 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraffic Sign Recognition
Traffic sign recognition is the process of identifying and categorizing different types of traffic signs in images or videos.
Papers and Code
From Snow to Rain: Evaluating Robustness, Calibration, and Complexity of Model-Based Robust Training
Jan 14, 2026Robustness to natural corruptions remains a critical challenge for reliable deep learning, particularly in safety-sensitive domains. We study a family of model-based training approaches that leverage a learned nuisance variation model to generate realistic corruptions, as well as new hybrid strategies that combine random coverage with adversarial refinement in nuisance space. Using the Challenging Unreal and Real Environments for Traffic Sign Recognition dataset (CURE-TSR), with Snow and Rain corruptions, we evaluate accuracy, calibration, and training complexity across corruption severities. Our results show that model-based methods consistently outperform baselines Vanilla, Adversarial Training, and AugMix baselines, with model-based adversarial training providing the strongest robustness under across all corruptions but at the expense of higher computation and model-based data augmentation achieving comparable robustness with $T$ less computational complexity without incurring a statistically significant drop in performance. These findings highlight the importance of learned nuisance models for capturing natural variability, and suggest a promising path toward more resilient and calibrated models under challenging conditions.
Rectifying Adversarial Examples Using Their Vulnerabilities
Jan 01, 2026Deep neural network-based classifiers are prone to errors when processing adversarial examples (AEs). AEs are minimally perturbed input data undetectable to humans posing significant risks to security-dependent applications. Hence, extensive research has been undertaken to develop defense mechanisms that mitigate their threats. Most existing methods primarily focus on discriminating AEs based on the input sample features, emphasizing AE detection without addressing the correct sample categorization before an attack. While some tasks may only require mere rejection on detected AEs, others necessitate identifying the correct original input category such as traffic sign recognition in autonomous driving. The objective of this study is to propose a method for rectifying AEs to estimate the correct labels of their original inputs. Our method is based on re-attacking AEs to move them beyond the decision boundary for accurate label prediction, effectively addressing the issue of rectifying minimally perceptible AEs created using white-box attack methods. However, challenge remains with respect to effectively rectifying AEs produced by black-box attacks at a distance from the boundary, or those misclassified into low-confidence categories by targeted attacks. By adopting a straightforward approach of only considering AEs as inputs, the proposed method can address diverse attacks while avoiding the requirement of parameter adjustments or preliminary training. Results demonstrate that the proposed method exhibits consistent performance in rectifying AEs generated via various attack methods, including targeted and black-box attacks. Moreover, it outperforms conventional rectification and input transformation methods in terms of stability against various attacks.
Read or Ignore? A Unified Benchmark for Typographic-Attack Robustness and Text Recognition in Vision-Language Models
Dec 10, 2025Large vision-language models (LVLMs) are vulnerable to typographic attacks, where misleading text within an image overrides visual understanding. Existing evaluation protocols and defenses, largely focused on object recognition, implicitly encourage ignoring text to achieve robustness; however, real-world scenarios often require joint reasoning over both objects and text (e.g., recognizing pedestrians while reading traffic signs). To address this, we introduce a novel task, Read-or-Ignore VQA (RIO-VQA), which formalizes selective text use in visual question answering (VQA): models must decide, from context, when to read text and when to ignore it. For evaluation, we present the Read-or-Ignore Benchmark (RIO-Bench), a standardized dataset and protocol that, for each real image, provides same-scene counterfactuals (read / ignore) by varying only the textual content and question type. Using RIO-Bench, we show that strong LVLMs and existing defenses fail to balance typographic robustness and text-reading capability, highlighting the need for improved approaches. Finally, RIO-Bench enables a novel data-driven defense that learns adaptive selective text use, moving beyond prior non-adaptive, text-ignoring defenses. Overall, this work reveals a fundamental misalignment between the existing evaluation scope and real-world requirements, providing a principled path toward reliable LVLMs. Our Project Page is at https://turingmotors.github.io/rio-vqa/.
