 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePublishing FAIR and Machine-actionable Reviews in Materials Science: The Case for Symbolic Knowledge in Neuro-symbolic Artificial Intelligence
Jan 08, 2026Scientific reviews are central to knowledge integration in materials science, yet their key insights remain locked in narrative text and static PDF tables, limiting reuse by humans and machines alike. This article presents a case study in atomic layer deposition and etching (ALD/E) where we publish review tables as FAIR, machine-actionable comparisons in the Open Research Knowledge Graph (ORKG), turning them into structured, queryable knowledge. Building on this, we contrast symbolic querying over ORKG with large language model-based querying, and argue that a curated symbolic layer should remain the backbone of reliable neurosymbolic AI in materials science, with LLMs serving as complementary, symbolically grounded interfaces rather than standalone sources of truth.
Towards AI-Supported Research: a Vision of the TIB AIssistant
Dec 18, 2025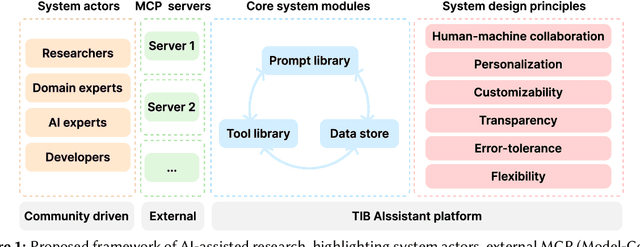
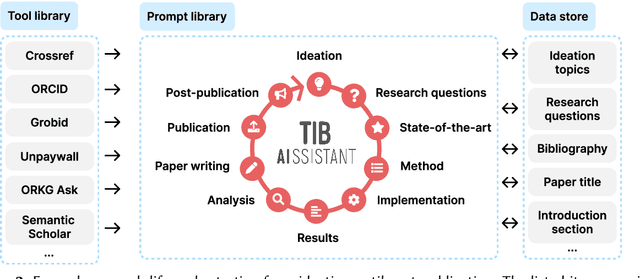
The rapid advancements in Generative AI and Large Language Models promise to transform the way research is conducted, potentially offering unprecedented opportunities to augment scholarly workflows. However, effectively integrating AI into research remains a challenge due to varying domain requirements, limited AI literacy, the complexity of coordinating tools and agents, and the unclear accuracy of Generative AI in research. We present the vision of the TIB AIssistant, a domain-agnostic human-machine collaborative platform designed to support researchers across disciplines in scientific discovery, with AI assistants supporting tasks across the research life cycle. The platform offers modular components - including prompt and tool libraries, a shared data store, and a flexible orchestration framework - that collectively facilitate ideation, literature analysis, methodology development, data analysis, and scholarly writing. We describe the conceptual framework, system architecture, and implementation of an early prototype that demonstrates the feasibility and potential impact of our approach.
Toward Purpose-oriented Topic Model Evaluation enabled by Large Language Models
Sep 08, 2025This study presents a framework for automated evaluation of dynamically evolving topic models using Large Language Models (LLMs). Topic modeling is essential for organizing and retrieving scholarly content in digital library systems, helping users navigate complex and evolving knowledge domains. However, widely used automated metrics, such as coherence and diversity, often capture only narrow statistical patterns and fail to explain semantic failures in practice. We introduce a purpose-oriented evaluation framework that employs nine LLM-based metrics spanning four key dimensions of topic quality: lexical validity, intra-topic semantic soundness, inter-topic structural soundness, and document-topic alignment soundness. The framework is validated through adversarial and sampling-based protocols, and is applied across datasets spanning news articles, scholarly publications, and social media posts, as well as multiple topic modeling methods and open-source LLMs. Our analysis shows that LLM-based metrics provide interpretable, robust, and task-relevant assessments, uncovering critical weaknesses in topic models such as redundancy and semantic drift, which are often missed by traditional metrics. These results support the development of scalable, fine-grained evaluation tools for maintaining topic relevance in dynamic datasets. All code and data supporting this work are accessible at https://github.com/zhiyintan/topic-model-LLMjudgment.
