 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Efficient Multi-Task Segmentation using Contrastive Learning
Paper and Code
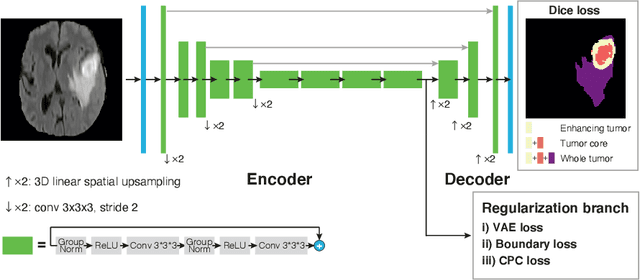
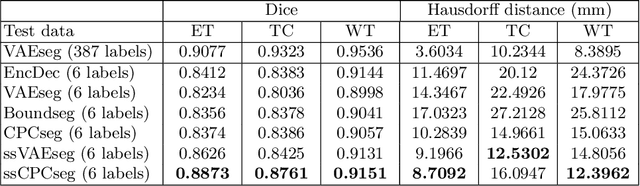
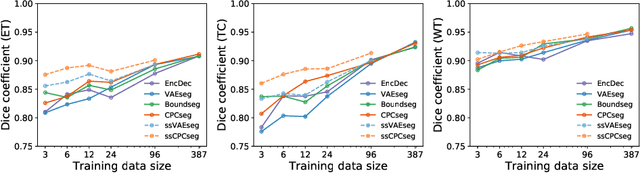
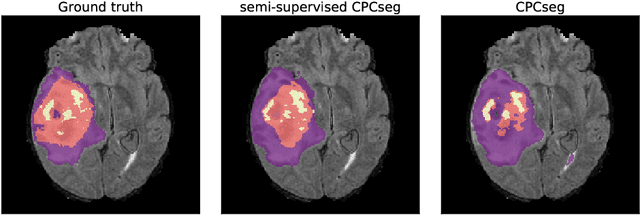
Obtaining annotations for 3D medical images is expensive and time-consuming, despite its importance for automating segmentation tasks. Although multi-task learning is considered an effective method for training segmentation models using small amounts of annotated data, a systematic understanding of various subtasks is still lacking. In this study, we propose a multi-task segmentation model with a contrastive learning based subtask and compare its performance with other multi-task models, varying the number of labeled data for training. We further extend our model so that it can utilize unlabeled data through the regularization branch in a semi-supervised manner. We experimentally show that our proposed method outperforms other multi-task methods including the state-of-the-art fully supervised model when the amount of annotated data is limited.