 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFregeLogic at SemEval 2026 Task 11: A Hybrid Neuro-Symbolic Architecture for Content-Robust Syllogistic Validity Prediction
Apr 20, 2026We present FregeLogic, a hybrid neuro-symbolic system for SemEval-2026 Task 11 (Subtask 1), which addresses syllogistic validity prediction while reducing content effects on predictions. Our approach combines an ensemble of five LLM classifiers, spanning three open-weights models (Llama 4 Maverick, Llama 4 Scout, and Qwen3-32B) paired with varied prompting strategies, with a Z3 SMT solver that serves as a formal logic tiebreaker. The central hypothesis is that LLM disagreement within the ensemble signals likely content-biased errors, where real-world believability interferes with logical judgment. By deferring to Z3's structurally-grounded formal verification on these disputed cases, our system achieves 94.3% accuracy with a content effect of 2.85 and a combined score of 41.88 in nested 5-fold cross-validation on the dataset (N=960). This represents a 2.76-point improvement in combined score over the pure ensemble (39.12), with a 0.9% accuracy gain, driven by a 16% reduction in content effect (3.39 to 2.85). Adopting structured-output API calls for Z3 extraction reduced failure rates from ~22% to near zero, and an Aristotelian encoding with existence axioms was validated against task annotations. Our results suggest that targeted neuro-symbolic integration, applying formal methods precisely where ensemble consensus is lowest, can improve the combined accuracy-plus-content-effect metric used by this task.
VERAFI: Verified Agentic Financial Intelligence through Neurosymbolic Policy Generation
Dec 12, 2025Financial AI systems suffer from a critical blind spot: while Retrieval-Augmented Generation (RAG) excels at finding relevant documents, language models still generate calculation errors and regulatory violations during reasoning, even with perfect retrieval. This paper introduces VERAFI (Verified Agentic Financial Intelligence), an agentic framework with neurosymbolic policy generation for verified financial intelligence. VERAFI combines state-of-the-art dense retrieval and cross-encoder reranking with financial tool-enabled agents and automated reasoning policies covering GAAP compliance, SEC requirements, and mathematical validation. Our comprehensive evaluation on FinanceBench demonstrates remarkable improvements: while traditional dense retrieval with reranking achieves only 52.4\% factual correctness, VERAFI's integrated approach reaches 94.7\%, an 81\% relative improvement. The neurosymbolic policy layer alone contributes a 4.3 percentage point gain over pure agentic processing, specifically targeting persistent mathematical and logical errors. By integrating financial domain expertise directly into the reasoning process, VERAFI offers a practical pathway toward trustworthy financial AI that meets the stringent accuracy demands of regulatory compliance, investment decisions, and risk management.
Temporal Analysis of Climate Policy Discourse: Insights from Dynamic Embedded Topic Modeling
Jul 08, 2025Understanding how policy language evolves over time is critical for assessing global responses to complex challenges such as climate change. Temporal analysis helps stakeholders, including policymakers and researchers, to evaluate past priorities, identify emerging themes, design governance strategies, and develop mitigation measures. Traditional approaches, such as manual thematic coding, are time-consuming and limited in capturing the complex, interconnected nature of global policy discourse. With the increasing relevance of unsupervised machine learning, these limitations can be addressed, particularly under high-volume, complex, and high-dimensional data conditions. In this work, we explore a novel approach that applies the dynamic embedded topic model (DETM) to analyze the evolution of global climate policy discourse. A probabilistic model designed to capture the temporal dynamics of topics over time. We collected a corpus of United Nations Framework Convention on Climate Change (UNFCCC) policy decisions from 1995 to 2023, excluding 2020 due to the postponement of COP26 as a result of the COVID-19 pandemic. The model reveals shifts from early emphases on greenhouse gases and international conventions to recent focuses on implementation, technical collaboration, capacity building, finance, and global agreements. Section 3 presents the modeling pipeline, including preprocessing, model training, and visualization of temporal word distributions. Our results show that DETM is a scalable and effective tool for analyzing the evolution of global policy discourse. Section 4 discusses the implications of these findings and we concluded with future directions and refinements to extend this approach to other policy domains.
