 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalLoc: Token-level Localization of Hallucinations for Vision Language Models
Jun 12, 2025



Hallucinations pose a significant challenge to the reliability of large vision-language models, making their detection essential for ensuring accuracy in critical applications. Current detection methods often rely on computationally intensive models, leading to high latency and resource demands. Their definitive outcomes also fail to account for real-world scenarios where the line between hallucinated and truthful information is unclear. To address these issues, we propose HalLoc, a dataset designed for efficient, probabilistic hallucination detection. It features 150K token-level annotated samples, including hallucination types, across Visual Question Answering (VQA), instruction-following, and image captioning tasks. This dataset facilitates the development of models that detect hallucinations with graded confidence, enabling more informed user interactions. Additionally, we introduce a baseline model trained on HalLoc, offering low-overhead, concurrent hallucination detection during generation. The model can be seamlessly integrated into existing VLMs, improving reliability while preserving efficiency. The prospect of a robust plug-and-play hallucination detection module opens new avenues for enhancing the trustworthiness of vision-language models in real-world applications. The HalLoc dataset and code are publicly available at: https://github.com/dbsltm/cvpr25_halloc.
Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates
May 28, 2025While pre-trained multimodal representations (e.g., CLIP) have shown impressive capabilities, they exhibit significant compositional vulnerabilities leading to counterintuitive judgments. We introduce Multimodal Adversarial Compositionality (MAC), a benchmark that leverages large language models (LLMs) to generate deceptive text samples to exploit these vulnerabilities across different modalities and evaluates them through both sample-wise attack success rate and group-wise entropy-based diversity. To improve zero-shot methods, we propose a self-training approach that leverages rejection-sampling fine-tuning with diversity-promoting filtering, which enhances both attack success rate and sample diversity. Using smaller language models like Llama-3.1-8B, our approach demonstrates superior performance in revealing compositional vulnerabilities across various multimodal representations, including images, videos, and audios.
LPOI: Listwise Preference Optimization for Vision Language Models
May 27, 2025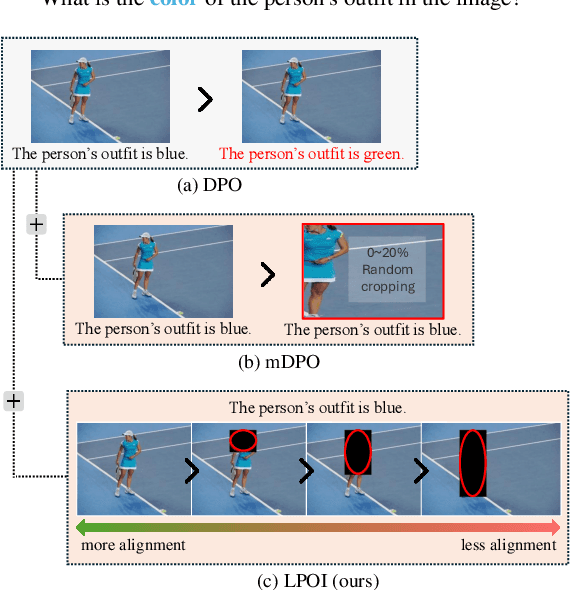
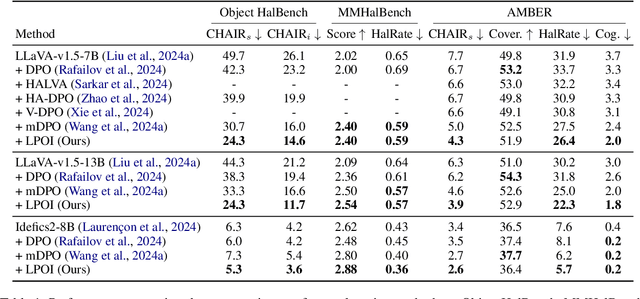
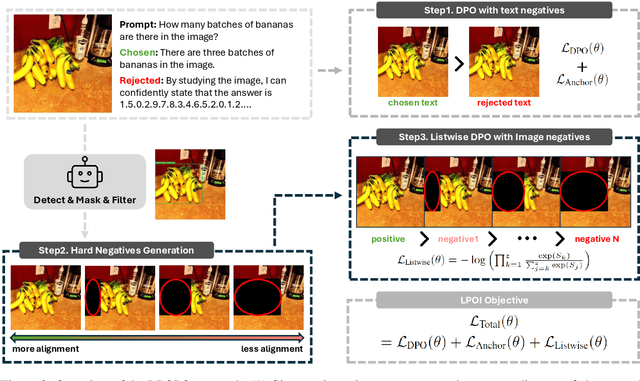

Aligning large VLMs with human preferences is a challenging task, as methods like RLHF and DPO often overfit to textual information or exacerbate hallucinations. Although augmenting negative image samples partially addresses these pitfalls, no prior work has employed listwise preference optimization for VLMs, due to the complexity and cost of constructing listwise image samples. In this work, we propose LPOI, the first object-aware listwise preference optimization developed for reducing hallucinations in VLMs. LPOI identifies and masks a critical object in