 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMtcnn
Papers and Code
Autonomous AI Surveillance: Multimodal Deep Learning for Cognitive and Behavioral Monitoring
Jul 02, 2025
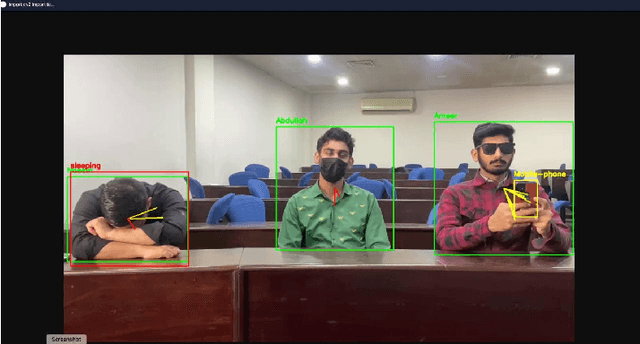
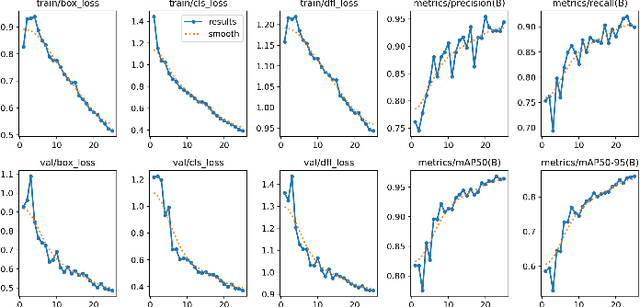
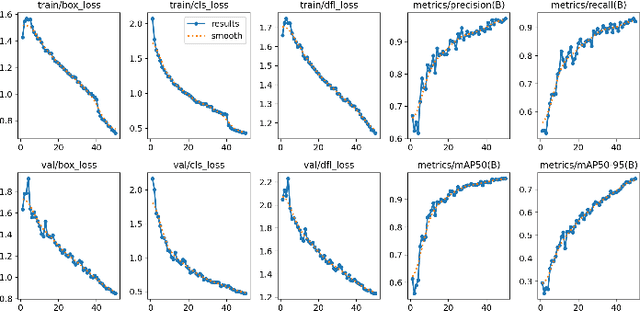
This study presents a novel classroom surveillance system that integrates multiple modalities, including drowsiness, tracking of mobile phone usage, and face recognition,to assess student attentiveness with enhanced precision.The system leverages the YOLOv8 model to detect both mobile phone and sleep usage,(Ghatge et al., 2024) while facial recognition is achieved through LResNet Occ FC body tracking using YOLO and MTCNN.(Durai et al., 2024) These models work in synergy to provide comprehensive, real-time monitoring, offering insights into student engagement and behavior.(S et al., 2023) The framework is trained on specialized datasets, such as the RMFD dataset for face recognition and a Roboflow dataset for mobile phone detection. The extensive evaluation of the system shows promising results. Sleep detection achieves 97. 42% mAP@50, face recognition achieves 86. 45% validation accuracy and mobile phone detection reach 85. 89% mAP@50. The system is implemented within a core PHP web application and utilizes ESP32-CAM hardware for seamless data capture.(Neto et al., 2024) This integrated approach not only enhances classroom monitoring, but also ensures automatic attendance recording via face recognition as students remain seated in the classroom, offering scalability for diverse educational environments.(Banada,2025)
Unmasking Deep Fakes: Leveraging Deep Learning for Video Authenticity Detection
May 10, 2025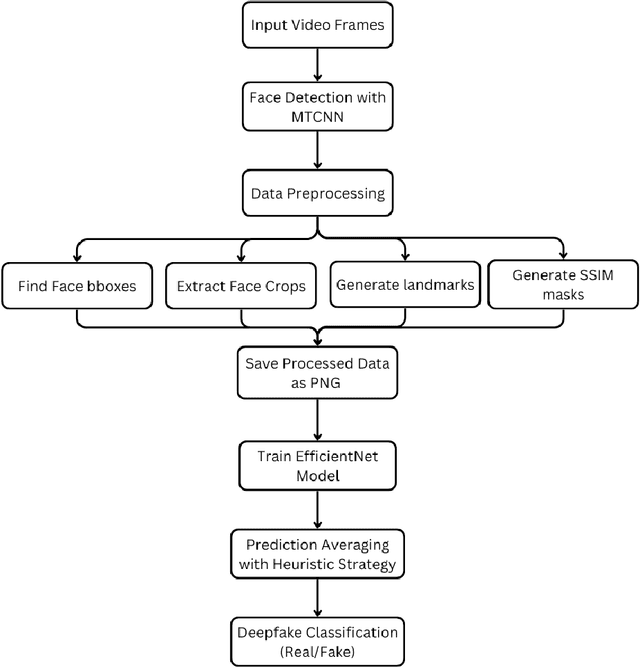

