 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSTR
Papers and Code
Structure from Reasoning, Numbers from Search: On-Premise Open LLMs as Structural Priors for Coupled MIMO Controller Tuning
Jun 09, 2026Tuning controllers for strongly coupled multi-input multi-output (MIMO) industrial processes is hard: decentralized classical auto-tuning ignores loop interaction, and local numerical optimization from natural initializations stalls in the resulting non-convex cost landscape. We ask whether on-premise open-source large language models (LLMs), which keep data on-site and need no plant model, can help. On a single-loop CSTR, classical relay-feedback tuning (IAE 0.106, near the 0.102 optimum) beats an LLM tuner (0.162): for simple loops the LLM adds nothing. The picture inverts on a strongly coupled quadruple-tank with conflicting set-points, scored by a penalized cost J = IAE + lambda*TV(u) that rewards tracking without chattering actuators. There, naive relay tuning (J ~ 28.6) and naive LLM tuning (29.7) are no better than open loop (22.7), and a local optimizer from balanced starts fails in 10/10 runs. A scaffolded open LLM instead reasons about the coupling, proposes the counter-intuitive asymmetric structure, and reaches J ~ 16.9 +/- 0.2 from any start; refining it with a classical optimizer attains the smooth global optimum (J ~ 12.0, 10/10 vs. 0/10), which even applies a non-obvious negative integral correction decentralized tuning cannot. A global optimizer (differential evolution) also reaches this optimum, so the LLM is not the only route; its advantage is sample efficiency and interpretability: a usable controller in 18 evaluations (where the global optimizer is worse than open loop) plus a stated rationale. This edge grows with dimension, reaching ~6x fewer evaluations on a 3x3 plant. The behaviour generalizes across four open models, and on a benign plant the LLM offers no advantage, sharpening the boundary. We contribute a reproducible benchmark delimiting when open LLMs help in control tuning: not as optimizers, but as a sample-efficient, interpretable structural prior.
PL-KKT-hPINN: Enforcing Nonlinear Equality Constraints on Neural Networks via Piecewise-Linear Projection
Jun 09, 2026While physics-informed neural networks (PINNs) have shown strong potential for process modeling, physical equations are only enforced as soft constraints during training, and thus, they do not guarantee constraint satisfaction at inference. We propose a framework, called piecewise-linear Karush--Kuhn--Tucker hard-constrained PINNs (PL-KKT-hPINNs), that strictly enforces nonlinear equality constraints through piecewise-linear projection. This extends the KKT-hPINN framewor, which exactly enforces linear equalities through the Karush--Kuhn--Tucker (KKT) conditions associated with orthogonally projecting neural network outputs onto the constraint feasible region. The method is demonstrated on a continuous stirred-tank reactor (CSTR) case study for both one and two inputs. Results show that PL-KKT-hPINN preserves predictive accuracy comparable to that of a standard neural network while achieving substantially lower constraint violations. In addition, the proposed model shows improved robustness in low-data regimes, yielding lower RMSE than the unconstrained neural network for limited training sample sizes. These results demonstrate that PL-KKT-hPINN provides a computationally efficient and physically consistent framework for surrogate modeling of nonlinear chemical engineering systems.
Physics-Informed Deep Learning for Entropy Prediction in Heterogeneous Systems: Thermodynamic and Information-Theoretic Case Studies
May 31, 2026Entropy production governs irreversibility and uncertainty in both physical and information-theoretic systems. While Physics-Informed Neural Networks (PINNs) successfully solve differential equations, current architectures remain inherently domain-specific. The extraction of domain-invariant entropy representations across fundamentally different physical laws remains unexplored. This paper introduces a unified Physics-Informed Deep Learning (PIDL) framework that simultaneously enforces differential equation residuals and information-theoretic bounds within a single neural architecture. We demonstrate this framework via two canonical studies: (i) a thermodynamic continuous stirred-tank reactor (CSTR) model solving governing ODEs, where a Softplus constraint strictly enforces the Second Law of Thermodynamics; and (ii) an information-theoretic financial market model solving the inverse Fokker-Planck PDE to infer latent drift and diffusion coefficients, guaranteeing diffusion positivity via a Softplus constraint while naturally inducing Shannon entropy. Three model variants are evaluated: two domain-specific baselines and one shared-encoder architecture. The PIDL framework guarantees absolute thermodynamic admissibility with zero Second-Law violations and exhibits exceptional data efficiency, retaining >90% predictive accuracy using merely 30% of available training data. Furthermore, a post-hoc Ruppeiner Riemannian geometric analysis of the learned entropy surface successfully identifies thermodynamic phase instabilities. This methodology provides a robust, domain-agnostic architecture for physics-constrained entropy modeling, advancing applications in sustainable process design and quantitative financial risk assessment.