the image, and then interpolates the masked region between the positive and negative images to form a sequence of incrementally more complete images. The model is trained to rank these images in ascending order of object visibility, effectively reducing hallucinations while retaining visual fidelity. LPOI requires no extra annotations beyond standard pairwise preference data, as it automatically constructs the ranked lists through object masking and interpolation. Comprehensive experiments on MMHalBench, AMBER, and Object HalBench confirm that LPOI outperforms existing preference optimization methods in reducing hallucinations and enhancing VLM performance. We make the code available at https://github.com/fatemehpesaran310/lpoi.
Multi-Domain Audio Question Answering Toward Acoustic Content Reasoning in The DCASE 2025 Challenge
May 12, 2025We present Task 5 of the DCASE 2025 Challenge: an Audio Question Answering (AQA) benchmark spanning multiple domains of sound understanding. This task defines three QA subsets (Bioacoustics, Temporal Soundscapes, and Complex QA) to test audio-language models on interactive question-answering over diverse acoustic scenes. We describe the dataset composition (from marine mammal calls to soundscapes and complex real-world clips), the evaluation protocol (top-1 accuracy with answer-shuffling robustness), and baseline systems (Qwen2-Audio-7B, AudioFlamingo 2, Gemini-2-Flash). Preliminary results on the development set are compared, showing strong variation across models and subsets. This challenge aims to advance the audio understanding and reasoning capabilities of audio-language models toward human-level acuity, which are crucial for enabling AI agents to perceive and interact about the world effectively.
ReSpec: Relevance and Specificity Grounded Online Filtering for Learning on Video-Text Data Streams
Apr 21, 2025The rapid growth of video-text data presents challenges in storage and computation during training. Online learning, which processes streaming data in real-time, offers a promising solution to these issues while also allowing swift adaptations in scenarios demanding real-time responsiveness. One strategy to enhance the efficiency and effectiveness of learning involves identifying and prioritizing data that enhances performance on target downstream tasks. We propose Relevance and Specificity-based online filtering framework (ReSpec) that selects data based on four criteria: (i) modality alignment for clean data, (ii) task relevance for target focused data, (iii) specificity for informative and detailed data, and (iv) efficiency for low-latency processing. Relevance is determined by the probabilistic alignment of incoming data with downstream tasks, while specificity employs the distance to a root embedding representing the least specific data as an efficient proxy for informativeness. By establishing reference points from target task data, ReSpec filters incoming data in real-time, eliminating the need for extensive storage and compute. Evaluating on large-scale datasets WebVid2M and VideoCC3M, ReSpec attains state-of-the-art performance on five zeroshot video retrieval tasks, using as little as 5% of the data while incurring minimal compute. The source code is available at https://github.com/cdjkim/ReSpec.
