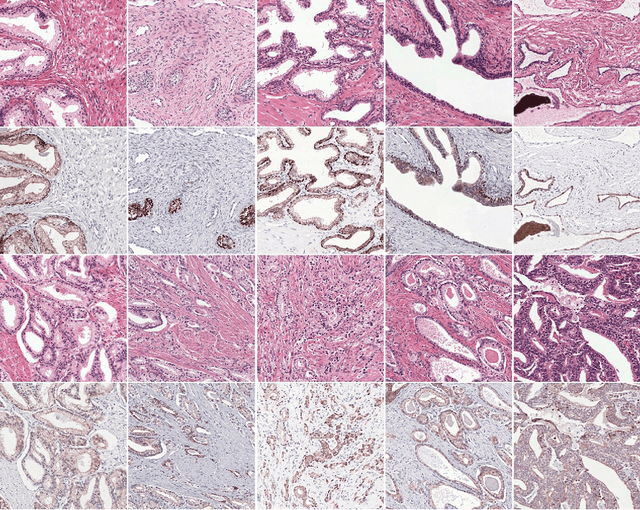
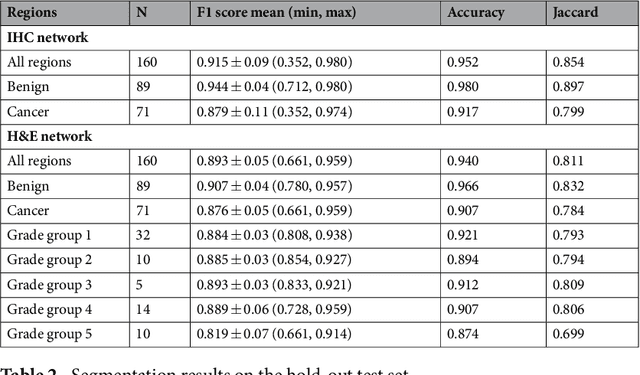
Prostate cancer (PCa) is graded by pathologists by examining the architectural pattern of cancerous epithelial tissue on hematoxylin and eosin (H&E) stained slides. Given the importance of gland morphology, automatically differentiating between glandular epithelial tissue and other tissues is an important prerequisite for the development of automated methods for detecting PCa. We propose a new method, using deep learning, for automatically segmenting epithelial tissue in digitized prostatectomy slides. We employed immunohistochemistry (IHC) to render the ground truth less subjective and more precise compared to manual outlining on H&E slides, especially in areas with high-grade and poorly differentiated PCa. Our dataset consisted of 102 tissue blocks, including both low and high grade PCa. From each block a single new section was cut, stained with H&E, scanned, restained using P63 and CK8/18 to highlight the epithelial structure, and scanned again. The H&E slides were co-registered to the IHC slides. On a subset of the IHC slides we applied color deconvolution, corrected stain errors manually, and trained a U-Net to perform segmentation of epithelial structures. Whole-slide segmentation masks generated by the IHC U-Net were used to train a second U-Net on H&E. Our system makes precise cell-level segmentations and segments both intact glands as well as individual (tumor) epithelial cells. We achieved an F1-score of 0.895 on a hold-out test set and 0.827 on an external reference set from a different center. We envision this segmentation as being the first part of a fully automated prostate cancer detection and grading pipeline.