T2I-Based Physical-World Appearance Attack against Traffic Sign Recognition Systems in Autonomous Driving
Nov 17, 2025Traffic Sign Recognition (TSR) systems play a critical role in Autonomous Driving (AD) systems, enabling real-time detection of road signs, such as STOP and speed limit signs. While these systems are increasingly integrated into commercial vehicles, recent research has exposed their vulnerability to physical-world adversarial appearance attacks. In such attacks, carefully crafted visual patterns are misinterpreted by TSR models as legitimate traffic signs, while remaining inconspicuous or benign to human observers. However, existing adversarial appearance attacks suffer from notable limitations. Pixel-level perturbation-based methods often lack stealthiness and tend to overfit to specific surrogate models, resulting in poor transferability to real-world TSR systems. On the other hand, text-to-image (T2I) diffusion model-based approaches demonstrate limited effectiveness and poor generalization to out-of-distribution sign types. In this paper, we present DiffSign, a novel T2I-based appearance attack framework designed to generate physically robust, highly effective, transferable, practical, and stealthy appearance attacks against TSR systems. To overcome the limitations of prior approaches, we propose a carefully designed attack pipeline that integrates CLIP-based loss and masked prompts to improve attack focus and controllability. We also propose two novel style customization methods to guide visual appearance and improve out-of-domain traffic sign attack generalization and attack stealthiness. We conduct extensive evaluations of DiffSign under varied real-world conditions, including different distances, angles, light conditions, and sign categories. Our method achieves an average physical-world attack success rate of 83.3%, leveraging DiffSign's high effectiveness in attack transferability.
Trapped by Their Own Light: Deployable and Stealth Retroreflective Patch Attacks on Traffic Sign Recognition Systems
Nov 13, 2025Traffic sign recognition plays a critical role in ensuring safe and efficient transportation of autonomous vehicles but remain vulnerable to adversarial attacks using stickers or laser projections. While existing attack vectors demonstrate security concerns, they suffer from visual detectability or implementation constraints, suggesting unexplored vulnerability surfaces in TSR systems. We introduce the Adversarial Retroreflective Patch (ARP), a novel attack vector that combines the high deployability of patch attacks with the stealthiness of laser projections by utilizing retroreflective materials activated only under victim headlight illumination. We develop a retroreflection simulation method and employ black-box optimization to maximize attack effectiveness. ARP achieves $\geq$93.4\% success rate in dynamic scenarios at 35 meters and $\geq$60\% success rate against commercial TSR systems in real-world conditions. Our user study demonstrates that ARP attacks maintain near-identical stealthiness to benign signs while achieving $\geq$1.9\% higher stealthiness scores than previous patch attacks. We propose the DPR Shield defense, employing strategically placed polarized filters, which achieves $\geq$75\% defense success rates for stop signs and speed limit signs against micro-prism patches.
Enhancing LLM-based Autonomous Driving with Modular Traffic Light and Sign Recognition
Nov 18, 2025Large Language Models (LLMs) are increasingly used for decision-making and planning in autonomous driving, showing promising reasoning capabilities and potential to generalize across diverse traffic situations. However, current LLM-based driving agents lack explicit mechanisms to enforce traffic rules and often struggle to reliably detect small, safety-critical objects such as traffic lights and signs. To address this limitation, we introduce TLS-Assist, a modular redundancy layer that augments LLM-based autonomous driving agents with explicit traffic light and sign recognition. TLS-Assist converts detections into structured natural language messages that are injected into the LLM input, enforcing explicit attention to safety-critical cues. The framework is plug-and-play, model-agnostic, and supports both single-view and multi-view camera setups. We evaluate TLS-Assist in a closed-loop setup on the LangAuto benchmark in CARLA. The results demonstrate relative driving performance improvements of up to 14% over LMDrive and 7% over BEVDriver, while consistently reducing traffic light and sign infractions. We publicly release the code and models on https://github.com/iis-esslingen/TLS-Assist.
Information-Theoretic Greedy Layer-wise Training for Traffic Sign Recognition
Oct 31, 2025


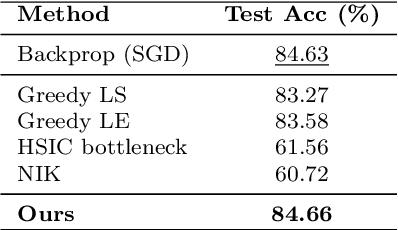
Modern deep neural networks (DNNs) are typically trained with a global cross-entropy loss in a supervised end-to-end manner: neurons need to store their outgoing weights; training alternates between a forward pass (computation) and a top-down backward pass (learning) which is biologically implausible. Alternatively, greedy layer-wise training eliminates the need for cross-entropy loss and backpropagation. By avoiding the computation of intermediate gradients and the storage of intermediate outputs, it reduces memory usage and helps mitigate issues such as vanishing or exploding gradients. However, most existing layer-wise training approaches have been evaluated only on relatively small datasets with simple deep architectures. In this paper, we first systematically analyze the training dynamics of popular convolutional neural networks (CNNs) trained by stochastic gradient descent (SGD) through an information-theoretic lens. Our findings reveal that networks converge layer-by-layer from bottom to top and that the flow of information adheres to a Markov information bottleneck principle. Building on these observations, we propose a novel layer-wise training approach based on the recently developed deterministic information bottleneck (DIB) and the matrix-based R\'enyi's $\alpha$-order entropy functional. Specifically, each layer is trained jointly with an auxiliary classifier that connects directly to the output layer, enabling the learning of minimal sufficient task-relevant representations. We empirically validate the effectiveness of our training procedure on CIFAR-10 and CIFAR-100 using modern deep CNNs and further demonstrate its applicability to a practical task involving traffic sign recognition. Our approach not only outperforms existing layer-wise training baselines but also achieves performance comparable to SGD.
