 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Evolution of Reranking Models in Information Retrieval: From Heuristic Methods to Large Language Models
Dec 18, 2025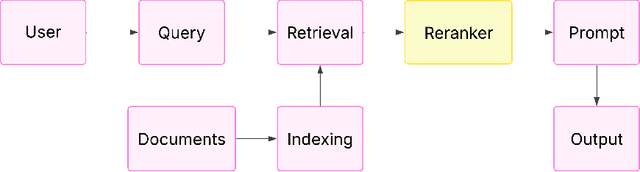
Reranking is a critical stage in contemporary information retrieval (IR) systems, improving the relevance of the user-presented final results by honing initial candidate sets. This paper is a thorough guide to examine the changing reranker landscape and offer a clear view of the advancements made in reranking methods. We present a comprehensive survey of reranking models employed in IR, particularly within modern Retrieval Augmented Generation (RAG) pipelines, where retrieved documents notably influence output quality. We embark on a chronological journey through the historical trajectory of reranking techniques, starting with foundational approaches, before exploring the wide range of sophisticated neural network architectures such as cross-encoders, sequence-generation models like T5, and Graph Neural Networks (GNNs) utilized for structural information. Recognizing the computational cost of advancing neural rerankers, we analyze techniques for enhancing efficiency, notably knowledge distillation for creating competitive, lighter alternatives. Furthermore, we map the emerging territory of integrating Large Language Models (LLMs) in reranking, examining novel prompting strategies and fine-tuning tactics. This survey seeks to elucidate the fundamental ideas, relative effectiveness, computational features, and real-world trade-offs of various reranking strategies. The survey provides a structured synthesis of the diverse reranking paradigms, highlighting their underlying principles and comparative strengths and weaknesses.
SecureNet: A Comparative Study of DeBERTa and Large Language Models for Phishing Detection
Jun 10, 2024Phishing, whether through email, SMS, or malicious websites, poses a major threat to organizations by using social engineering to trick users into revealing sensitive information. It not only compromises company's data security but also incurs significant financial losses. In this paper, we investigate whether the remarkable performance of Large Language Models (LLMs) can be leveraged for particular task like text classification, particularly detecting malicious content and compare its results with state-of-the-art Deberta V3 (DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing) model. We systematically assess the potential and limitations of both approaches using comprehensive public datasets comprising diverse data sources such as email, HTML, URL, SMS, and synthetic data generation. Additionally, we demonstrate how LLMs can generate convincing phishing emails, making it harder to spot scams and evaluate the performance of both models in this context. Our study delves further into the challenges encountered by DeBERTa V3 during its training phases, fine-tuning methodology and transfer learning processes. Similarly, we examine the challenges associated with LLMs and assess their respective performance. Among our experimental approaches, the transformer-based DeBERTa method emerged as the most effective, achieving a test dataset (HuggingFace phishing dataset) recall (sensitivity) of 95.17% closely followed by GPT-4 providing a recall of 91.04%. We performed additional experiments with other datasets on the trained DeBERTa V3 model and LLMs like GPT 4 and Gemini 1.5. Based on our findings, we provide valuable insights into the effectiveness and robustness of these advanced language models, offering a detailed comparative analysis that can inform future research efforts in strengthening cybersecurity measures for detecting and mitigating phishing threats.
Venn Diagram Prompting : Accelerating Comprehension with Scaffolding Effect
Jun 08, 2024We introduce Venn Diagram (VD) Prompting, an innovative prompting technique which allows Large Language Models (LLMs) to combine and synthesize information across complex, diverse and long-context documents in knowledge-intensive question-answering tasks. Generating answers from multiple documents involves numerous steps to extract relevant and unique information and amalgamate it into a cohesive response. To improve the quality of the final answer, multiple LLM calls or pretrained models are used to perform different tasks such as summarization, reorganization and customization. The approach covered in the paper focuses on replacing the multi-step strategy via a single LLM call using VD prompting. Our proposed technique also aims to eliminate the inherent position bias in the LLMs, enhancing consistency in answers by removing sensitivity to the sequence of input information. It overcomes the challenge of inconsistency traditionally associated with varying input sequences. We also explore the practical applications of the VD prompt based on our examination of the prompt's outcomes. In the experiments performed on four public benchmark question-answering datasets, VD prompting continually matches or surpasses the performance of a meticulously crafted instruction prompt which adheres to optimal guidelines and practices.
User Intent Recognition and Semantic Cache Optimization-Based Query Processing Framework using CFLIS and MGR-LAU
Jun 06, 2024



Query Processing (QP) is optimized by a Cloud-based cache by storing the frequently accessed data closer to users. Nevertheless, the lack of focus on user intention type in queries affected the efficiency of QP in prevailing works. Thus, by using a Contextual Fuzzy Linguistic Inference System (CFLIS), this work analyzed the informational, navigational, and transactional-based intents in queries for enhanced QP. Primarily, the user query is parsed using tokenization, normalization, stop word removal, stemming, and POS tagging and then expanded using the WordNet technique. After expanding the queries, to enhance query understanding and to facilitate more accurate analysis and retrieval in query processing, the named entity is recognized using Bidirectional Encoder UnispecNorm Representations from Transformers (BEUNRT). Next, for efficient QP and retrieval of query information from the semantic cache database, the data is structured using Epanechnikov Kernel-Ordering Points To Identify the Clustering Structure (EK-OPTICS). The features are extracted from the structured data. Now, sentence type is identified and intent keywords are extracted from the parsed query. Next, the extracted features, detected intents and structured data are inputted to the Multi-head Gated Recurrent Learnable Attention Unit (MGR-LAU), which processes the query based on a semantic cache database (stores previously interpreted queries to expedite effective future searches). Moreover, the query is processed with a minimum latency of 12856ms. Lastly, the Semantic Similarity (SS) is analyzed between the retrieved query and the inputted user query, which continues until the similarity reaches 0.9 and above. Thus, the proposed work surpassed the previous methodologies.