 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models -- A Panacea for Artificial Intelligence in Pathology?
Feb 28, 2025
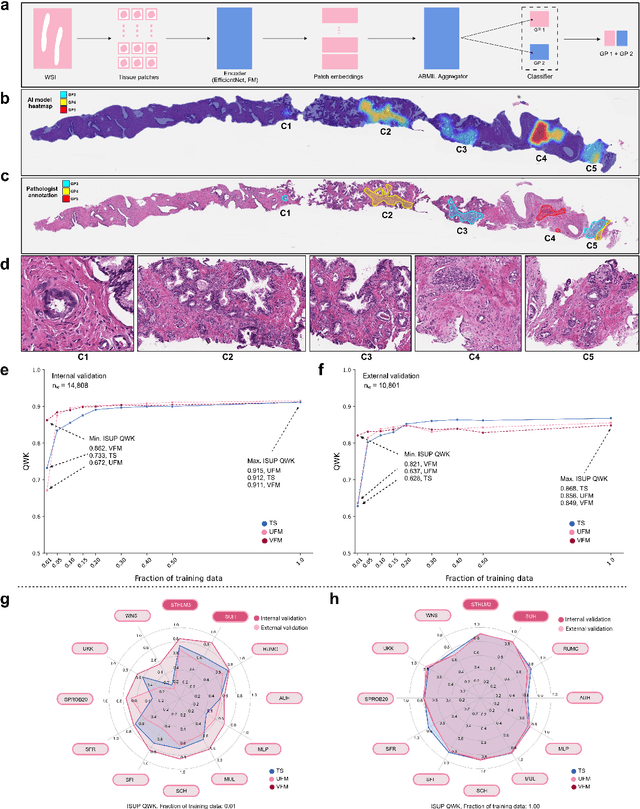

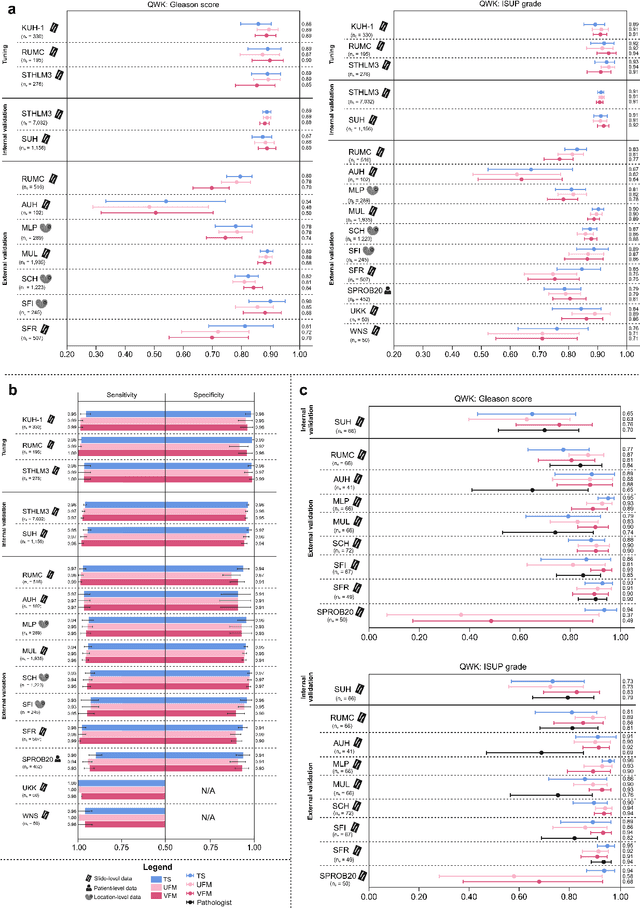
The role of artificial intelligence (AI) in pathology has evolved from aiding diagnostics to uncovering predictive morphological patterns in whole slide images (WSIs). Recently, foundation models (FMs) leveraging self-supervised pre-training have been widely advocated as a universal solution for diverse downstream tasks. However, open questions remain about their clinical applicability and generalization advantages over end-to-end learning using task-specific (TS) models. Here, we focused on AI with clinical-grade performance for prostate cancer diagnosis and Gleason grading. We present the largest validation of AI for this task, using over 100,000 core needle biopsies from 7,342 patients across 15 sites in 11 countries. We compared two FMs with a fully end-to-end TS model in a multiple instance learning framework. Our findings challenge assumptions that FMs universally outperform TS models. While FMs demonstrated utility in data-scarce scenarios, their performance converged with - and was in some cases surpassed by - TS models when sufficient labeled training data were available. Notably, extensive task-specific training markedly reduced clinically significant misgrading, misdiagnosis of challenging morphologies, and variability across different WSI scanners. Additionally, FMs used up to 35 times more energy than the TS model, raising concerns about their sustainability. Our results underscore that while FMs offer clear advantages for rapid prototyping and research, their role as a universal solution for clinically applicable medical AI remains uncertain. For high-stakes clinical applications, rigorous validation and consideration of task-specific training remain critically important. We advocate for integrating the strengths of FMs and end-to-end learning to achieve robust and resource-efficient AI pathology solutions fit for clinical use.
