 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresenting Anatomical Trees by Denoising Diffusion of Implicit Neural Fields
Mar 13, 2024Anatomical trees play a central role in clinical diagnosis and treatment planning. However, accurately representing anatomical trees is challenging due to their varying and complex topology and geometry. Traditional methods for representing tree structures, captured using medical imaging, while invaluable for visualizing vascular and bronchial networks, exhibit drawbacks in terms of limited resolution, flexibility, and efficiency. Recently, implicit neural representations (INRs) have emerged as a powerful tool for representing shapes accurately and efficiently. We propose a novel approach for representing anatomical trees using INR, while also capturing the distribution of a set of trees via denoising diffusion in the space of INRs. We accurately capture the intricate geometries and topologies of anatomical trees at any desired resolution. Through extensive qualitative and quantitative evaluation, we demonstrate high-fidelity tree reconstruction with arbitrary resolution yet compact storage, and versatility across anatomical sites and tree complexities.
DermSynth3D: Synthesis of in-the-wild Annotated Dermatology Images
May 25, 2023



In recent years, deep learning (DL) has shown great potential in the field of dermatological image analysis. However, existing datasets in this domain have significant limitations, including a small number of image samples, limited disease conditions, insufficient annotations, and non-standardized image acquisitions. To address these shortcomings, we propose a novel framework called DermSynth3D. DermSynth3D blends skin disease patterns onto 3D textured meshes of human subjects using a differentiable renderer and generates 2D images from various camera viewpoints under chosen lighting conditions in diverse background scenes. Our method adheres to top-down rules that constrain the blending and rendering process to create 2D images with skin conditions that mimic in-the-wild acquisitions, ensuring more meaningful results. The framework generates photo-realistic 2D dermoscopy images and the corresponding dense annotations for semantic segmentation of the skin, skin conditions, body parts, bounding boxes around lesions, depth maps, and other 3D scene parameters, such as camera position and lighting conditions. DermSynth3D allows for the creation of custom datasets for various dermatology tasks. We demonstrate the effectiveness of data generated using DermSynth3D by training DL models on synthetic data and evaluating them on various dermatology tasks using real 2D dermatological images. We make our code publicly available at https://github.com/sfu-mial/DermSynth3D.
MEnsA: Mix-up Ensemble Average for Unsupervised Multi Target Domain Adaptation on 3D Point Clouds
Apr 06, 2023Unsupervised domain adaptation (UDA) addresses the problem of distribution shift between the unlabelled target domain and labelled source domain. While the single target domain adaptation (STDA) is well studied in the literature for both 2D and 3D vision tasks, multi-target domain adaptation (MTDA) is barely explored for 3D data despite its wide real-world applications such as autonomous driving systems for various geographical and climatic conditions. We establish an MTDA baseline for 3D point cloud data by proposing to mix the feature representations from all domains together to achieve better domain adaptation performance by an ensemble average, which we call Mixup Ensemble Average or MEnsA. With the mixed representation, we use a domain classifier to improve at distinguishing the feature representations of source domain from those of target domains in a shared latent space. In empirical validations on the challenging PointDA-10 dataset, we showcase a clear benefit of our simple method over previous unsupervised STDA and MTDA methods by large margins (up to 17.10% and 4.76% on averaged over all domain shifts).