Research Knowledge Graphs: the Shifting Paradigm of Scholarly Information Representation
Jun 08, 2025Sharing and reusing research artifacts, such as datasets, publications, or methods is a fundamental part of scientific activity, where heterogeneity of resources and metadata and the common practice of capturing information in unstructured publications pose crucial challenges. Reproducibility of research and finding state-of-the-art methods or data have become increasingly challenging. In this context, the concept of Research Knowledge Graphs (RKGs) has emerged, aiming at providing an easy to use and machine-actionable representation of research artifacts and their relations. That is facilitated through the use of established principles for data representation, the consistent adoption of globally unique persistent identifiers and the reuse and linking of vocabularies and data. This paper provides the first conceptualisation of the RKG vision, a categorisation of in-use RKGs together with a description of RKG building blocks and principles. We also survey real-world RKG implementations differing with respect to scale, schema, data, used vocabulary, and reliability of the contained data. We also characterise different RKG construction methodologies and provide a forward-looking perspective on the diverse applications, opportunities, and challenges associated with the RKG vision.
YESciEval: Robust LLM-as-a-Judge for Scientific Question Answering
May 20, 2025Large Language Models (LLMs) drive scientific question-answering on modern search engines, yet their evaluation robustness remains underexplored. We introduce YESciEval, an open-source framework that combines fine-grained rubric-based assessment with reinforcement learning to mitigate optimism bias in LLM evaluators. We release multidisciplinary scienceQ&A datasets, including adversarial variants, with evaluation scores from multiple LLMs. Independent of proprietary models and human feedback, our approach enables scalable, cost-free evaluation. By advancing reliable LLM-as-a-judge models, this work supports AI alignment and fosters robust, transparent evaluation essential for scientific inquiry and artificial general intelligence.
SemEval-2025 Task 5: LLMs4Subjects -- LLM-based Automated Subject Tagging for a National Technical Library's Open-Access Catalog
Apr 09, 2025



We present SemEval-2025 Task 5: LLMs4Subjects, a shared task on automated subject tagging for scientific and technical records in English and German using the GND taxonomy. Participants developed LLM-based systems to recommend top-k subjects, evaluated through quantitative metrics (precision, recall, F1-score) and qualitative assessments by subject specialists. Results highlight the effectiveness of LLM ensembles, synthetic data generation, and multilingual processing, offering insights into applying LLMs for digital library classification.
LLMs4SchemaDiscovery: A Human-in-the-Loop Workflow for Scientific Schema Mining with Large Language Models
Apr 01, 2025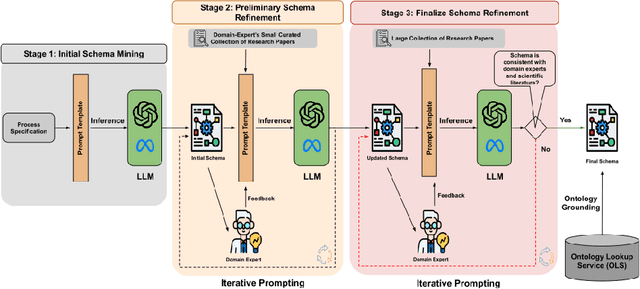
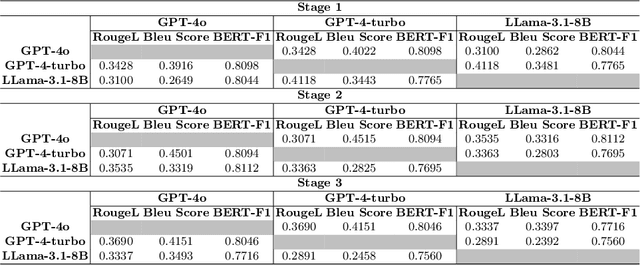
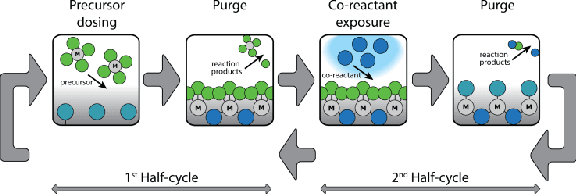
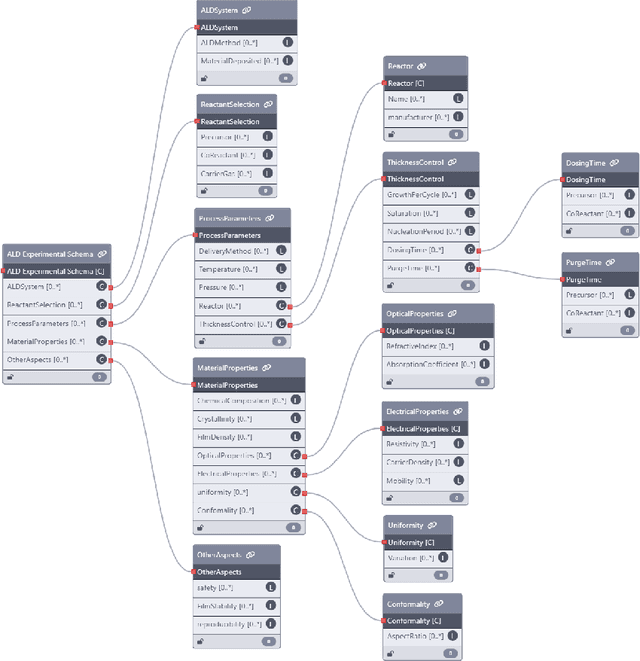
Extracting structured information from unstructured text is crucial for modeling real-world processes, but traditional schema mining relies on semi-structured data, limiting scalability. This paper introduces schema-miner, a novel tool that combines large language models with human feedback to automate and refine schema extraction. Through an iterative workflow, it organizes properties from text, incorporates expert input, and integrates domain-specific ontologies for semantic depth. Applied to materials science--specifically atomic layer deposition--schema-miner demonstrates that expert-guided LLMs generate semantically rich schemas suitable for diverse real-world applications.
