 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Is Not a Sufficient Privacy Boundary: Governing OS-Integrated On-Device AI
Jun 08, 2026As AI systems move into operating systems, privacy no longer turns only on whether a model runs locally. A local assistant may assemble email, calendar entries, files, screenshots, notifications, and app intents; retain embeddings or summaries; invoke tools; emit telemetry; or route difficult requests to cloud infrastructure. Local inference reduces some exposure, but it answers only one question: where computation occurs. It does not answer who may assemble context, what derived state persists, which actions are authorized, or how updates change the system's authority. We develop an OS-centered privacy framework for on-device AI that treats privacy as an institutional accountability problem rather than a deployment attribute. The framework specifies a threat model, a six-part privacy risk taxonomy, privacy-by-architecture controls, and a four-level audit rubric. We demonstrate the rubric through a documentation-bounded comparison of Apple Intelligence/Foundation Models, Android AICore/Gemini Nano, and Microsoft Recall. Meaningful privacy in on-device AI depends on constrained information flow, bounded authority, visible user control, and auditable governance across the operating-system lifecycle.
Generative AI and Digital Ecosystem Resilience: A Proactive Lifecycle-Based Survey
May 28, 2026The proliferation of adversarial synthetic content, accelerated by Generative AI (GenAI) is rendering traditional reactive detection methods ineffective. This survey synthesizes emerging research to demonstrate a paradigm shift toward the proactive detection of emerging inauthentic narratives. In this survey, we adopt a unified, lifecycle-based taxonomy to combine socio-technical lifecycle models of adversarial campaigns with advanced computational methodologies for emerging inauthentic narrative detection. By structuring the analysis around the C5 Interaction Model (Context, Causes, Content, Cycle of Amplification, Consequences), we integrate different research streams from machine learning and social science. To differentiate spread patterns of synthetic amplification from authentic baseline traffic, this paper surveys state-of-the-art techniques for modeling the creation, seeding, and propagation of fresh narratives, including the analysis of Coordinated Inauthentic Behavior (CIB), epidemiological modeling, and Hawkes process. This survey also provides a systematic review of proactive detection methods for adversarial threats at different stages in the C5 interaction model, specifically, anomaly detection in high-dimensional embedding spaces, unsupervised coordination detection on multi-layer graphs, and agentic AI systems. Finally, this survey addresses challenges posed by GenAI, including the difficulty of tracking rapidly changing threats and multi-level distributional drift, and it outlines a future research agenda focused on detecting anomalous clusters and building anticipatory and resilient systems. This survey provides a comprehensive, lifecycle-based review of methods for the proactive detection of emerging synthetic threats for more resilient information ecosystems.
* 14 pages, 3 figures, 3 tables. Accepted for publication in IEEE Access (May 2026)
The Silent Vote: Improving Zero-Shot LLM Reliability by Aggregating Semantic Neighborhoods
May 10, 2026Large Language Models are increasingly used as zero-shot classifiers in complex reasoning tasks. However, standard constrained decoding suffers from a phenomenon we define as Renormalization Bias. When a model is restricted to a small set of target labels, the standard softmax operation discards the probability mass assigned to semantic synonyms in the original distribution. This loss of information, which we call the Silent Vote, results in artificial overconfidence and poor calibration. We propose Semantic Softmax, an inference-time layer that recovers this lost information by aggregating the scores of the semantic neighborhood surrounding each target label. We evaluate this approach on Qwen-3 and Phi-4-mini models using GoEmotions and Civil Comments datasets. Our results demonstrate consistent improvements across all evaluation metrics: Semantic Softmax substantially reduces Expected Calibration Error (ECE) and Brier Score, while simultaneously enhancing discriminative performance in terms of AUROC and Macro-F1. By accounting for linguistic nuances, our method provides a more calibrated and accurate alternative for zero-shot classification.
CROP: Token-Efficient Reasoning in Large Language Models via Regularized Prompt Optimization
Apr 08, 2026Large Language Models utilizing reasoning techniques improve task performance but incur significant latency and token costs due to verbose generation. Existing automatic prompt optimization(APO) frameworks target task accuracy exclusively at the expense of generating long reasoning traces. We propose Cost-Regularized Optimization of Prompts (CROP), an APO method that introduces regularization on response length by generating textual feedback in addition to standard accuracy feedback. This forces the optimization process to produce prompts that elicit concise responses containing only critical information and reasoning. We evaluate our approach on complex reasoning datasets, specifically GSM8K, LogiQA and BIG-Bench Hard. We achieved an 80.6\% reduction in token consumption while maintaining competitive accuracy, seeing only a nominal decline in performance. This presents a pragmatic solution for deploying token-efficient and cost-effective agentic AI systems in production pipelines.
