 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models -- A Panacea for Artificial Intelligence in Pathology?
Paper and Code
Feb 28, 2025
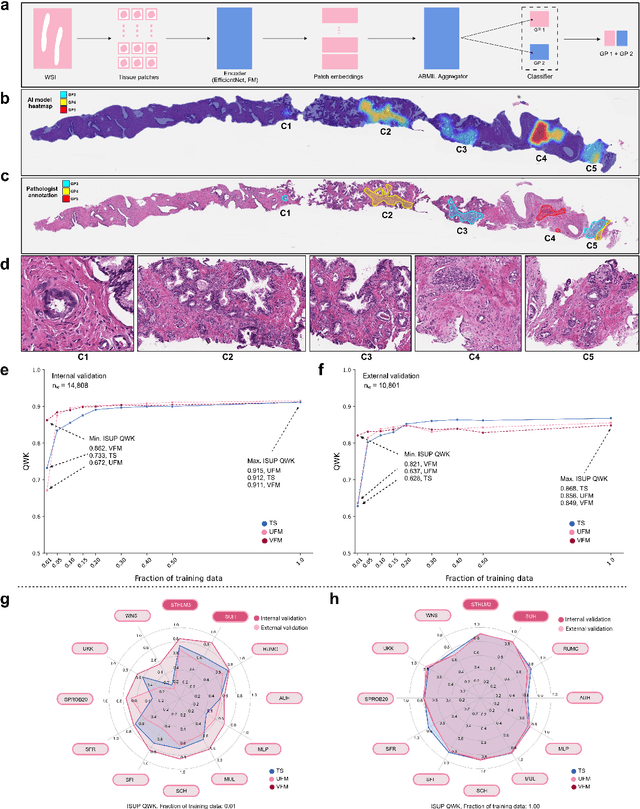

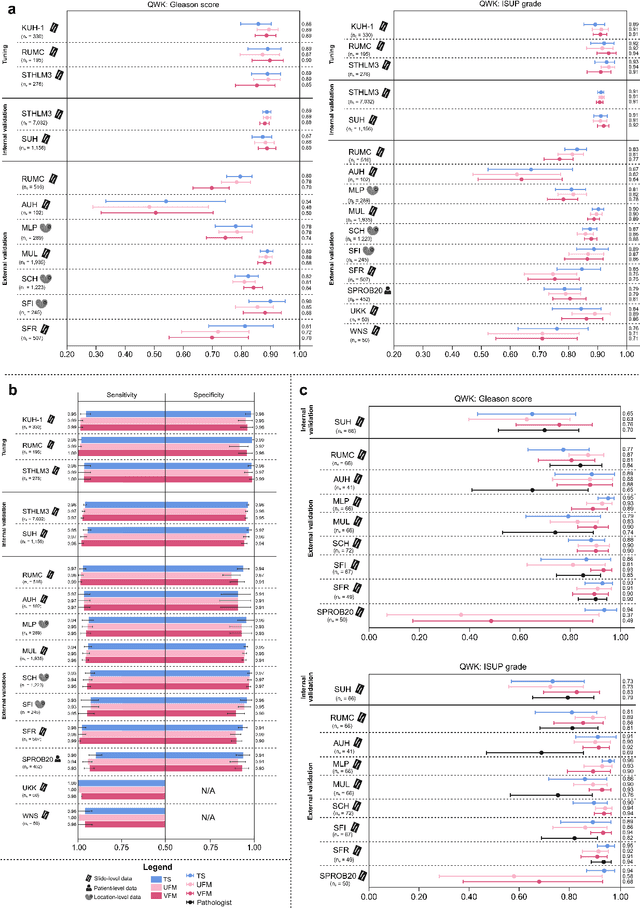
The role of artificial intelligence (AI) in pathology has evolved from aiding diagnostics to uncovering predictive morphological patterns in whole slide images (WSIs). Recently, foundation models (FMs) leveraging self-supervised pre-training have been widely advocated as a universal solution for diverse downstream tasks. However, open questions remain about their clinical applicability and generalization advantages over end-to-end learning using task-specific (TS) models. Here, we focused on AI with clinical-grade performance for prostate cancer diagnosis and Gleason grading. We present the largest validation of AI for this task, using over 100,000 core needle biopsies from 7,342 patients across 15 sites in 11 countries. We compared two FMs with a fully end-to-end TS model in a multiple instance learning framework. Our findings challenge assumptions that FMs universally outperform TS models. While FMs demonstrated utility in data-scarce scenarios, their performance converged with - and was in some cases surpassed by - TS models when sufficient labeled training data were available. Notably, extensive task-specific training markedly reduced clinically significant misgrading, misdiagnosis of challenging morphologies, and variability across different WSI scanners. Additionally, FMs used up to 35 times more energy than the TS model, raising concerns about their sustainability. Our results underscore that while FMs offer clear advantages for rapid prototyping and research, their role as a universal solution for clinically applicable medical AI remains uncertain. For high-stakes clinical applications, rigorous validation and consideration of task-specific training remain critically important. We advocate for integrating the strengths of FMs and end-to-end learning to achieve robust and resource-efficient AI pathology solutions fit for clinical use.