AI-Driven Climate Policy Scenario Generation for Sub-Saharan Africa
May 24, 2025

Climate policy scenario generation and evaluation have traditionally relied on integrated assessment models (IAMs) and expert-driven qualitative analysis. These methods enable stakeholders, such as policymakers and researchers, to anticipate impacts, plan governance strategies, and develop mitigation measures. However, traditional methods are often time-intensive, reliant on simple extrapolations of past trends, and limited in capturing the complex and interconnected nature of energy and climate issues. With the advent of artificial intelligence (AI), particularly generative AI models trained on vast datasets, these limitations can be addressed, ensuring robustness even under limited data conditions. In this work, we explore the novel method that employs generative AI, specifically large language models (LLMs), to simulate climate policy scenarios for Sub-Saharan Africa. These scenarios focus on energy transition themes derived from the historical United Nations Climate Change Conference (COP) documents. By leveraging generative models, the project aims to create plausible and diverse policy scenarios that align with regional climate goals and energy challenges. Given limited access to human evaluators, automated techniques were employed for scenario evaluation. We generated policy scenarios using the llama3.2-3B model. Of the 34 generated responses, 30 (88%) passed expert validation, accurately reflecting the intended impacts provided in the corresponding prompts. We compared these validated responses against assessments from a human climate expert and two additional LLMs (gemma2-2B and mistral-7B). Our structured, embedding-based evaluation framework shows that generative AI effectively generate scenarios that are coherent, relevant, plausible, and diverse. This approach offers a transformative tool for climate policy planning in data-constrained regions.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021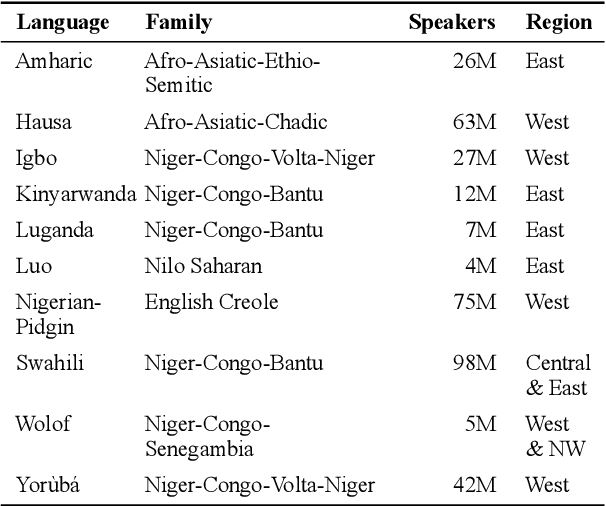

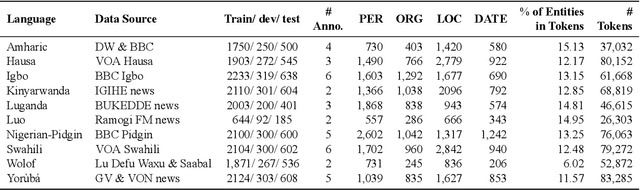
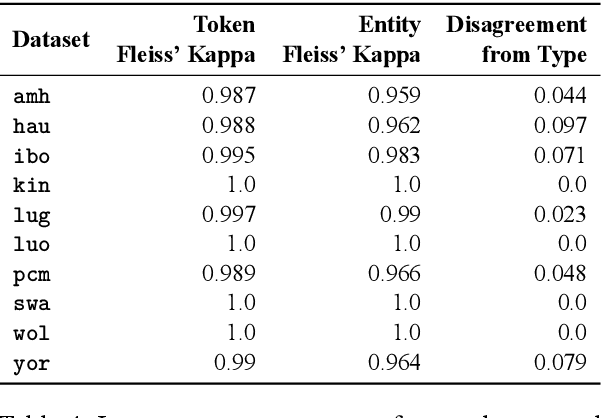
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.
Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages
Oct 05, 2020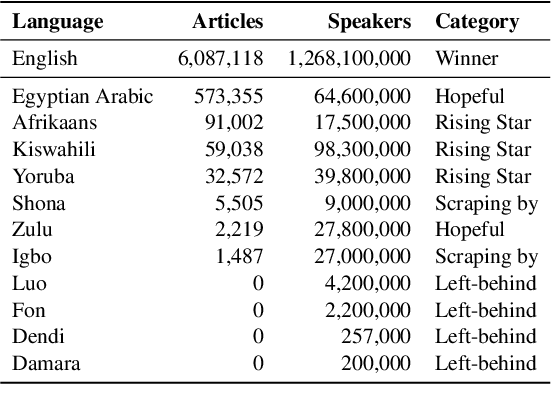
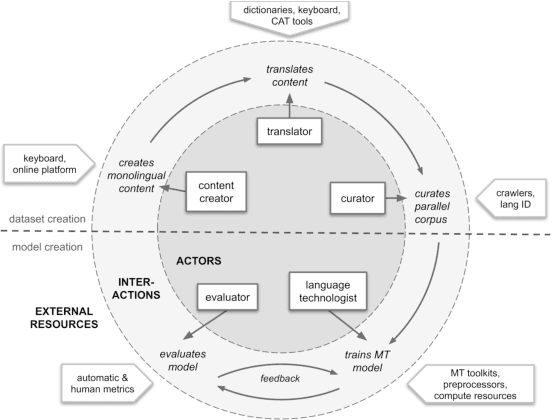
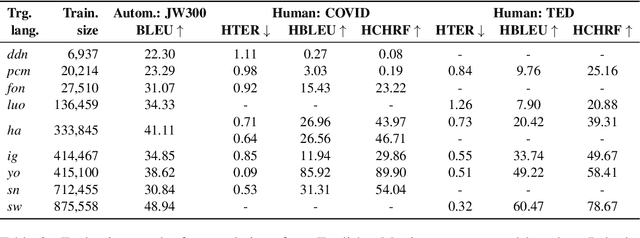
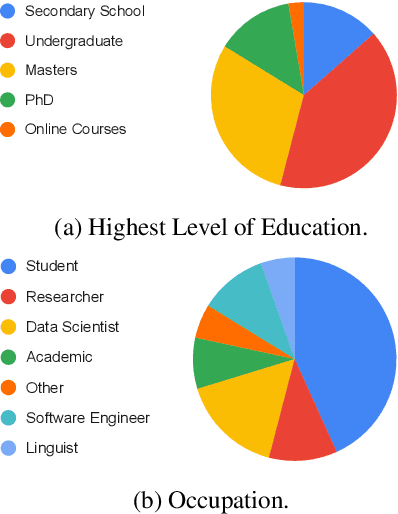
Research in NLP lacks geographic diversity, and the question of how NLP can be scaled to low-resourced languages has not yet been adequately solved. "Low-resourced"-ness is a complex problem going beyond data availability and reflects systemic problems in society. In this paper, we focus on the task of Machine Translation (MT), that plays a crucial role for information accessibility and communication worldwide. Despite immense improvements in MT over the past decade, MT is centered around a few high-resourced languages. As MT researchers cannot solve the problem of low-resourcedness alone, we propose participatory research as a means to involve all necessary agents required in the MT development process. We demonstrate the feasibility and scalability of participatory research with a case study on MT for African languages. Its implementation leads to a collection of novel translation datasets, MT benchmarks for over 30 languages, with human evaluations for a third of them, and enables participants without formal training to make a unique scientific contribution. Benchmarks, models, data, code, and evaluation results are released under https://github.com/masakhane-io/masakhane-mt.
HausaMT v1.0: Towards English-Hausa Neural Machine Translation
Jun 14, 2020
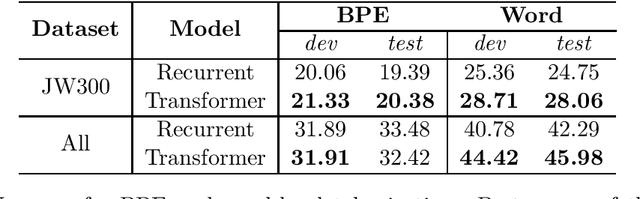

Neural Machine Translation (NMT) for low-resource languages suffers from low performance because of the lack of large amounts of parallel data and language diversity. To contribute to ameliorating this problem, we built a baseline model for English-Hausa machine translation, which is considered a task for low-resource language. The Hausa language is the second largest Afro-Asiatic language in the world after Arabic and it is the third largest language for trading across a larger swath of West Africa countries, after English and French. In this paper, we curated different datasets containing Hausa-English parallel corpus for our translation. We trained baseline models and evaluated the performance of our models using the Recurrent and Transformer encoder-decoder architecture with two tokenization approaches: standard word-level tokenization and Byte Pair Encoding (BPE) subword tokenization.
Predicting and Analyzing Law-Making in Kenya
Jun 09, 2020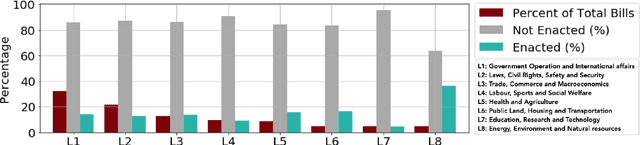

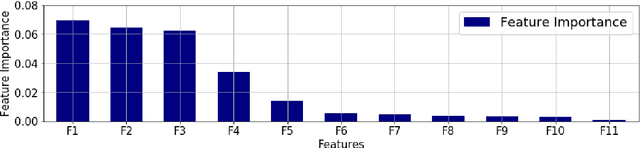
Modelling and analyzing parliamentary legislation, roll-call votes and order of proceedings in developed countries has received significant attention in recent years. In this paper, we focused on understanding the bills introduced in a developing democracy, the Kenyan bicameral parliament. We developed and trained machine learning models on a combination of features extracted from the bills to predict the outcome - if a bill will be enacted or not. We observed that the texts in a bill are not as relevant as the year and month the bill was introduced and the category the bill belongs to.