Large Language Models in the Abuse Detection Pipeline
Mar 31, 2026Online abuse has grown increasingly complex, spanning toxic language, harassment, manipulation, and fraudulent behavior. Traditional machine-learning approaches dependent on static classifiers and labor-intensive labeling struggle to keep pace with evolving threat patterns and nuanced policy requirements. Large Language Models introduce new capabilities for contextual reasoning, policy interpretation, explanation generation, and cross-modal understanding, enabling them to support multiple stages of modern safety systems. This survey provides a lifecycle-oriented analysis of how LLMs are being integrated into the Abuse Detection Lifecycle (ADL), which we define across four stages: (I) Label \& Feature Generation, (II) Detection, (III) Review \& Appeals, and (IV) Auditing \& Governance. For each stage, we synthesize emerging research and industry practices, highlight architectural considerations for production deployment, and examine the strengths and limitations of LLM-driven approaches. We conclude by outlining key challenges including latency, cost-efficiency, determinism, adversarial robustness, and fairness and discuss future research directions needed to operationalize LLMs as reliable, accountable components of large-scale abuse-detection and governance systems.
Prompt-Level Distillation: A Non-Parametric Alternative to Model Fine-Tuning for Efficient Reasoning
Feb 24, 2026Advanced reasoning typically requires Chain-of-Thought prompting, which is accurate but incurs prohibitive latency and substantial test-time inference costs. The standard alternative, fine-tuning smaller models, often sacrifices interpretability while introducing significant resource and operational overhead. To address these limitations, we introduce Prompt-Level Distillation (PLD). We extract explicit reasoning patterns from a Teacher model and organize them into a structured list of expressive instructions for the Student model's System Prompt. Evaluated on the StereoSet and Contract-NLI datasets using Gemma-3 4B, PLD improved Macro F1 scores from 57\% to 90.0\% and 67\% to 83\% respectively, enabling this compact model to match frontier performance with negligible latency overhead. These expressive instructions render the decision-making process transparent, allowing for full human verification of logic, making this approach ideal for regulated industries such as law, finance, and content moderation, as well as high-volume use cases and edge devices.
Long-Tail Knowledge in Large Language Models: Taxonomy, Mechanisms, Interventions and Implications
Feb 18, 2026Large language models (LLMs) are trained on web-scale corpora that exhibit steep power-law distributions, in which the distribution of knowledge is highly long-tailed, with most appearing infrequently. While scaling has improved average-case performance, persistent failures on low-frequency, domain-specific, cultural, and temporal knowledge remain poorly characterized. This paper develops a structured taxonomy and analysis of long-Tail Knowledge in large language models, synthesizing prior work across technical and sociotechnical perspectives. We introduce a structured analytical framework that synthesizes prior work across four complementary axes: how long-Tail Knowledge is defined, the mechanisms by which it is lost or distorted during training and inference, the technical interventions proposed to mitigate these failures, and the implications of these failures for fairness, accountability, transparency, and user trust. We further examine how existing evaluation practices obscure tail behavior and complicate accountability for rare but consequential failures. The paper concludes by identifying open challenges related to privacy, sustainability, and governance that constrain long-Tail Knowledge representation. Taken together, this paper provides a unifying conceptual framework for understanding how long-Tail Knowledge is defined, lost, evaluated, and manifested in deployed language model systems.
Taxonomy of the Retrieval System Framework: Pitfalls and Paradigms
Jan 27, 2026Designing an embedding retrieval system requires navigating a complex design space of conflicting trade-offs between efficiency and effectiveness. This work structures these decisions as a vertical traversal of the system design stack. We begin with the Representation Layer by examining how loss functions and architectures, specifically Bi-encoders and Cross-encoders, define semantic relevance and geometric projection. Next, we analyze the Granularity Layer and evaluate how segmentation strategies like Atomic and Hierarchical chunking mitigate information bottlenecks in long-context documents. Moving to the Orchestration Layer, we discuss methods that transcend the single-vector paradigm, including hierarchical retrieval, agentic decomposition, and multi-stage reranking pipelines to resolve capacity limitations. Finally, we address the Robustness Layer by identifying architectural mitigations for domain generalization failures, lexical blind spots, and the silent degradation of retrieval quality due to temporal drift. By categorizing these limitations and design choices, we provide a comprehensive framework for practitioners to optimize the efficiency-effectiveness frontier in modern neural search systems.
