 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Encoder Reranking
Papers and Code
RAGTurk: Best Practices for Retrieval Augmented Generation in Turkish
Feb 03, 2026Retrieval-Augmented Generation (RAG) enhances LLM factuality, yet design guidance remains English-centric, limiting insights for morphologically rich languages like Turkish. We address this by constructing a comprehensive Turkish RAG dataset derived from Turkish Wikipedia and CulturaX, comprising question-answer pairs and relevant passage chunks. We benchmark seven stages of the RAG pipeline, from query transformation and reranking to answer refinement, without task-specific fine-tuning. Our results show that complex methods like HyDE maximize accuracy (85%) that is considerably higher than the baseline (78.70%). Also a Pareto-optimal configuration using Cross-encoder Reranking and Context Augmentation achieves comparable performance (84.60%) with much lower cost. We further demonstrate that over-stacking generative modules can degrade performance by distorting morphological cues, whereas simple query clarification with robust reranking offers an effective solution.
RegGuard: AI-Powered Retrieval-Enhanced Assistant for Pharmaceutical Regulatory Compliance
Jan 25, 2026The increasing frequency and complexity of regulatory updates present a significant burden for multinational pharmaceutical companies. Compliance teams must interpret evolving rules across jurisdictions, formats, and agencies, often manually, at high cost and risk of error. We introduce RegGuard, an industrial-scale AI assistant designed to automate the interpretation of heterogeneous regulatory texts and align them with internal corporate policies. The system ingests heterogeneous document sources through a secure pipeline and enhances retrieval and generation quality with two novel components: HiSACC (Hierarchical Semantic Aggregation for Contextual Chunking) semantically segments long documents into coherent units while maintaining consistency across non-contiguous sections. ReLACE (Regulatory Listwise Adaptive Cross-Encoder for Reranking), a domain-adapted cross-encoder built on an open-source model, jointly models user queries and retrieved candidates to improve ranking relevance. Evaluations in enterprise settings demonstrate that RegGuard improves answer quality specifically in terms of relevance, groundedness, and contextual focus, while significantly mitigating hallucination risk. The system architecture is built for auditability and traceability, featuring provenance tracking, access control, and incremental indexing, making it highly responsive to evolving document sources and relevant for any domain with stringent compliance demands.
Generative Recall, Dense Reranking: Learning Multi-View Semantic IDs for Efficient Text-to-Video Retrieval
Jan 29, 2026Text-to-Video Retrieval (TVR) is essential in video platforms. Dense retrieval with dual-modality encoders leads in accuracy, but its computation and storage scale poorly with corpus size. Thus, real-time large-scale applications adopt two-stage retrieval, where a fast recall model gathers a small candidate pool, which is reranked by an advanced dense retriever. Due to hugely reduced candidates, the reranking model can use any off-the-shelf dense retriever without hurting efficiency, meaning the recall model bounds two-stage TVR performance. Recently, generative retrieval (GR) replaces dense video embeddings with discrete semantic IDs and retrieves by decoding text queries into ID tokens. GR offers near-constant inference and storage complexity, and its semantic IDs capture high-level video features via quantization, making it ideal for quickly eliminating irrelevant candidates during recall. However, as a recall model in two-stage TVR, GR suffers from (i) semantic ambiguity, where each video satisfies diverse queries but is forced into one semantic ID; and (ii) cross-modal misalignment, as semantic IDs are solely derived from visual features without text supervision. We propose Generative Recall and Dense Reranking (GRDR), designing a novel GR method to uplift recalled candidate quality. GRDR assigns multiple semantic IDs to each video using a query-guided multi-view tokenizer exposing diverse semantic access paths, and jointly trains the tokenizer and generative retriever via a shared codebook to cast semantic IDs as the semantic bridge between texts and videos. At inference, trie-constrained decoding generates a compact candidate set reranked by a dense model for fine-grained matching. Experiments on TVR benchmarks show GRDR matches strong dense retrievers in accuracy while reducing index storage by an order of magnitude and accelerating up to 300$\times$ in full-corpus retrieval.