Meta-Continual Learning of Neural Fields
Apr 08, 2025Neural Fields (NF) have gained prominence as a versatile framework for complex data representation. This work unveils a new problem setting termed \emph{Meta-Continual Learning of Neural Fields} (MCL-NF) and introduces a novel strategy that employs a modular architecture combined with optimization-based meta-learning. Focused on overcoming the limitations of existing methods for continual learning of neural fields, such as catastrophic forgetting and slow convergence, our strategy achieves high-quality reconstruction with significantly improved learning speed. We further introduce Fisher Information Maximization loss for neural radiance fields (FIM-NeRF), which maximizes information gains at the sample level to enhance learning generalization, with proved convergence guarantee and generalization bound. We perform extensive evaluations across image, audio, video reconstruction, and view synthesis tasks on six diverse datasets, demonstrating our method's superiority in reconstruction quality and speed over existing MCL and CL-NF approaches. Notably, our approach attains rapid adaptation of neural fields for city-scale NeRF rendering with reduced parameter requirement.
How to Move Your Dragon: Text-to-Motion Synthesis for Large-Vocabulary Objects
Mar 06, 2025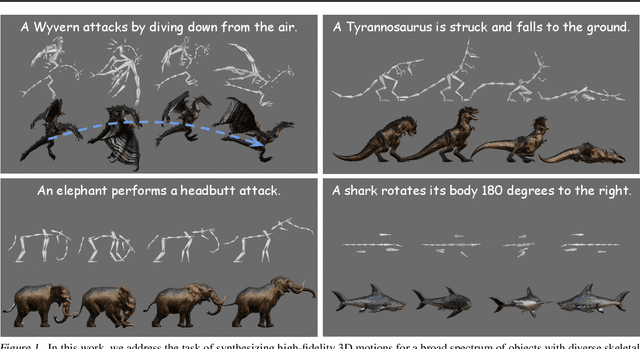

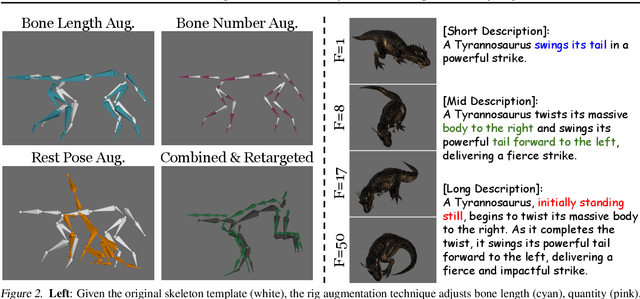
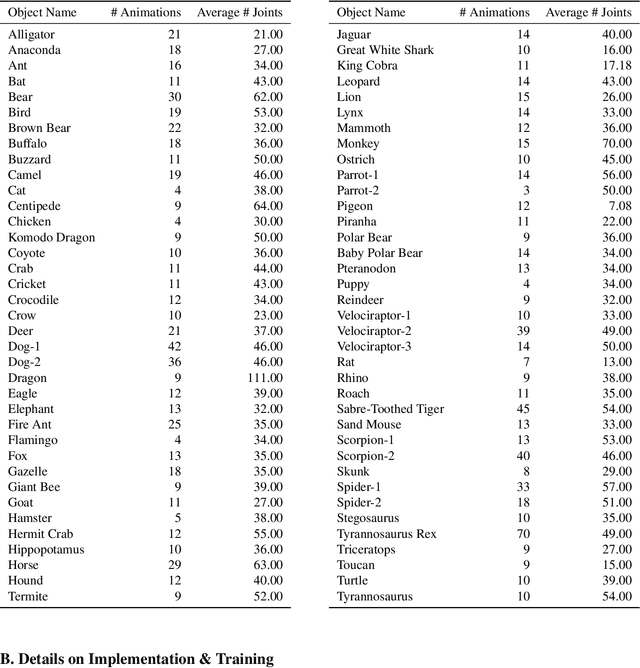
Motion synthesis for diverse object categories holds great potential for 3D content creation but remains underexplored due to two key challenges: (1) the lack of comprehensive motion datasets that include a wide range of high-quality motions and annotations, and (2) the absence of methods capable of handling heterogeneous skeletal templates from diverse objects. To address these challenges, we contribute the following: First, we augment the Truebones Zoo dataset, a high-quality animal motion dataset covering over 70 species, by annotating it with detailed text descriptions, making it suitable for text-based motion synthesis. Second, we introduce rig augmentation techniques that generate diverse motion data while preserving consistent dynamics, enabling models to adapt to various skeletal configurations. Finally, we redesign existing motion diffusion models to dynamically adapt to arbitrary skeletal templates, enabling motion synthesis for a diverse range of objects with varying structures. Experiments show that our method learns to generate high-fidelity motions from textual descriptions for diverse and even unseen objects, setting a strong foundation for motion synthesis across diverse object categories and skeletal templates. Qualitative results are available on this link: t2m4lvo.github.io
Distilling Reinforcement Learning Algorithms for In-Context Model-Based Planning