Reinforcement Learning-based Control via Y-wise Affine Neural Networks: Comparative Case Studies for Chemical Processes
May 20, 2026In this work we present an efficient and practically implementable approach for the application of reinforcement learning (RL)-based control in chemical process systems. This is an area that has yet to widely adopt RL-based control largely due to inherent challenges in trusting RL algorithms and the time-consuming process of training reliable agents. To address these challenges, we leverage a class of RL algorithms termed Y-wise Affine Neural Network (YANN)- RL, which we have developed in our prior work (Braniff and Tian, 2025a). By strategically initializing actor and critic networks YANN-RL algorithms provide confident and interpretable starting points within control schemes. We apply this RL-based control approach to three different process engineering case studies publicly available on the PC-Gym library (Bloor et al., 2026): (i) a continuous stirred tank reactor (CSTR), (ii) a four-tank system, and (iii) a multistage extraction column. Our approach is compared to several popular RL algorithms (PPO, SAC, DDPG, and TD3) and is benchmarked against nonlinear model predictive control (NMPC). These case studies demonstrate that YANN-RL can greatly reduce the training time and data needed, can be deployed with confidence for chemical process systems, and can approach the performance of NMPC without the knowledge of a full nonlinear model.
Neuromorphic Monocular Depth Estimation with Uncertainty Modeling
May 11, 2026Event cameras offer distinct advantages over conventional frame-based sensors, including microsecond-level temporal resolution, high dynamic range, and low bandwidth. In this paper, we predict per-pixel depth distributions from monocular event streams using deep neural networks. We estimate uncertainty using Gaussian, log-normal, and evidential learning frameworks. We compare six event representations: spatio-temporal voxel grids with 1, 5, 10, and 20 temporal bins, the Compact Spatio-Temporal Representation (CSTR), and Time-Ordered Recent Event (TORE) volumes. Our U-Net-based models are trained on synthetic data and then fine-tuned on real sequences. We evaluate performance using absolute relative error, root mean squared error, and the area under the sparsification error. Quantitative results show that the representations perform similarly, while 10 bin log-normal and 5 bin evidential learning perform best across metrics. Our experiments demonstrate that uncertainty estimation can be successfully integrated into event-based monocular depth estimation, and be used to indicate pixels with reliable depth.
A Hybrid Intelligent Framework for Uncertainty-Aware Condition Monitoring of Industrial Systems
Apr 10, 2026Hybrid approaches that combine data-driven learning with physics-based insight have shown promise for improving the reliability of industrial condition monitoring. This work develops a hybrid condition monitoring framework that integrates primary sensor measurements, lagged temporal features, and physics-informed residuals derived from nominal surrogate models. Two hybrid integration strategies are examined. The first is a feature-level fusion approach that augments the input space with residual and temporal information. The second is a model-level ensemble approach in which machine learning classifiers trained on different feature types are combined at the decision level. Both hybrid approaches of the condition monitoring framework are evaluated on a continuous stirred-tank reactor (CSTR) benchmark using several machine learning models and ensemble configurations. Both feature-level and model-level hybridization improve diagnostic accuracy relative to single-source baselines, with the best model-level ensemble achieving a 2.9\% improvement over the best baseline ensemble. To assess predictive reliability, conformal prediction is applied to quantify coverage, prediction-set size, and abstention behavior. The results show that hybrid integration enhances uncertainty management, producing smaller and well-calibrated prediction sets at matched coverage levels. These findings demonstrate that lightweight physics-informed residuals, temporal augmentation, and ensemble learning can be combined effectively to improve both accuracy and decision reliability in nonlinear industrial systems.