Robust and Safe Traffic Sign Recognition using N-version with Weighted Voting
Jul 09, 2025Autonomous driving is rapidly advancing as a key application of machine learning, yet ensuring the safety of these systems remains a critical challenge. Traffic sign recognition, an essential component of autonomous vehicles, is particularly vulnerable to adversarial attacks that can compromise driving safety. In this paper, we propose an N-version machine learning (NVML) framework that integrates a safety-aware weighted soft voting mechanism. Our approach utilizes Failure Mode and Effects Analysis (FMEA) to assess potential safety risks and assign dynamic, safety-aware weights to the ensemble outputs. We evaluate the robustness of three-version NVML systems employing various voting mechanisms against adversarial samples generated using the Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD) attacks. Experimental results demonstrate that our NVML approach significantly enhances the robustness and safety of traffic sign recognition systems under adversarial conditions.
DriveQA: Passing the Driving Knowledge Test
Aug 29, 2025



If a Large Language Model (LLM) were to take a driving knowledge test today, would it pass? Beyond standard spatial and visual question-answering (QA) tasks on current autonomous driving benchmarks, driving knowledge tests require a complete understanding of all traffic rules, signage, and right-of-way principles. To pass this test, human drivers must discern various edge cases that rarely appear in real-world datasets. In this work, we present DriveQA, an extensive open-source text and vision-based benchmark that exhaustively covers traffic regulations and scenarios. Through our experiments using DriveQA, we show that (1) state-of-the-art LLMs and Multimodal LLMs (MLLMs) perform well on basic traffic rules but exhibit significant weaknesses in numerical reasoning and complex right-of-way scenarios, traffic sign variations, and spatial layouts, (2) fine-tuning on DriveQA improves accuracy across multiple categories, particularly in regulatory sign recognition and intersection decision-making, (3) controlled variations in DriveQA-V provide insights into model sensitivity to environmental factors such as lighting, perspective, distance, and weather conditions, and (4) pretraining on DriveQA enhances downstream driving task performance, leading to improved results on real-world datasets such as nuScenes and BDD, while also demonstrating that models can internalize text and synthetic traffic knowledge to generalize effectively across downstream QA tasks.
Securing Traffic Sign Recognition Systems in Autonomous Vehicles
Jun 06, 2025Deep Neural Networks (DNNs) are widely used for traffic sign recognition because they can automatically extract high-level features from images. These DNNs are trained on large-scale datasets obtained from unknown sources. Therefore, it is important to ensure that the models remain secure and are not compromised or poisoned during training. In this paper, we investigate the robustness of DNNs trained for traffic sign recognition. First, we perform the error-minimizing attacks on DNNs used for traffic sign recognition by adding imperceptible perturbations on training data. Then, we propose a data augmentation-based training method to mitigate the error-minimizing attacks. The proposed training method utilizes nonlinear transformations to disrupt the perturbations and improve the model robustness. We experiment with two well-known traffic sign datasets to demonstrate the severity of the attack and the effectiveness of our mitigation scheme. The error-minimizing attacks reduce the prediction accuracy of the DNNs from 99.90% to 10.6%. However, our mitigation scheme successfully restores the prediction accuracy to 96.05%. Moreover, our approach outperforms adversarial training in mitigating the error-minimizing attacks. Furthermore, we propose a detection model capable of identifying poisoned data even when the perturbations are imperceptible to human inspection. Our detection model achieves a success rate of over 99% in identifying the attack. This research highlights the need to employ advanced training methods for DNNs in traffic sign recognition systems to mitigate the effects of data poisoning attacks.