OntoAligner: A Comprehensive Modular and Robust Python Toolkit for Ontology Alignment
Mar 27, 2025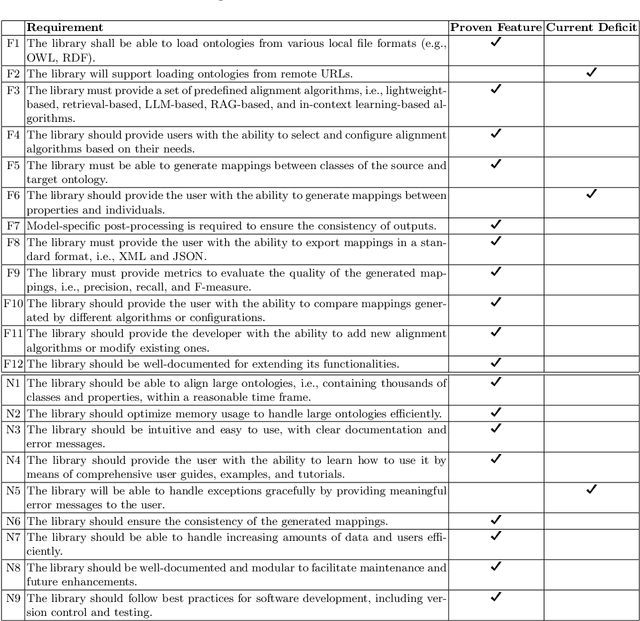
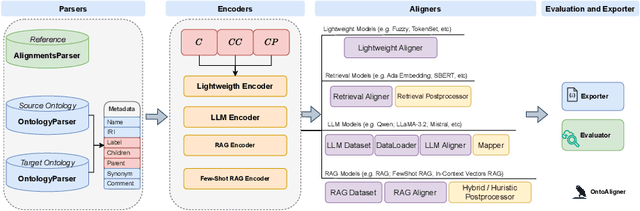
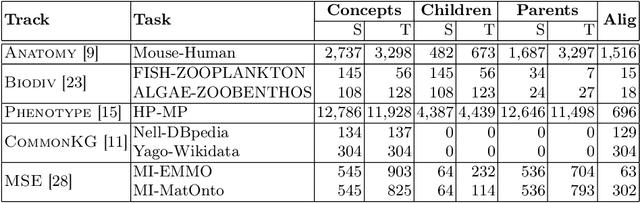

Ontology Alignment (OA) is fundamental for achieving semantic interoperability across diverse knowledge systems. We present OntoAligner, a comprehensive, modular, and robust Python toolkit for ontology alignment, designed to address current limitations with existing tools faced by practitioners. Existing tools are limited in scalability, modularity, and ease of integration with recent AI advances. OntoAligner provides a flexible architecture integrating existing lightweight OA techniques such as fuzzy matching but goes beyond by supporting contemporary methods with retrieval-augmented generation and large language models for OA. The framework prioritizes extensibility, enabling researchers to integrate custom alignment algorithms and datasets. This paper details the design principles, architecture, and implementation of the OntoAligner, demonstrating its utility through benchmarks on standard OA tasks. Our evaluation highlights OntoAligner's ability to handle large-scale ontologies efficiently with few lines of code while delivering high alignment quality. By making OntoAligner open-source, we aim to provide a resource that fosters innovation and collaboration within the OA community, empowering researchers and practitioners with a toolkit for reproducible OA research and real-world applications.