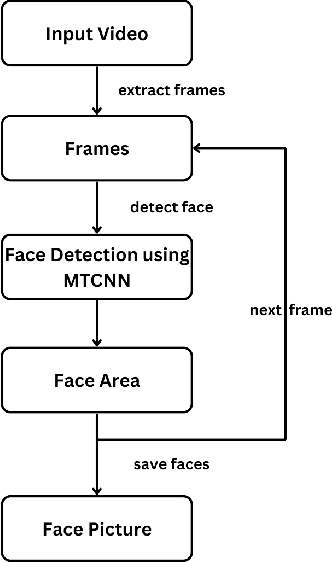

Deepfake videos, produced through advanced artificial intelligence methods now a days, pose a new challenge to the truthfulness of the digital media. As Deepfake becomes more convincing day by day, detecting them requires advanced methods capable of identifying subtle inconsistencies. The primary motivation of this paper is to recognize deepfake videos using deep learning techniques, specifically by using convolutional neural networks. Deep learning excels in pattern recognition, hence, makes it an ideal approach for detecting the intricate manipulations in deepfakes. In this paper, we consider using MTCNN as a face detector and EfficientNet-B5 as encoder model to predict if a video is deepfake or not. We utilize training and evaluation dataset from Kaggle DFDC. The results shows that our deepfake detection model acquired 42.78% log loss, 93.80% AUC and 86.82% F1 score on kaggle's DFDC dataset.
Global explainability of a deep abstaining classifier
Apr 01, 2025



We present a global explainability method to characterize sources of errors in the histology prediction task of our real-world multitask convolutional neural network (MTCNN)-based deep abstaining classifier (DAC), for automated annotation of cancer pathology reports from NCI-SEER registries. Our classifier was trained and evaluated on 1.04 million hand-annotated samples and makes simultaneous predictions of cancer site, subsite, histology, laterality, and behavior for each report. The DAC framework enables the model to abstain on ambiguous reports and/or confusing classes to achieve a target accuracy on the retained (non-abstained) samples, but at the cost of decreased coverage. Requiring 97% accuracy on the histology task caused our model to retain only 22% of all samples, mostly the less ambiguous and common classes. Local explainability with the GradInp technique provided a computationally efficient way of obtaining contextual reasoning for thousands of individual predictions. Our method, involving dimensionality reduction of approximately 13000 aggregated local explanations, enabled global identification of sources of errors as hierarchical complexity among classes, label noise, insufficient information, and conflicting evidence. This suggests several strategies such as exclusion criteria, focused annotation, and reduced penalties for errors involving hierarchically related classes to iteratively improve our DAC in this complex real-world implementation.
Impact of Face Alignment on Face Image Quality
Dec 16, 2024Face alignment is a crucial step in preparing face images for feature extraction in facial analysis tasks. For applications such as face recognition, facial expression recognition, and facial attribute classification, alignment is widely utilized during both training and inference to standardize the positions of key landmarks in the face. It is well known that the application and method of face alignment significantly affect the performance of facial analysis models. However, the impact of alignment on face image quality has not been thoroughly investigated. Current FIQA studies often assume alignment as a prerequisite but do not explicitly evaluate how alignment affects quality metrics, especially with the advent of modern deep learning-based detectors that integrate detection and landmark localization. To address this need, our study examines the impact of face alignment on face image quality scores. We conducted experiments on the LFW, IJB-B, and SCFace datasets, employing MTCNN and RetinaFace models for face detection and alignment. To evaluate face image quality, we utilized several assessment methods, including SER-FIQ, FaceQAN, DifFIQA, and SDD-FIQA. Our analysis included examining quality score distributions for the LFW and IJB-B datasets and analyzing average quality scores at varying distances in the SCFace dataset. Our findings reveal that face image quality assessment methods are sensitive to alignment. Moreover, this sensitivity increases under challenging real-life conditions, highlighting the importance of evaluating alignment's role in quality assessment.
GANmut: Generating and Modifying Facial Expressions
Jun 16, 2024



