 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Efficient Multi-Task Segmentation using Contrastive Learning
Sep 23, 2020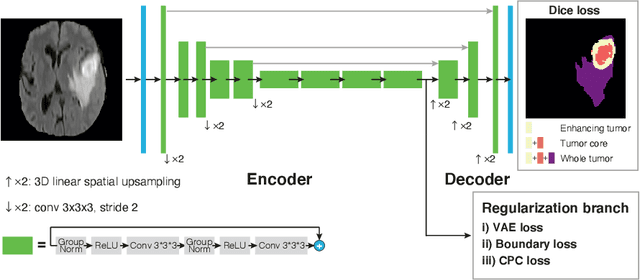
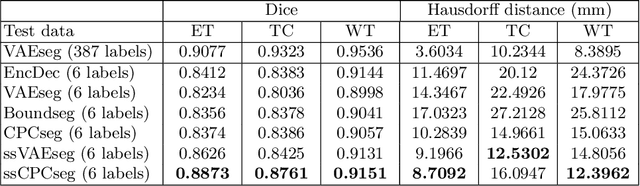
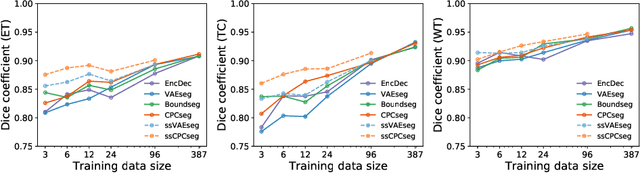
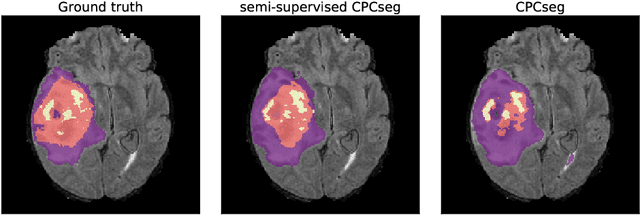
Obtaining annotations for 3D medical images is expensive and time-consuming, despite its importance for automating segmentation tasks. Although multi-task learning is considered an effective method for training segmentation models using small amounts of annotated data, a systematic understanding of various subtasks is still lacking. In this study, we propose a multi-task segmentation model with a contrastive learning based subtask and compare its performance with other multi-task models, varying the number of labeled data for training. We further extend our model so that it can utilize unlabeled data through the regularization branch in a semi-supervised manner. We experimentally show that our proposed method outperforms other multi-task methods including the state-of-the-art fully supervised model when the amount of annotated data is limited.
GA-GAN: CT reconstruction from Biplanar DRRs using GAN with Guided Attention
Oct 13, 2019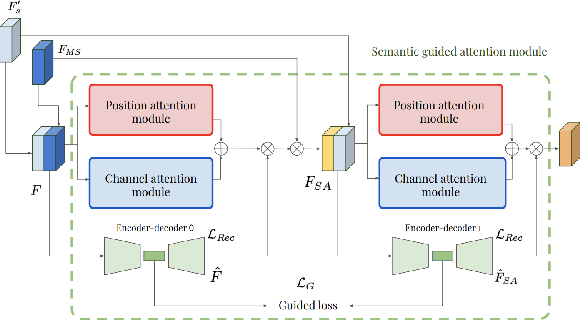
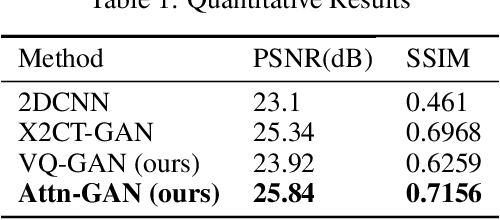
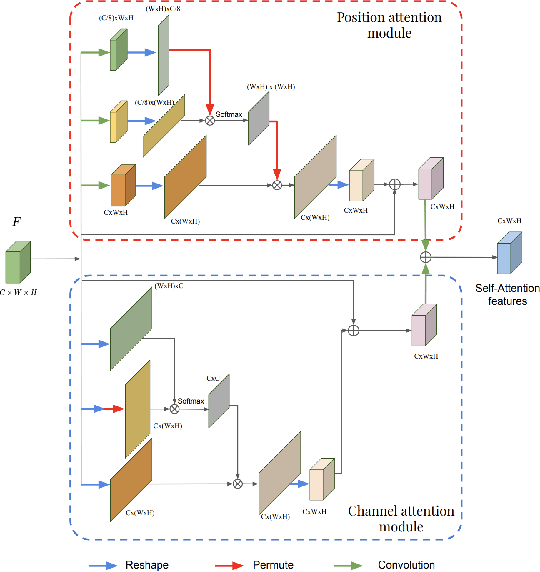
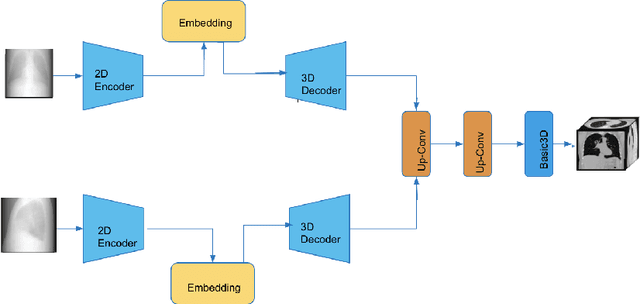
This work investigates the use of guided attention in the reconstruction of CTvolumes from biplanar DRRs. We try to improve the visual image quality of the CT reconstruction using Guided Attention based GANs (GA-GAN). We also consider the use of Vector Quantization (VQ) for the CT reconstruction so that the memory usage can be reduced, maintaining the same visual image quality. To the best of our knowledge no work has been done before that explores the Vector Quantization for this purpose. Although our findings show that our approaches outperform the previous works, still there is a lot of room for improvement.