Bridging the Evaluation Gap: Leveraging Large Language Models for Topic Model Evaluation
Feb 11, 2025



This study presents a framework for automated evaluation of dynamically evolving topic taxonomies in scientific literature using Large Language Models (LLMs). In digital library systems, topic modeling plays a crucial role in efficiently organizing and retrieving scholarly content, guiding researchers through complex knowledge landscapes. As research domains proliferate and shift, traditional human centric and static evaluation methods struggle to maintain relevance. The proposed approach harnesses LLMs to measure key quality dimensions, such as coherence, repetitiveness, diversity, and topic-document alignment, without heavy reliance on expert annotators or narrow statistical metrics. Tailored prompts guide LLM assessments, ensuring consistent and interpretable evaluations across various datasets and modeling techniques. Experiments on benchmark corpora demonstrate the method's robustness, scalability, and adaptability, underscoring its value as a more holistic and dynamic alternative to conventional evaluation strategies.
Transforming Science with Large Language Models: A Survey on AI-assisted Scientific Discovery, Experimentation, Content Generation, and Evaluation
Feb 07, 2025
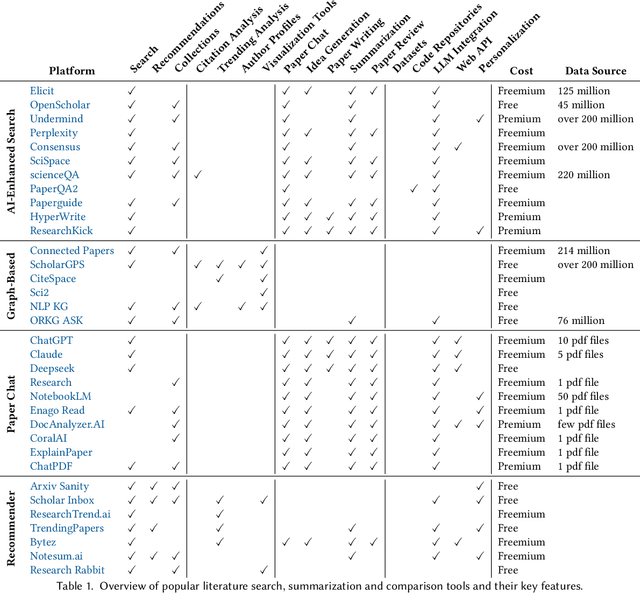
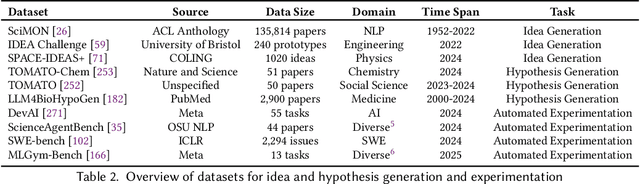
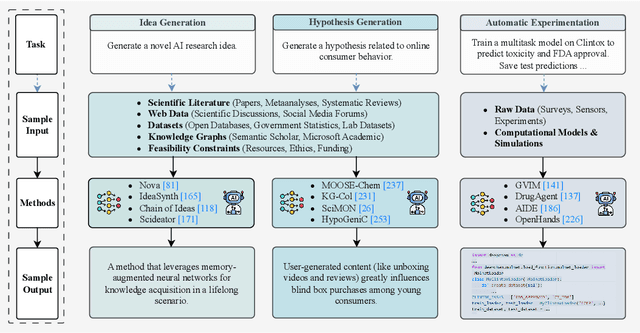
With the advent of large multimodal language models, science is now at a threshold of an AI-based technological transformation. Recently, a plethora of new AI models and tools has been proposed, promising to empower researchers and academics worldwide to conduct their research more effectively and efficiently. This includes all aspects of the research cycle, especially (1) searching for relevant literature; (2) generating research ideas and conducting experimentation; generating (3) text-based and (4) multimodal content (e.g., scientific figures and diagrams); and (5) AI-based automatic peer review. In this survey, we provide an in-depth overview over these exciting recent developments, which promise to fundamentally alter the scientific research process for good. Our survey covers the five aspects outlined above, indicating relevant datasets, methods and results (including evaluation) as well as limitations and scope for future research. Ethical concerns regarding shortcomings of these tools and potential for misuse (fake science, plagiarism, harms to research integrity) take a particularly prominent place in our discussion. We hope that our survey will not only become a reference guide for newcomers to the field but also a catalyst for new AI-based initiatives in the area of "AI4Science".