Taxonomy of the Retrieval System Framework: Pitfalls and Paradigms
Jan 27, 2026Designing an embedding retrieval system requires navigating a complex design space of conflicting trade-offs between efficiency and effectiveness. This work structures these decisions as a vertical traversal of the system design stack. We begin with the Representation Layer by examining how loss functions and architectures, specifically Bi-encoders and Cross-encoders, define semantic relevance and geometric projection. Next, we analyze the Granularity Layer and evaluate how segmentation strategies like Atomic and Hierarchical chunking mitigate information bottlenecks in long-context documents. Moving to the Orchestration Layer, we discuss methods that transcend the single-vector paradigm, including hierarchical retrieval, agentic decomposition, and multi-stage reranking pipelines to resolve capacity limitations. Finally, we address the Robustness Layer by identifying architectural mitigations for domain generalization failures, lexical blind spots, and the silent degradation of retrieval quality due to temporal drift. By categorizing these limitations and design choices, we provide a comprehensive framework for practitioners to optimize the efficiency-effectiveness frontier in modern neural search systems.
NewsRECON: News article REtrieval for image CONtextualization
Jan 20, 2026Identifying when and where a news image was taken is crucial for journalists and forensic experts to produce credible stories and debunk misinformation. While many existing methods rely on reverse image search (RIS) engines, these tools often fail to return results, thereby limiting their practical applicability. In this work, we address the challenging scenario where RIS evidence is unavailable. We introduce NewsRECON, a method that links images to relevant news articles to infer their date and location from article metadata. NewsRECON leverages a corpus of over 90,000 articles and integrates: (1) a bi-encoder for retrieving event-relevant articles; (2) two cross-encoders for reranking articles by location and event consistency. Experiments on the TARA and 5Pils-OOC show that NewsRECON outperforms prior work and can be combined with a multimodal large language model to achieve new SOTA results in the absence of RIS evidence. We make our code available.
Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking
Jan 08, 2026In this report, we introduce the Qwen3-VL-Embedding and Qwen3-VL-Reranker model series, the latest extensions of the Qwen family built on the Qwen3-VL foundation model. Together, they provide an end-to-end pipeline for high-precision multimodal search by mapping diverse modalities, including text, images, document images, and video, into a unified representation space. The Qwen3-VL-Embedding model employs a multi-stage training paradigm, progressing from large-scale contrastive pre-training to reranking model distillation, to generate semantically rich high-dimensional vectors. It supports Matryoshka Representation Learning, enabling flexible embedding dimensions, and handles inputs up to 32k tokens. Complementing this, Qwen3-VL-Reranker performs fine-grained relevance estimation for query-document pairs using a cross-encoder architecture with cross-attention mechanisms. Both model series inherit the multilingual capabilities of Qwen3-VL, supporting more than 30 languages, and are released in $\textbf{2B}$ and $\textbf{8B}$ parameter sizes to accommodate diverse deployment requirements. Empirical evaluations demonstrate that the Qwen3-VL-Embedding series achieves state-of-the-art results across diverse multimodal embedding evaluation benchmarks. Specifically, Qwen3-VL-Embedding-8B attains an overall score of $\textbf{77.8}$ on MMEB-V2, ranking first among all models (as of January 8, 2025). This report presents the architecture, training methodology, and practical capabilities of the series, demonstrating their effectiveness on various multimodal retrieval tasks, including image-text retrieval, visual question answering, and video-text matching.
ReGAIN: Retrieval-Grounded AI Framework for Network Traffic Analysis
Dec 23, 2025Modern networks generate vast, heterogeneous traffic that must be continuously analyzed for security and performance. Traditional network traffic analysis systems, whether rule-based or machine learning-driven, often suffer from high false positives and lack interpretability, limiting analyst trust. In this paper, we present ReGAIN, a multi-stage framework that combines traffic summarization, retrieval-augmented generation (RAG), and Large Language Model (LLM) reasoning for transparent and accurate network traffic analysis. ReGAIN creates natural-language summaries from network traffic, embeds them into a multi-collection vector database, and utilizes a hierarchical retrieval pipeline to ground LLM responses with evidence citations. The pipeline features metadata-based filtering, MMR sampling, a two-stage cross-encoder reranking mechanism, and an abstention mechanism to reduce hallucinations and ensure grounded reasoning. Evaluated on ICMP ping flood and TCP SYN flood traces from the real-world traffic dataset, it demonstrates robust performance, achieving accuracy between 95.95% and 98.82% across different attack types and evaluation benchmarks. These results are validated against two complementary sources: dataset ground truth and human expert assessments. ReGAIN also outperforms rule-based, classical ML, and deep learning baselines while providing unique explainability through trustworthy, verifiable responses.