Feb 26, 2025Recent studies have shown that Transformers can perform in-context reinforcement learning (RL) by imitating existing RL algorithms, enabling sample-efficient adaptation to unseen tasks without parameter updates. However, these models also inherit the suboptimal behaviors of the RL algorithms they imitate. This issue primarily arises due to the gradual update rule employed by those algorithms. Model-based planning offers a promising solution to this limitation by allowing the models to simulate potential outcomes before taking action, providing an additional mechanism to deviate from the suboptimal behavior. Rather than learning a separate dynamics model, we propose Distillation for In-Context Planning (DICP), an in-context model-based RL framework where Transformers simultaneously learn environment dynamics and improve policy in-context. We evaluate DICP across a range of discrete and continuous environments, including Darkroom variants and Meta-World. Our results show that DICP achieves state-of-the-art performance while requiring significantly fewer environment interactions than baselines, which include both model-free counterparts and existing meta-RL methods.
Sample Selection via Contrastive Fragmentation for Noisy Label Regression
Feb 25, 2025As with many other problems, real-world regression is plagued by the presence of noisy labels, an inevitable issue that demands our attention. Fortunately, much real-world data often exhibits an intrinsic property of continuously ordered correlations between labels and features, where data points with similar labels are also represented with closely related features. In response, we propose a novel approach named ConFrag, where we collectively model the regression data by transforming them into disjoint yet contrasting fragmentation pairs. This enables the training of more distinctive representations, enhancing the ability to select clean samples. Our ConFrag framework leverages a mixture of neighboring fragments to discern noisy labels through neighborhood agreement among expert feature extractors. We extensively perform experiments on six newly curated benchmark datasets of diverse domains, including age prediction, price prediction, and music production year estimation. We also introduce a metric called Error Residual Ratio (ERR) to better account for varying degrees of label noise. Our approach consistently outperforms fourteen state-of-the-art baselines, being robust against symmetric and random Gaussian label noise.
Is a Peeled Apple Still Red? Evaluating LLMs' Ability for Conceptual Combination with Property Type
Feb 10, 2025Conceptual combination is a cognitive process that merges basic concepts, enabling the creation of complex expressions. During this process, the properties of combination (e.g., the whiteness of a peeled apple) can be inherited from basic concepts, newly emerge, or be canceled. However, previous studies have evaluated a limited set of properties and have not examined the generative process. To address this gap, we introduce the Conceptual Combination with Property Type dataset (CCPT), which consists of 12.3K annotated triplets of noun phrases, properties, and property types. Using CCPT, we establish three types of tasks to evaluate LLMs for conceptual combination thoroughly. Our key findings are threefold: (1) Our automatic metric grading property emergence and cancellation closely corresponds with human judgments. (2) LLMs, including OpenAI's o1, struggle to generate noun phrases which possess given emergent properties. (3) Our proposed method, inspired by cognitive psychology model that explains how relationships between concepts are formed, improves performances in all generative tasks. The dataset and experimental code are available at https://github.com/seokwon99/CCPT.git.