 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNASS-AI: Towards Digitization of Parliamentary Bills using Document Level Embedding and Bidirectional Long Short-Term Memory
Paper and Code

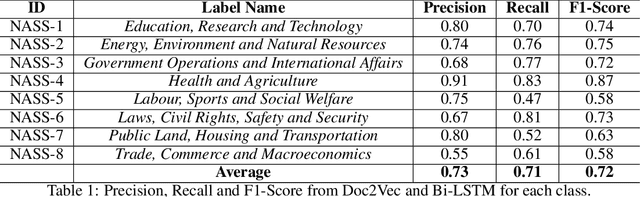
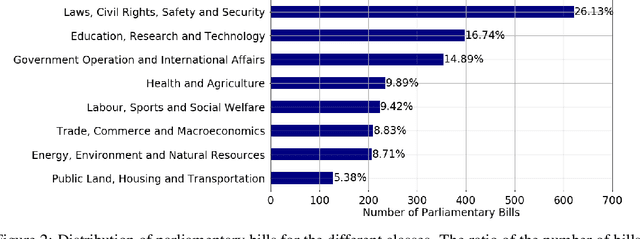
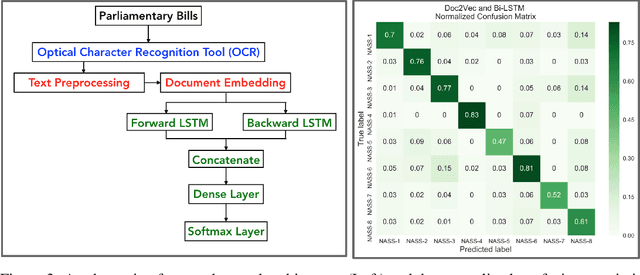
There has been several reports in the Nigerian and International media about the Senators and House of Representative Members of the Nigerian National Assembly (NASS) being the highest paid in the world. Despite this high-level of parliamentary compensation and a lack of oversight, most of the legislative duties like bills introduced and vote proceedings are shrouded in mystery without an open and annotated corpus. In this paper, we present results from ongoing research on the categorization of bills introduced in the Nigerian parliament since the fourth republic (1999 - 2018). For this task, we employed a multi-step approach which involves extracting text from scanned and embedded pdfs with low to medium quality using Optical Character Recognition (OCR) tools and labeling them into eight categories. We investigate the performance of document level embedding for feature representation of the extracted texts before using a Bidirectional Long Short-Term Memory (Bi-LSTM) for our classifier. The performance was further compared with other feature representation and machine learning techniques. We believe that these results are well-positioned to have a substantial impact on the quest to meet the basic open data charter principles.