ScamAgents: How AI Agents Can Simulate Human-Level Scam Calls
Aug 08, 2025Large Language Models (LLMs) have demonstrated impressive fluency and reasoning capabilities, but their potential for misuse has raised growing concern. In this paper, we present ScamAgent, an autonomous multi-turn agent built on top of LLMs, capable of generating highly realistic scam call scripts that simulate real-world fraud scenarios. Unlike prior work focused on single-shot prompt misuse, ScamAgent maintains dialogue memory, adapts dynamically to simulated user responses, and employs deceptive persuasion strategies across conversational turns. We show that current LLM safety guardrails, including refusal mechanisms and content filters, are ineffective against such agent-based threats. Even models with strong prompt-level safeguards can be bypassed when prompts are decomposed, disguised, or delivered incrementally within an agent framework. We further demonstrate the transformation of scam scripts into lifelike voice calls using modern text-to-speech systems, completing a fully automated scam pipeline. Our findings highlight an urgent need for multi-turn safety auditing, agent-level control frameworks, and new methods to detect and disrupt conversational deception powered by generative AI.
Automated Segmentation of Vertebrae on Lateral Chest Radiography Using Deep Learning
Jan 05, 2020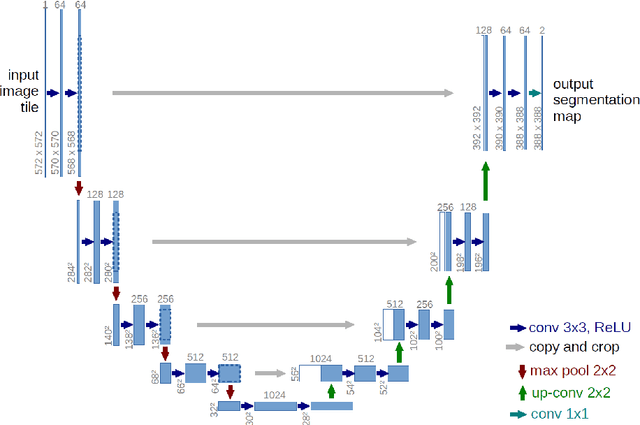
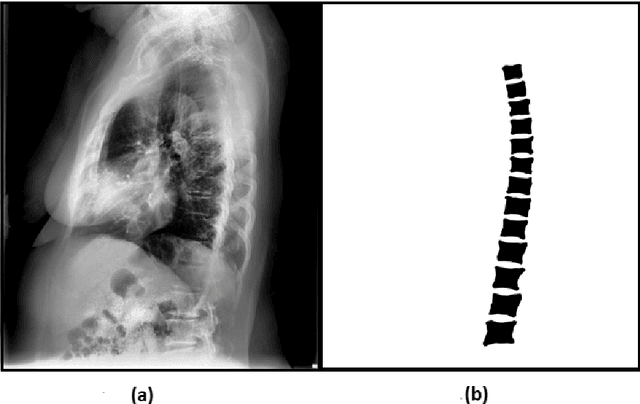
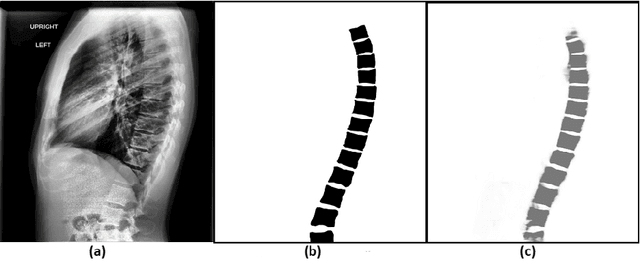
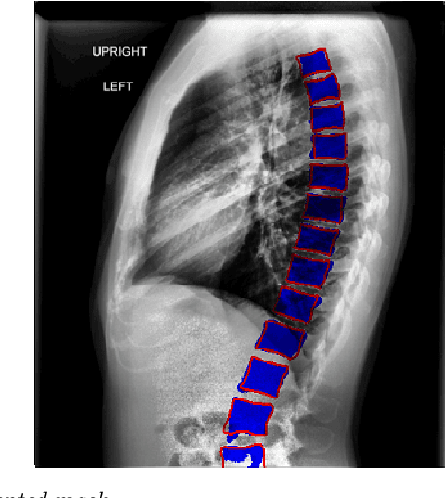
The purpose of this study is to develop an automated algorithm for thoracic vertebral segmentation on chest radiography using deep learning. 124 de-identified lateral chest radiographs on unique patients were obtained. Segmentations of visible vertebrae were manually performed by a medical student and verified by a board-certified radiologist. 74 images were used for training, 10 for validation, and 40 were held out for testing. A U-Net deep convolutional neural network was employed for segmentation, using the sum of dice coefficient and binary cross-entropy as the loss function. On the test set, the algorithm demonstrated an average dice coefficient value of 90.5 and an average intersection-over-union (IoU) of 81.75. Deep learning demonstrates promise in the segmentation of vertebrae on lateral chest radiography.