Deep Learning based Dimple Detection for Quantitative Fractography
Jul 05, 2020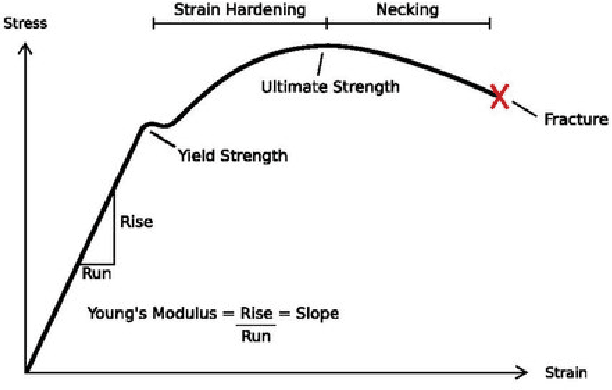

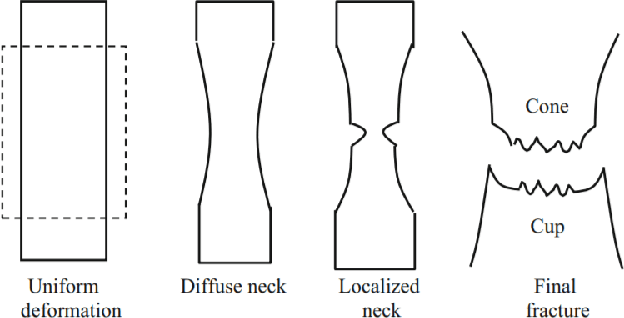
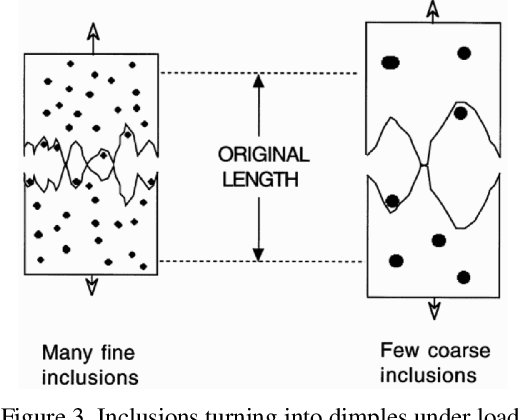
In this work, we try to address the challenging problem of dimple detection and segmentation in Titanium alloys using machine learning methods, especially neural networks. The images i.e. fractographs are obtained using a Scanning Election Microscope (SEM). To determine the cause of fracture in metals we address the problem of segmentation of dimples in fractographs i.e. the fracture surface of metals using supervised machine learning methods. Determining the cause of fracture would help us in material property, mechanical property prediction and development of new fracture-resistant materials. This method would also help in correlating the topography of the fracture surface with the mechanical properties of the material. Our proposed novel model achieves the best performance as compared to other previous approaches. To the best of our knowledge, this is one the first work in fractography using fully convolutional neural networks with self-attention for supervised learning of dimple fractography, though it can be easily extended to account for brittle characteristics as well.
NTIRE 2020 Challenge on Image Demoireing: Methods and Results
May 06, 2020



This paper reviews the Challenge on Image Demoireing that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2020. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. The challenge was divided into two tracks. Track 1 targeted the single image demoireing problem, which seeks to remove moire patterns from a single image. Track 2 focused on the burst demoireing problem, where a set of degraded moire images of the same scene were provided as input, with the goal of producing a single demoired image as output. The methods were ranked in terms of their fidelity, measured using the peak signal-to-noise ratio (PSNR) between the ground truth clean images and the restored images produced by the participants' methods. The tracks had 142 and 99 registered participants, respectively, with a total of 14 and 6 submissions in the final testing stage. The entries span the current state-of-the-art in image and burst image demoireing problems.
