 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2FIF: Push the limit of Binarized Deep Imagery Super-resolution using End-to-end Full-precision Information Flow
Jul 14, 2022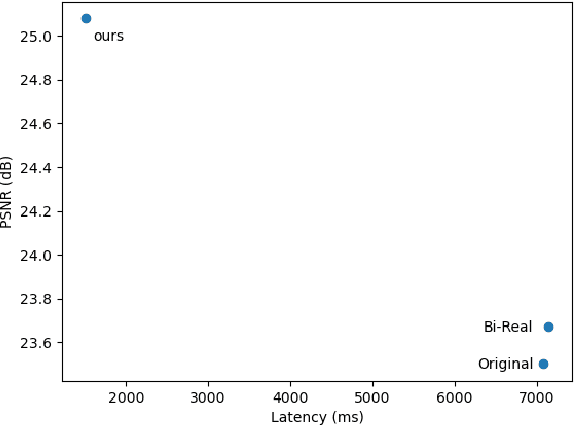
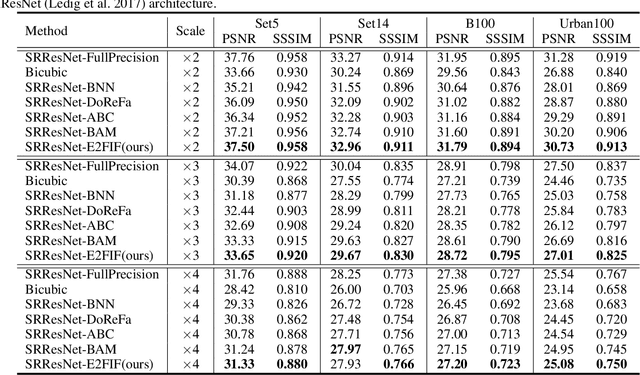
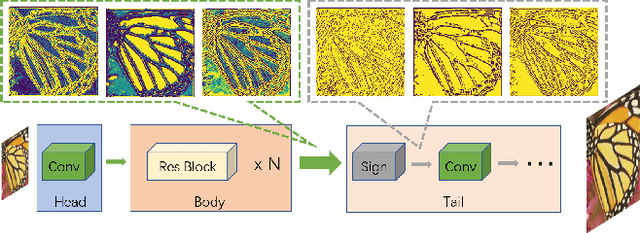
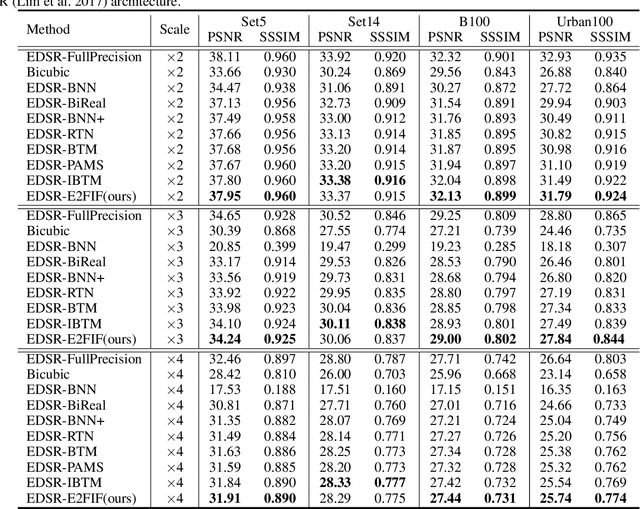
Binary neural network (BNN) provides a promising solution to deploy parameter-intensive deep single image super-resolution (SISR) models onto real devices with limited storage and computational resources. To achieve comparable performance with the full-precision counterpart, most existing BNNs for SISR mainly focus on compensating the information loss incurred by binarizing weights and activations in the network through better approximations to the binarized convolution. In this study, we revisit the difference between BNNs and their full-precision counterparts and argue that the key for good generalization performance of BNNs lies on preserving a complete full-precision information flow as well as an accurate gradient flow passing through each binarized convolution layer. Inspired by this, we propose to introduce a full-precision skip connection or its variant over each binarized convolution layer across the entire network, which can increase the forward expressive capability and the accuracy of back-propagated gradient, thus enhancing the generalization performance. More importantly, such a scheme is applicable to any existing BNN backbones for SISR without introducing any additional computation cost. To testify its efficacy, we evaluate it using four different backbones for SISR on four benchmark datasets and report obviously superior performance over existing BNNs and even some 4-bit competitors.