In the realm of emotion synthesis, the ability to create authentic and nuanced facial expressions continues to gain importance. The GANmut study discusses a recently introduced advanced GAN framework that, instead of relying on predefined labels, learns a dynamic and interpretable emotion space. This methodology maps each discrete emotion as vectors starting from a neutral state, their magnitude reflecting the emotion's intensity. The current project aims to extend the study of this framework by benchmarking across various datasets, image resolutions, and facial detection methodologies. This will involve conducting a series of experiments using two emotional datasets: Aff-Wild2 and AffNet. Aff-Wild2 contains videos captured in uncontrolled environments, which include diverse camera angles, head positions, and lighting conditions, providing a real-world challenge. AffNet offers images with labelled emotions, improving the diversity of emotional expressions available for training. The first two experiments will focus on training GANmut using the Aff-Wild2 dataset, processed with either RetinaFace or MTCNN, both of which are high-performance deep learning face detectors. This setup will help determine how well GANmut can learn to synthesise emotions under challenging conditions and assess the comparative effectiveness of these face detection technologies. The subsequent two experiments will merge the Aff-Wild2 and AffNet datasets, combining the real world variability of Aff-Wild2 with the diverse emotional labels of AffNet. The same face detectors, RetinaFace and MTCNN, will be employed to evaluate whether the enhanced diversity of the combined datasets improves GANmut's performance and to compare the impact of each face detection method in this hybrid setup.
Region of Interest Loss for Anonymizing Learned Image Compression
Jun 09, 2024



The use of AI in public spaces continually raises concerns about privacy and the protection of sensitive data. An example is the deployment of detection and recognition methods on humans, where images are provided by surveillance cameras. This results in the acquisition of great amounts of sensitive data, since the capture and transmission of images taken by such cameras happens unaltered, for them to be received by a server on the network. However, many applications do not explicitly require the identity of a given person in a scene; An anonymized representation containing information of the person's position while preserving the context of them in the scene suffices. We show how using a customized loss function on region of interests (ROI) can achieve sufficient anonymization such that human faces become unrecognizable while persons are kept detectable, by training an end-to-end optimized autoencoder for learned image compression that utilizes the flexibility of the learned analysis and reconstruction transforms for the task of mutating parts of the compression result. This approach enables compression and anonymization in one step on the capture device, instead of transmitting sensitive, nonanonymized data over the network. Additionally, we evaluate how this anonymization impacts the average precision of pre-trained foundation models on detecting faces (MTCNN) and humans (YOLOv8) in comparison to non-ANN based methods, while considering compression rate and latency.
Imperceptible Physical Attack against Face Recognition Systems via LED Illumination Modulation
Aug 07, 2023



Although face recognition starts to play an important role in our daily life, we need to pay attention that data-driven face recognition vision systems are vulnerable to adversarial attacks. However, the current two categories of adversarial attacks, namely digital attacks and physical attacks both have drawbacks, with the former ones impractical and the latter one conspicuous, high-computational and inexecutable. To address the issues, we propose a practical, executable, inconspicuous and low computational adversarial attack based on LED illumination modulation. To fool the systems, the proposed attack generates imperceptible luminance changes to human eyes through fast intensity modulation of scene LED illumination and uses the rolling shutter effect of CMOS image sensors in face recognition systems to implant luminance information perturbation to the captured face images. In summary,we present a denial-of-service (DoS) attack for face detection and a dodging attack for face verification. We also evaluate their effectiveness against well-known face detection models, Dlib, MTCNN and RetinaFace , and face verification models, Dlib, FaceNet,and ArcFace.The extensive experiments show that the success rates of DoS attacks against face detection models reach 97.67%, 100%, and 100%, respectively, and the success rates of dodging attacks against all face verification models reach 100%.
GesSure -- A Robust Face-Authentication enabled Dynamic Gesture Recognition GUI Application
Jul 22, 2022
Using physical interactive devices like mouse and keyboards hinders naturalistic human-machine interaction and increases the probability of surface contact during a pandemic. Existing gesture-recognition systems do not possess user authentication, making them unreliable. Static gestures in current gesture-recognition technology introduce long adaptation periods and reduce user compatibility. Our technology places a strong emphasis on user recognition and safety. We use meaningful and relevant gestures for task operation, resulting in a better user experience. This paper aims to design a robust, face-verification-enabled gesture recognition system that utilizes a graphical user interface and primarily focuses on security through user recognition and authorization. The face model uses MTCNN and FaceNet to verify the user, and our LSTM-CNN architecture for gesture recognition, achieving an accuracy of 95% with five classes of gestures. The prototype developed through our research has successfully executed context-dependent tasks like save, print, control video-player operations and exit, and context-free operating system tasks like sleep, shut-down, and unlock intuitively. Our application and dataset are available as open source.
Convolutional Neural Network Based Partial Face Detection
Jun 29, 2022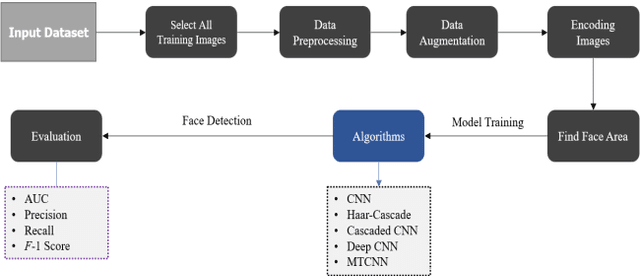