Masakhane -- Machine Translation For Africa
Mar 13, 2020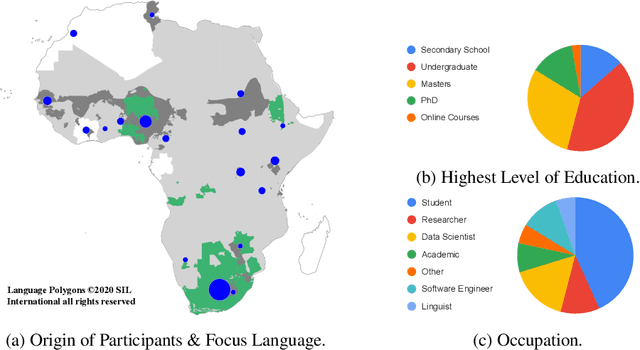
Africa has over 2000 languages. Despite this, African languages account for a small portion of available resources and publications in Natural Language Processing (NLP). This is due to multiple factors, including: a lack of focus from government and funding, discoverability, a lack of community, sheer language complexity, difficulty in reproducing papers and no benchmarks to compare techniques. To begin to address the identified problems, MASAKHANE, an open-source, continent-wide, distributed, online research effort for machine translation for African languages, was founded. In this paper, we discuss our methodology for building the community and spurring research from the African continent, as well as outline the success of the community in terms of addressing the identified problems affecting African NLP.
NASS-AI: Towards Digitization of Parliamentary Bills using Document Level Embedding and Bidirectional Long Short-Term Memory
Oct 02, 2019
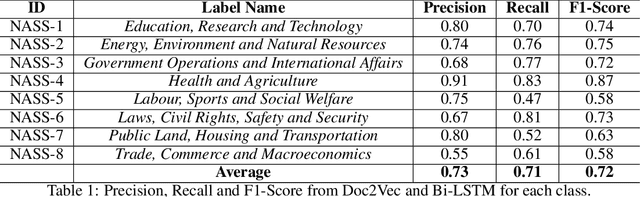
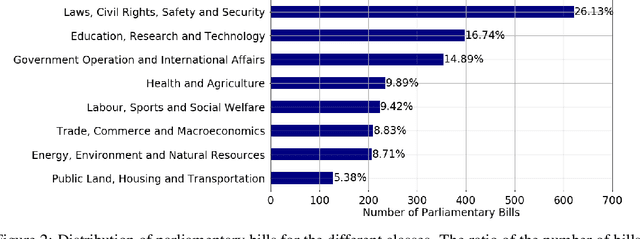
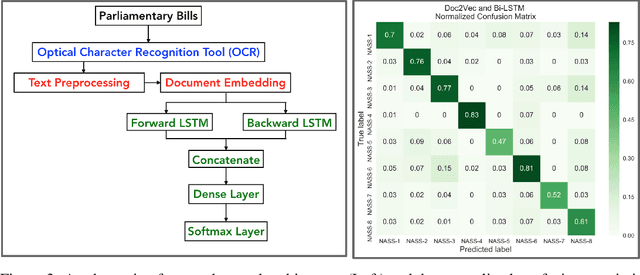
There has been several reports in the Nigerian and International media about the Senators and House of Representative Members of the Nigerian National Assembly (NASS) being the highest paid in the world. Despite this high-level of parliamentary compensation and a lack of oversight, most of the legislative duties like bills introduced and vote proceedings are shrouded in mystery without an open and annotated corpus. In this paper, we present results from ongoing research on the categorization of bills introduced in the Nigerian parliament since the fourth republic (1999 - 2018). For this task, we employed a multi-step approach which involves extracting text from scanned and embedded pdfs with low to medium quality using Optical Character Recognition (OCR) tools and labeling them into eight categories. We investigate the performance of document level embedding for feature representation of the extracted texts before using a Bidirectional Long Short-Term Memory (Bi-LSTM) for our classifier. The performance was further compared with other feature representation and machine learning techniques. We believe that these results are well-positioned to have a substantial impact on the quest to meet the basic open data charter principles.