 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHausaMT v1.0: Towards English-Hausa Neural Machine Translation
Paper and Code

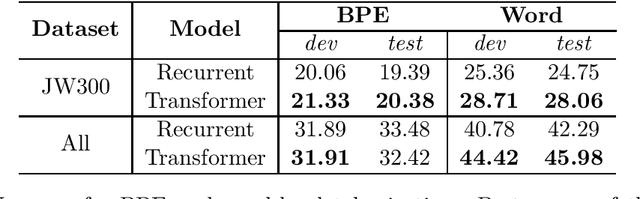

Neural Machine Translation (NMT) for low-resource languages suffers from low performance because of the lack of large amounts of parallel data and language diversity. To contribute to ameliorating this problem, we built a baseline model for English-Hausa machine translation, which is considered a task for low-resource language. The Hausa language is the second largest Afro-Asiatic language in the world after Arabic and it is the third largest language for trading across a larger swath of West Africa countries, after English and French. In this paper, we curated different datasets containing Hausa-English parallel corpus for our translation. We trained baseline models and evaluated the performance of our models using the Recurrent and Transformer encoder-decoder architecture with two tokenization approaches: standard word-level tokenization and Byte Pair Encoding (BPE) subword tokenization.