Unsupervised Alternating Optimization for Blind Hyperspectral Imagery Super-resolution
Dec 03, 2020
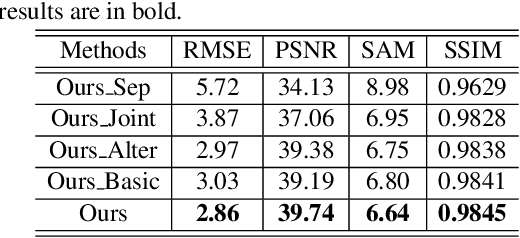
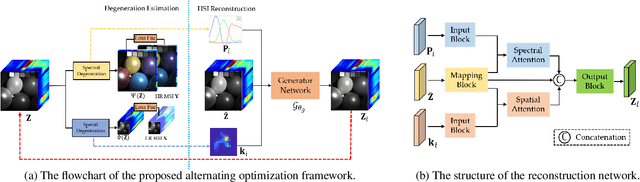
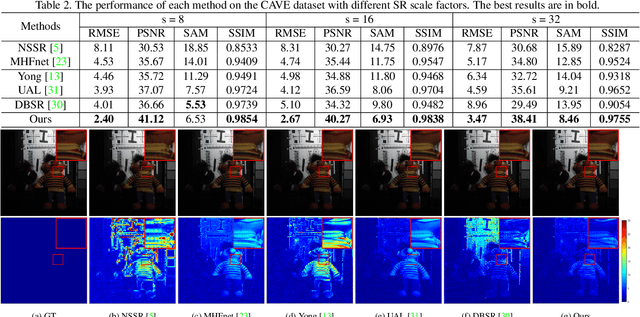
Despite the great success of deep model on Hyperspectral imagery (HSI) super-resolution(SR) for simulated data, most of them function unsatisfactory when applied to the real data, especially for unsupervised HSI SR methods. One of the main reason comes from the fact that the predefined degeneration models (e.g. blur in spatial domain) utilized by most HSI SR methods often exist great discrepancy with the real one, which results in these deep models overfit and ultimately degrade their performance on real data. To well mitigate such a problem, we explore the unsupervised blind HSI SR method. Specifically, we investigate how to effectively obtain the degeneration models in spatial and spectral domain, respectively, and makes them can well compatible with the fusion based SR reconstruction model. To this end, we first propose an alternating optimization based deep framework to estimate the degeneration models and reconstruct the latent image, with which the degeneration models estimation and HSI reconstruction can mutually promotes each other. Then, a meta-learning based mechanism is further proposed to pre-train the network, which can effectively improve the speed and generalization ability adapting to different complex degeneration. Experiments on three benchmark HSI SR datasets report an excellent superiority of the proposed method on handling blind HSI fusion problem over other competing methods.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020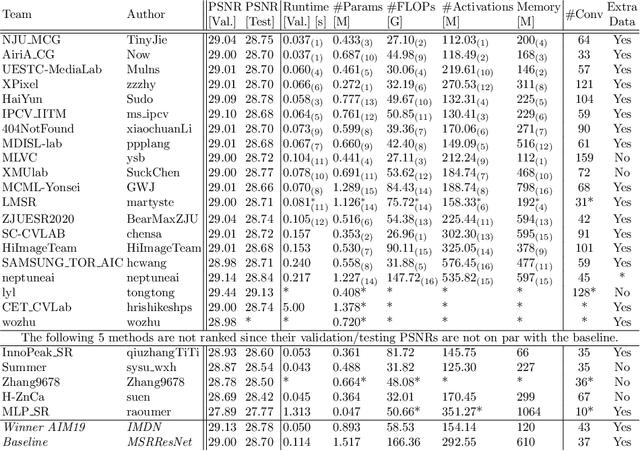