GA-GAN: CT reconstruction from Biplanar DRRs using GAN with Guided Attention
Oct 13, 2019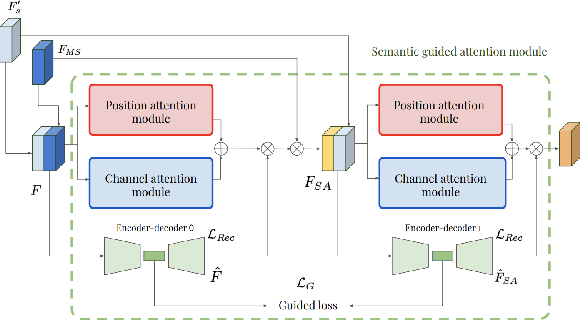
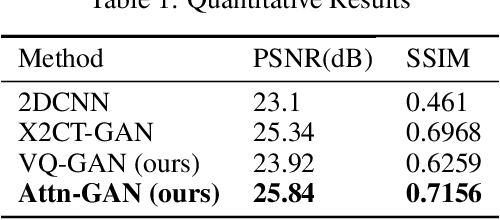
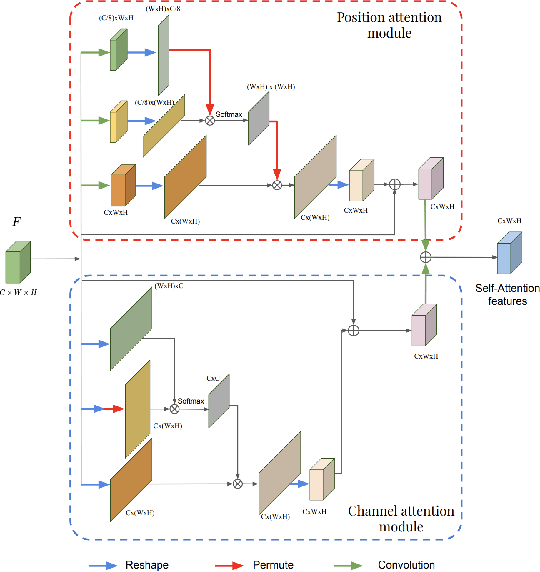
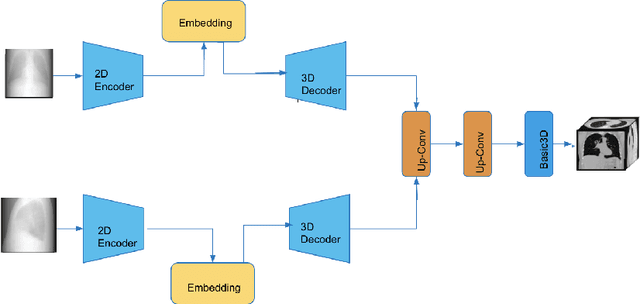
This work investigates the use of guided attention in the reconstruction of CTvolumes from biplanar DRRs. We try to improve the visual image quality of the CT reconstruction using Guided Attention based GANs (GA-GAN). We also consider the use of Vector Quantization (VQ) for the CT reconstruction so that the memory usage can be reduced, maintaining the same visual image quality. To the best of our knowledge no work has been done before that explores the Vector Quantization for this purpose. Although our findings show that our approaches outperform the previous works, still there is a lot of room for improvement.
Multi-scale guided attention for medical image segmentation
Jun 07, 2019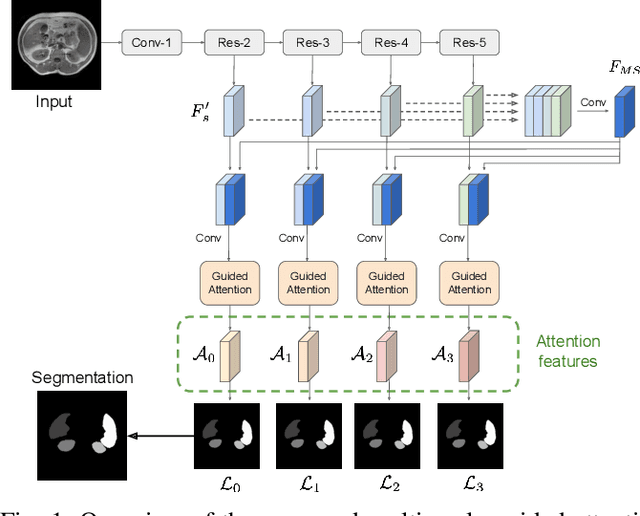
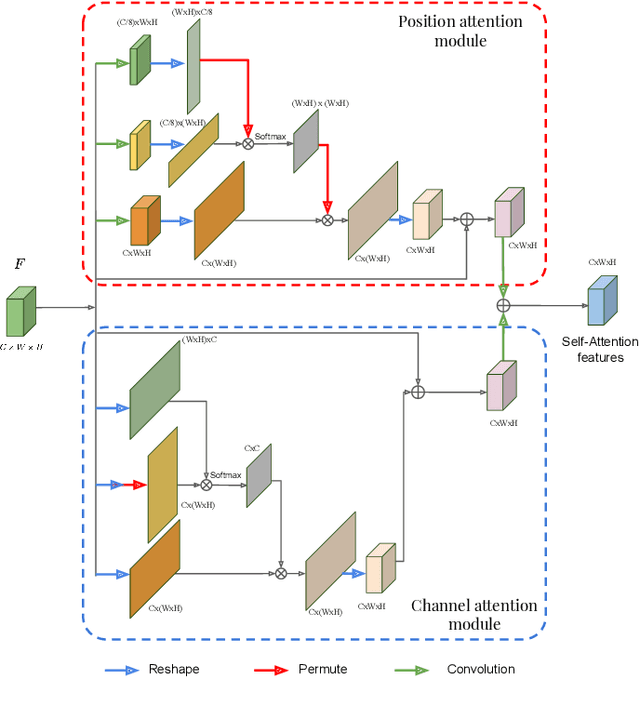
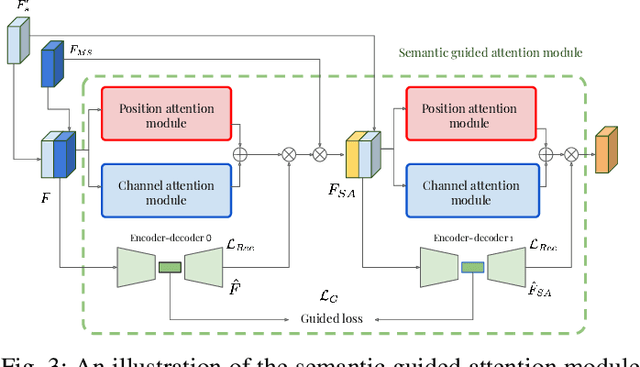
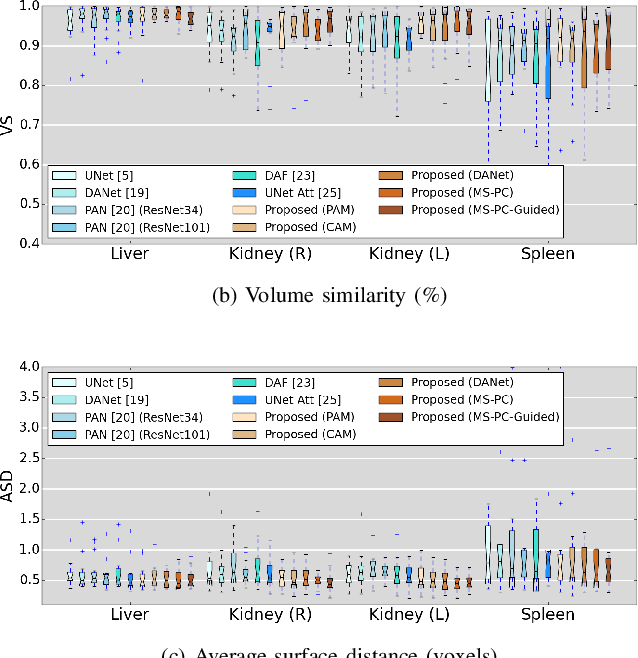
Even though convolutional neural networks (CNNs) are driving progress in medical image segmentation, standard models still have some drawbacks. First, the use of multi-scale approaches, i.e., encoder-decoder architectures, leads to a redundant use of information, where similar low-level features are extracted multiple times at multiple scales. Second, long-range feature dependencies are not efficiently modeled, resulting in non-optimal discriminative feature representations associated with each semantic class. In this paper we attempt to overcome these limitations with the proposed architecture, by capturing richer contextual dependencies based on the use of guided self-attention mechanisms. This approach is able to integrate local features with their corresponding global dependencies, as well as highlight interdependent channel maps in an adaptive manner. Further, the additional loss between different modules guides the attention mechanisms to remove the noise and focus on more discriminant regions of the image by emphasizing relevant feature associations. We evaluate the proposed model in the context of abdominal organ segmentation on magnetic resonance imaging (MRI). A series of ablation experiments support the importance of these attention modules in the proposed architecture. In addition, compared to other state-of-the-art segmentation networks our model yields better segmentation performance, increasing the accuracy of the predictions while reducing the standard deviation. This demonstrates the efficiency of our approach to generate precise and reliable automatic segmentations of medical images. Our code and the trained model are made publicly available at: https://github.com/sinAshish/Multi-Scale-Attention