ScienceDB AI: An LLM-Driven Agentic Recommender System for Large-Scale Scientific Data Sharing Services
Jan 03, 2026The rapid growth of AI for Science (AI4S) has underscored the significance of scientific datasets, leading to the establishment of numerous national scientific data centers and sharing platforms. Despite this progress, efficiently promoting dataset sharing and utilization for scientific research remains challenging. Scientific datasets contain intricate domain-specific knowledge and contexts, rendering traditional collaborative filtering-based recommenders inadequate. Recent advances in Large Language Models (LLMs) offer unprecedented opportunities to build conversational agents capable of deep semantic understanding and personalized recommendations. In response, we present ScienceDB AI, a novel LLM-driven agentic recommender system developed on Science Data Bank (ScienceDB), one of the largest global scientific data-sharing platforms. ScienceDB AI leverages natural language conversations and deep reasoning to accurately recommend datasets aligned with researchers' scientific intents and evolving requirements. The system introduces several innovations: a Scientific Intention Perceptor to extract structured experimental elements from complicated queries, a Structured Memory Compressor to manage multi-turn dialogues effectively, and a Trustworthy Retrieval-Augmented Generation (Trustworthy RAG) framework. The Trustworthy RAG employs a two-stage retrieval mechanism and provides citable dataset references via Citable Scientific Task Record (CSTR) identifiers, enhancing recommendation trustworthiness and reproducibility. Through extensive offline and online experiments using over 10 million real-world datasets, ScienceDB AI has demonstrated significant effectiveness. To our knowledge, ScienceDB AI is the first LLM-driven conversational recommender tailored explicitly for large-scale scientific dataset sharing services. The platform is publicly accessible at: https://ai.scidb.cn/en.
Beyond Cropped Regions: New Benchmark and Corresponding Baseline for Chinese Scene Text Retrieval in Diverse Layouts
Jun 05, 2025



Chinese scene text retrieval is a practical task that aims to search for images containing visual instances of a Chinese query text. This task is extremely challenging because Chinese text often features complex and diverse layouts in real-world scenes. Current efforts tend to inherit the solution for English scene text retrieval, failing to achieve satisfactory performance. In this paper, we establish a Diversified Layout benchmark for Chinese Street View Text Retrieval (DL-CSVTR), which is specifically designed to evaluate retrieval performance across various text layouts, including vertical, cross-line, and partial alignments. To address the limitations in existing methods, we propose Chinese Scene Text Retrieval CLIP (CSTR-CLIP), a novel model that integrates global visual information with multi-granularity alignment training. CSTR-CLIP applies a two-stage training process to overcome previous limitations, such as the exclusion of visual features outside the text region and reliance on single-granularity alignment, thereby enabling the model to effectively handle diverse text layouts. Experiments on existing benchmark show that CSTR-CLIP outperforms the previous state-of-the-art model by 18.82% accuracy and also provides faster inference speed. Further analysis on DL-CSVTR confirms the superior performance of CSTR-CLIP in handling various text layouts. The dataset and code will be publicly available to facilitate research in Chinese scene text retrieval.
Towards Improving NAM-to-Speech Synthesis Intelligibility using Self-Supervised Speech Models
Jul 26, 2024


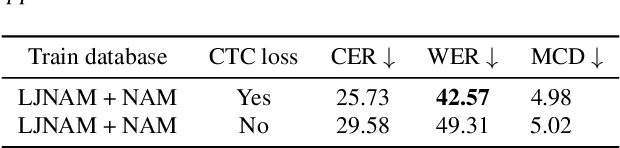
We propose a novel approach to significantly improve the intelligibility in the Non-Audible Murmur (NAM)-to-speech conversion task, leveraging self-supervision and sequence-to-sequence (Seq2Seq) learning techniques. Unlike conventional methods that explicitly record ground-truth speech, our methodology relies on self-supervision and speech-to-speech synthesis to simulate ground-truth speech. Despite utilizing simulated speech, our method surpasses the current state-of-the-art (SOTA) by 29.08% improvement in the Mel-Cepstral Distortion (MCD) metric. Additionally, we present error rates and demonstrate our model's proficiency to synthesize speech in novel voices of interest. Moreover, we present a methodology for augmenting the existing CSTR NAM TIMIT Plus corpus, setting a benchmark with a Word Error Rate (WER) of 42.57% to gauge the intelligibility of the synthesized speech. Speech samples can be found at https://nam2speech.github.io/NAM2Speech/
Physics-Informed Neural Networks with Hard Linear Equality Constraints
Feb 11, 2024Surrogate modeling is used to replace computationally expensive simulations. Neural networks have been widely applied as surrogate models that enable efficient evaluations over complex physical systems. Despite this, neural networks are data-driven models and devoid of any physics. The incorporation of physics into neural networks can improve generalization and data efficiency. The physics-informed neural network (PINN) is an approach to leverage known physical constraints present in the data, but it cannot strictly satisfy them in the predictions. This work proposes a novel physics-informed neural network, KKT-hPINN, which rigorously guarantees hard linear equality constraints through projection layers derived from KKT conditions. Numerical experiments on Aspen models of a continuous stirred-tank reactor (CSTR) unit, an extractive distillation subsystem, and a chemical plant demonstrate that this model can further enhance the prediction accuracy.