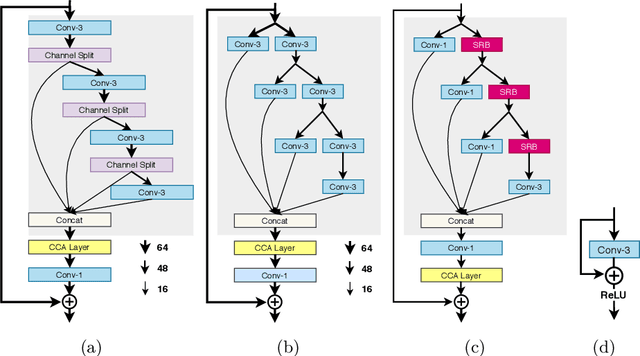
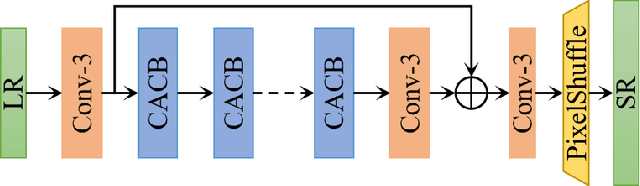
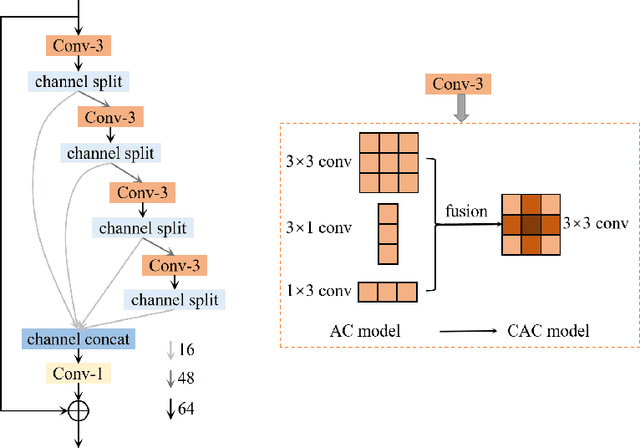
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.
AIM 2019 Challenge on Constrained Super-Resolution: Methods and Results
Nov 04, 2019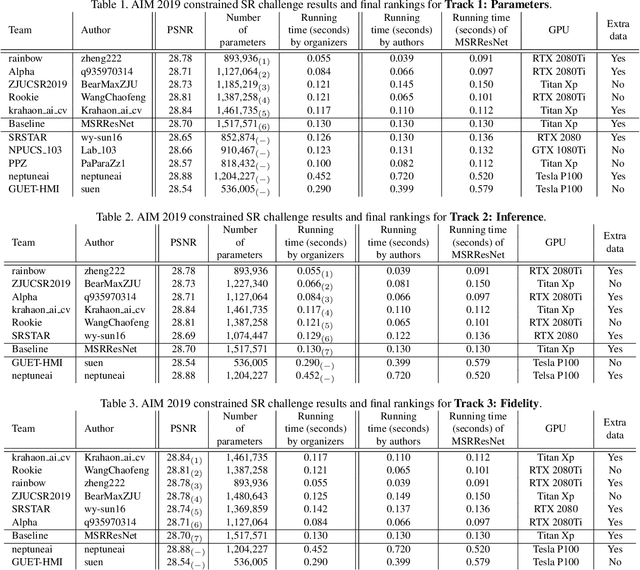
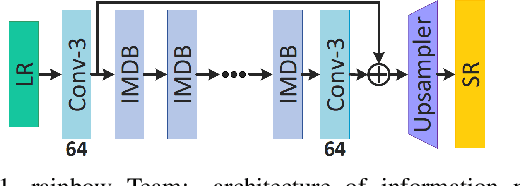
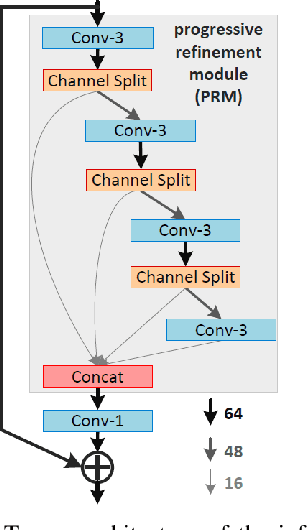
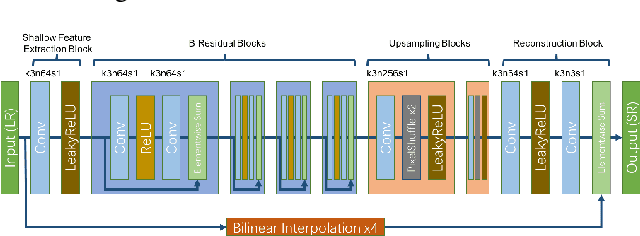
This paper reviews the AIM 2019 challenge on constrained example-based single image super-resolution with focus on proposed solutions and results. The challenge had 3 tracks. Taking the three main aspects (i.e., number of parameters, inference/running time, fidelity (PSNR)) of MSRResNet as the baseline, Track 1 aims to reduce the amount of parameters while being constrained to maintain or improve the running time and the PSNR result, Tracks 2 and 3 aim to optimize running time and PSNR result with constrain of the other two aspects, respectively. Each track had an average of 64 registered participants, and 12 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
Pixel-aware Deep Function-mixture Network for Spectral Super-Resolution
Mar 24, 2019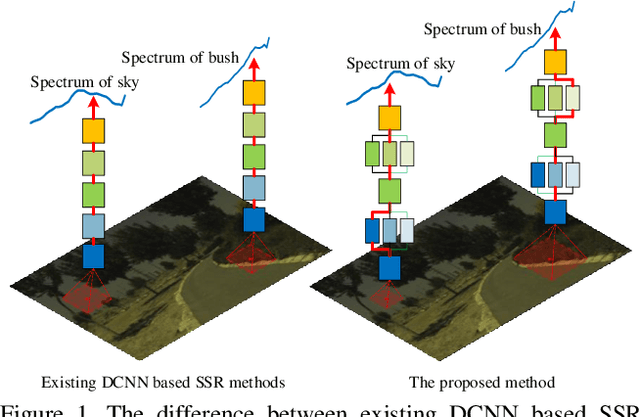
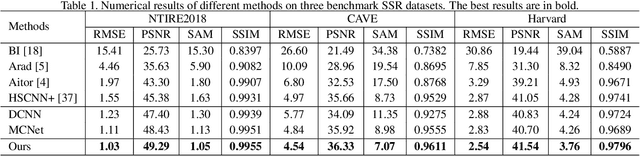
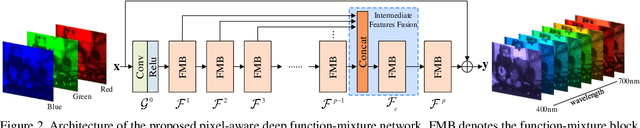
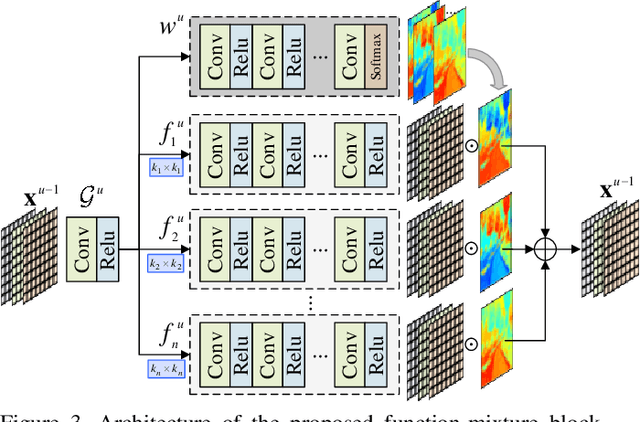