The ACROBAT 2022 Challenge: Automatic Registration Of Breast Cancer Tissue
May 29, 2023The alignment of tissue between histopathological whole-slide-images (WSI) is crucial for research and clinical applications. Advances in computing, deep learning, and availability of large WSI datasets have revolutionised WSI analysis. Therefore, the current state-of-the-art in WSI registration is unclear. To address this, we conducted the ACROBAT challenge, based on the largest WSI registration dataset to date, including 4,212 WSIs from 1,152 breast cancer patients. The challenge objective was to align WSIs of tissue that was stained with routine diagnostic immunohistochemistry to its H&E-stained counterpart. We compare the performance of eight WSI registration algorithms, including an investigation of the impact of different WSI properties and clinical covariates. We find that conceptually distinct WSI registration methods can lead to highly accurate registration performances and identify covariates that impact performances across methods. These results establish the current state-of-the-art in WSI registration and guide researchers in selecting and developing methods.
ACROBAT -- a multi-stain breast cancer histological whole-slide-image data set from routine diagnostics for computational pathology
Nov 24, 2022The analysis of FFPE tissue sections stained with haematoxylin and eosin (H&E) or immunohistochemistry (IHC) is an essential part of the pathologic assessment of surgically resected breast cancer specimens. IHC staining has been broadly adopted into diagnostic guidelines and routine workflows to manually assess status and scoring of several established biomarkers, including ER, PGR, HER2 and KI67. However, this is a task that can also be facilitated by computational pathology image analysis methods. The research in computational pathology has recently made numerous substantial advances, often based on publicly available whole slide image (WSI) data sets. However, the field is still considerably limited by the sparsity of public data sets. In particular, there are no large, high quality publicly available data sets with WSIs of matching IHC and H&E-stained tissue sections. Here, we publish the currently largest publicly available data set of WSIs of tissue sections from surgical resection specimens from female primary breast cancer patients with matched WSIs of corresponding H&E and IHC-stained tissue, consisting of 4,212 WSIs from 1,153 patients. The primary purpose of the data set was to facilitate the ACROBAT WSI registration challenge, aiming at accurately aligning H&E and IHC images. For research in the area of image registration, automatic quantitative feedback on registration algorithm performance remains available through the ACROBAT challenge website, based on more than 37,000 manually annotated landmark pairs from 13 annotators. Beyond registration, this data set has the potential to enable many different avenues of computational pathology research, including stain-guided learning, virtual staining, unsupervised pre-training, artefact detection and stain-independent models.
Predicting molecular phenotypes from histopathology images: a transcriptome-wide expression-morphology analysis in breast cancer
Sep 18, 2020
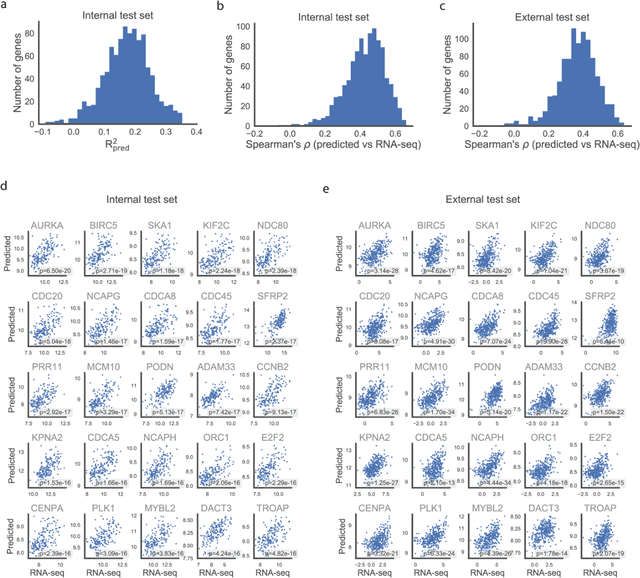
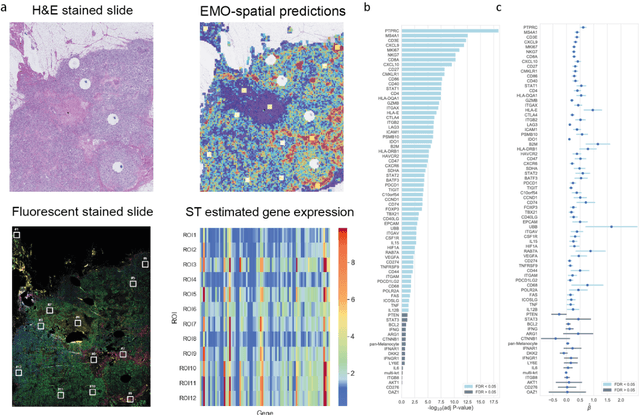
Molecular phenotyping is central in cancer precision medicine, but remains costly and standard methods only provide a tumour average profile. Microscopic morphological patterns observable in histopathology sections from tumours are determined by the underlying molecular phenotype and associated with clinical factors. The relationship between morphology and molecular phenotype has a potential to be exploited for prediction of the molecular phenotype from the morphology visible in histopathology images. We report the first transcriptome-wide Expression-MOrphology (EMO) analysis in breast cancer, where gene-specific models were optimised and validated for prediction of mRNA expression both as a tumour average and in spatially resolved manner. Individual deep convolutional neural networks (CNNs) were optimised to predict the expression of 17,695 genes from hematoxylin and eosin (HE) stained whole slide images (WSIs). Predictions for 9,334 (52.75%) genes were significantly associated with RNA-sequencing estimates (FDR adjusted p-value < 0.05). 1,011 of the genes were brought forward for validation, with 876 (87%) and 908 (90%) successfully replicated in internal and external test data, respectively. Predicted spatial intra-tumour variabilities in expression were validated in 76 genes, out of which 59 (77.6%) had a significant association (FDR adjusted p-value < 0.05) with spatial transcriptomics estimates. These results suggest that the proposed methodology can be applied to predict both tumour average gene expression and intra-tumour spatial expression directly from morphology, thus providing a scalable approach to characterise intra-tumour heterogeneity.