VERAFI: Verified Agentic Financial Intelligence through Neurosymbolic Policy Generation
Dec 12, 2025Financial AI systems suffer from a critical blind spot: while Retrieval-Augmented Generation (RAG) excels at finding relevant documents, language models still generate calculation errors and regulatory violations during reasoning, even with perfect retrieval. This paper introduces VERAFI (Verified Agentic Financial Intelligence), an agentic framework with neurosymbolic policy generation for verified financial intelligence. VERAFI combines state-of-the-art dense retrieval and cross-encoder reranking with financial tool-enabled agents and automated reasoning policies covering GAAP compliance, SEC requirements, and mathematical validation. Our comprehensive evaluation on FinanceBench demonstrates remarkable improvements: while traditional dense retrieval with reranking achieves only 52.4\% factual correctness, VERAFI's integrated approach reaches 94.7\%, an 81\% relative improvement. The neurosymbolic policy layer alone contributes a 4.3 percentage point gain over pure agentic processing, specifically targeting persistent mathematical and logical errors. By integrating financial domain expertise directly into the reasoning process, VERAFI offers a practical pathway toward trustworthy financial AI that meets the stringent accuracy demands of regulatory compliance, investment decisions, and risk management.
The Evolution of Reranking Models in Information Retrieval: From Heuristic Methods to Large Language Models
Dec 18, 2025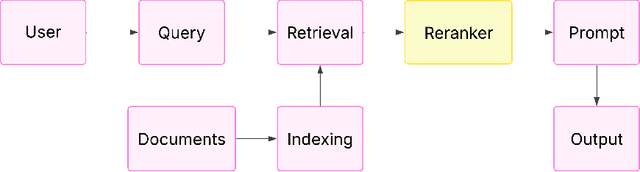
Reranking is a critical stage in contemporary information retrieval (IR) systems, improving the relevance of the user-presented final results by honing initial candidate sets. This paper is a thorough guide to examine the changing reranker landscape and offer a clear view of the advancements made in reranking methods. We present a comprehensive survey of reranking models employed in IR, particularly within modern Retrieval Augmented Generation (RAG) pipelines, where retrieved documents notably influence output quality. We embark on a chronological journey through the historical trajectory of reranking techniques, starting with foundational approaches, before exploring the wide range of sophisticated neural network architectures such as cross-encoders, sequence-generation models like T5, and Graph Neural Networks (GNNs) utilized for structural information. Recognizing the computational cost of advancing neural rerankers, we analyze techniques for enhancing efficiency, notably knowledge distillation for creating competitive, lighter alternatives. Furthermore, we map the emerging territory of integrating Large Language Models (LLMs) in reranking, examining novel prompting strategies and fine-tuning tactics. This survey seeks to elucidate the fundamental ideas, relative effectiveness, computational features, and real-world trade-offs of various reranking strategies. The survey provides a structured synthesis of the diverse reranking paradigms, highlighting their underlying principles and comparative strengths and weaknesses.
Practical RAG Evaluation: A Rarity-Aware Set-Based Metric and Cost-Latency-Quality Trade-offs
Nov 12, 2025This paper addresses the guessing game in building production RAG. Classical rank-centric IR metrics (nDCG/MAP/MRR) are a poor fit for RAG, where LLMs consume a set of passages rather than a browsed list; position discounts and prevalence-blind aggregation miss what matters: whether the prompt at cutoff K contains the decisive evidence. Second, there is no standardized, reproducible way to build and audit golden sets. Third, leaderboards exist but lack end-to-end, on-corpus benchmarking that reflects production trade-offs. Fourth, how state-of-the-art embedding models handle proper-name identity signals and conversational noise remains opaque. To address these, we contribute: (1) RA-nWG@K, a rarity-aware, per-query-normalized set score, and operational ceilings via the pool-restricted oracle ceiling (PROC) and the percentage of PROC (%PROC) to separate retrieval from ordering headroom within a Cost-Latency-Quality (CLQ) lens; (2) rag-gs (MIT), a lean golden-set pipeline with Plackett-Luce listwise refinement whose iterative updates outperform single-shot LLM ranking; (3) a comprehensive benchmark on a production RAG (scientific-papers corpus) spanning dense retrieval, hybrid dense+BM25, embedding models and dimensions, cross-encoder rerankers, ANN (HNSW), and quantization; and (4) targeted diagnostics that quantify proper-name identity signal and conversational-noise sensitivity via identity-destroying and formatting ablations. Together, these components provide practitioner Pareto guidance and auditable guardrails to support reproducible, budget/SLA-aware decisions.