Spectral super-resolution (SSR) aims at generating a hyperspectral image (HSI) from a given RGB image. Recently, a promising direction for SSR is to learn a complicated mapping function from the RGB image to the HSI counterpart using a deep convolutional neural network. This essentially involves mapping the RGB context within a size-specific receptive field centered at each pixel to its spectrum in the HSI. The focus thereon is to appropriately determine the receptive field size and establish the mapping function from RGB context to the corresponding spectrum. Due to their differences in category or spatial position, pixels in HSIs often require different-sized receptive fields and distinct mapping functions. However, few efforts have been invested to explicitly exploit this prior. To address this problem, we propose a pixel-aware deep function-mixture network for SSR, which is composed of a new class of modules, termed function-mixture (FM) blocks. Each FM block is equipped with some basis functions, i.e., parallel subnets of different-sized receptive fields. Besides, it incorporates an extra subnet as a mixing function to generate pixel-wise weights, and then linearly mixes the outputs of all basis functions with those generated weights. This enables us to pixel-wisely determine the receptive field size and the mapping function. Moreover, we stack several such FM blocks to further increase the flexibility of the network in learning the pixel-wise mapping. To encourage feature reuse, intermediate features generated by the FM blocks are fused in late stage, which proves to be effective for boosting the SSR performance. Experimental results on three benchmark HSI datasets demonstrate the superiority of the proposed method.