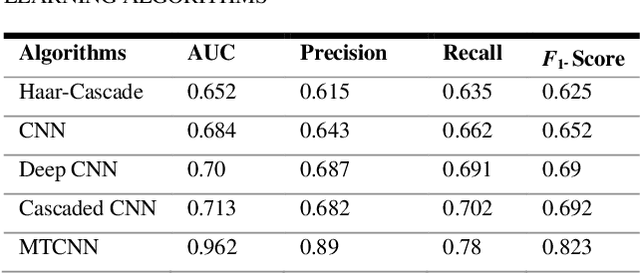

Due to the massive explanation of artificial intelligence, machine learning technology is being used in various areas of our day-to-day life. In the world, there are a lot of scenarios where a simple crime can be prevented before it may even happen or find the person responsible for it. A face is one distinctive feature that we have and can differentiate easily among many other species. But not just different species, it also plays a significant role in determining someone from the same species as us, humans. Regarding this critical feature, a single problem occurs most often nowadays. When the camera is pointed, it cannot detect a person's face, and it becomes a poor image. On the other hand, where there was a robbery and a security camera installed, the robber's identity is almost indistinguishable due to the low-quality camera. But just making an excellent algorithm to work and detecting a face reduces the cost of hardware, and it doesn't cost that much to focus on that area. Facial recognition, widget control, and such can be done by detecting the face correctly. This study aims to create and enhance a machine learning model that correctly recognizes faces. Total 627 Data have been collected from different Bangladeshi people's faces on four angels. In this work, CNN, Harr Cascade, Cascaded CNN, Deep CNN & MTCNN are these five machine learning approaches implemented to get the best accuracy of our dataset. After creating and running the model, Multi-Task Convolutional Neural Network (MTCNN) achieved 96.2% best model accuracy with training data rather than other machine learning models.
Face Detection on Mobile: Five Implementations and Analysis
May 12, 2022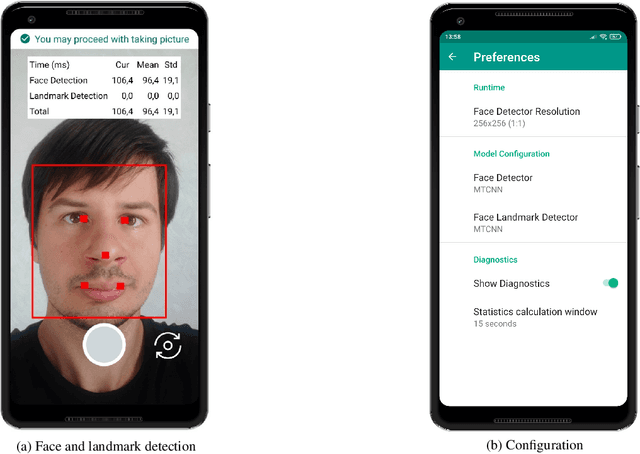



In many practical cases face detection on smartphones or other highly portable devices is a necessity. Applications include mobile face access control systems, driver status tracking, emotion recognition, etc. Mobile devices have limited processing power and should have long-enough battery life even with face detection application running. Thus, striking the right balance between algorithm quality and complexity is crucial. In this work we adapt 5 algorithms to mobile. These algorithms are based on handcrafted or neural-network-based features and include: Viola-Jones (Haar cascade), LBP, HOG, MTCNN, BlazeFace. We analyze inference time of these algorithms on different devices with different input image resolutions. We provide guidance, which algorithms are the best fit for mobile face access control systems and potentially other mobile applications. Interestingly, we note that cascaded algorithms perform faster on scenes without faces, while BlazeFace is slower on empty scenes. Exploiting this behavior might be useful in practice.