 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance of Neural and Polynomial Operator Surrogates
Apr 01, 2026We consider the problem of constructing surrogate operators for parameter-to-solution maps arising from parametric partial differential equations, where repeated forward model evaluations are computationally expensive. We present a systematic empirical comparison of neural operator surrogates, including a reduced-basis neural operator trained with $L^2_μ$ and $H^1_μ$ objectives and the Fourier neural operator, against polynomial surrogate methods, specifically a reduced-basis sparse-grid surrogate and a reduced-basis tensor-train surrogate. All methods are evaluated on a linear parametric diffusion problem and a nonlinear parametric hyperelasticity problem, using input fields with algebraically decaying spectral coefficients at varying rates of decay $s$. To enable fair comparisons, we analyze ensembles of surrogate models generated by varying hyperparameters and compare the resulting Pareto frontiers of cost versus approximation accuracy, decomposing cost into contributions from data generation, setup, and evaluation. Our results show that no single method is universally superior. Polynomial surrogates achieve substantially better data efficiency for smooth input fields ($s \geq 2$), with convergence rates for the sparse-grid surrogate in agreement with theoretical predictions. For rough inputs ($s \leq 1$), the Fourier neural operator displays the fastest convergence rates. Derivative-informed training consistently improves data efficiency over standard $L^2_μ$ training, providing a competitive alternative for rough inputs in the low-data regime when Jacobian information is available at reasonable cost. These findings highlight the importance of matching the surrogate methodology to the regularity of the problem as well as accuracy demands and computational constraints of the application.
Shape Derivative-Informed Neural Operators with Application to Risk-Averse Shape Optimization
Mar 03, 2026Shape optimization under uncertainty (OUU) is computationally intensive for classical PDE-based methods due to the high cost of repeated sampling-based risk evaluation across many uncertainty realizations and varying geometries, while standard neural surrogates often fail to provide accurate and efficient sensitivities for optimization. We introduce Shape-DINO, a derivative-informed neural operator framework for learning PDE solution operators on families of varying geometries, with a particular focus on accelerating PDE-constrained shape OUU. Shape-DINOs encode geometric variability through diffeomorphic mappings to a fixed reference domain and employ a derivative-informed operator learning objective that jointly learns the PDE solution and its Fréchet derivatives with respect to design variables and uncertain parameters, enabling accurate state predictions and reliable gradients for large-scale OUU. We establish a priori error bounds linking surrogate accuracy to optimization error and prove universal approximation results for multi-input reduced basis neural operators in suitable $C^1$ norms. We demonstrate efficiency and scalability on three representative shape OUU problems, including boundary design for a Poisson equation and shape design governed by steady-state Navier-Stokes exterior flows in two and three dimensions. Across these examples, Shape-DINOs produce more reliable optimization results than operator surrogates trained without derivative information. In our examples, Shape-DINOs achieve 3-8 orders-of-magnitude speedups in state and gradient evaluations. Counting training data generation, Shape-DINOs reduce necessary PDE solves by 1-2 orders-of-magnitude compared to a strictly PDE-based approach for a single OUU problem. Moreover, Shape-DINO construction costs can be amortized across many objectives and risk measures, enabling large-scale shape OUU for complex systems.
Derivative-Informed Fourier Neural Operator: Universal Approximation and Applications to PDE-Constrained Optimization
Dec 16, 2025

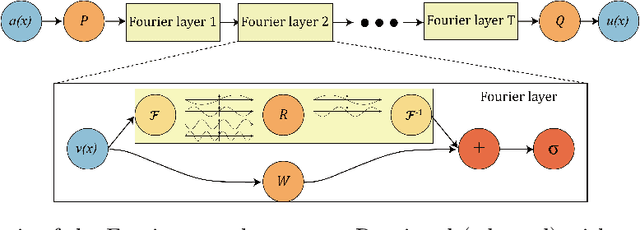
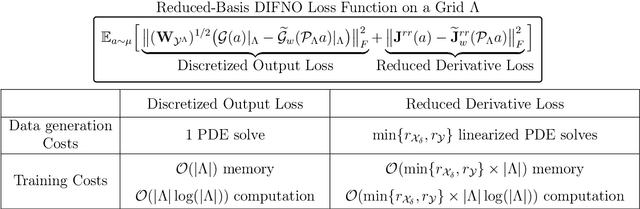
We present approximation theories and efficient training methods for derivative-informed Fourier neural operators (DIFNOs) with applications to PDE-constrained optimization. A DIFNO is an FNO trained by minimizing its prediction error jointly on output and Fréchet derivative samples of a high-fidelity operator (e.g., a parametric PDE solution operator). As a result, a DIFNO can closely emulate not only the high-fidelity operator's response but also its sensitivities. To motivate the use of DIFNOs instead of conventional FNOs as surrogate models, we show that accurate surrogate-driven PDE-constrained optimization requires accurate surrogate Fréchet derivatives. Then, for continuously differentiable operators, we establish (i) simultaneous universal approximation of FNOs and their Fréchet derivatives on compact sets, and (ii) universal approximation of FNOs in weighted Sobolev spaces with input measures that have unbounded supports. Our theoretical results certify the capability of FNOs for accurate derivative-informed operator learning and accurate solution of PDE-constrained optimization. Furthermore, we develop efficient training schemes using dimension reduction and multi-resolution techniques that significantly reduce memory and computational costs for Fréchet derivative learning. Numerical examples on nonlinear diffusion--reaction, Helmholtz, and Navier--Stokes equations demonstrate that DIFNOs are superior in sample complexity for operator learning and solving infinite-dimensional PDE-constrained inverse problems, achieving high accuracy at low training sample sizes.
Dimension reduction for derivative-informed operator learning: An analysis of approximation errors
Apr 11, 2025We study the derivative-informed learning of nonlinear operators between infinite-dimensional separable Hilbert spaces by neural networks. Such operators can arise from the solution of partial differential equations (PDEs), and are used in many simulation-based outer-loop tasks in science and engineering, such as PDE-constrained optimization, Bayesian inverse problems, and optimal experimental design. In these settings, the neural network approximations can be used as surrogate models to accelerate the solution of the outer-loop tasks. However, since outer-loop tasks in infinite dimensions often require knowledge of the underlying geometry, the approximation accuracy of the operator's derivatives can also significantly impact the performance of the surrogate model. Motivated by this, we analyze the approximation errors of neural operators in Sobolev norms over infinite-dimensional Gaussian input measures. We focus on the reduced basis neural operator (RBNO), which uses linear encoders and decoders defined on dominant input/output subspaces spanned by reduced sets of orthonormal bases. To this end, we study two methods for generating the bases; principal component analysis (PCA) and derivative-informed subspaces (DIS), which use the dominant eigenvectors of the covariance of the data or the derivatives as the reduced bases, respectively. We then derive bounds for errors arising from both the dimension reduction and the latent neural network approximation, including the sampling errors associated with the empirical estimation of the PCA/DIS. Our analysis is validated on numerical experiments with elliptic PDEs, where our results show that bases informed by the map (i.e., DIS or output PCA) yield accurate reconstructions and generalization errors for both the operator and its derivatives, while input PCA may underperform unless ranks and training sample sizes are sufficiently large.
Verification and Validation for Trustworthy Scientific Machine Learning
Feb 21, 2025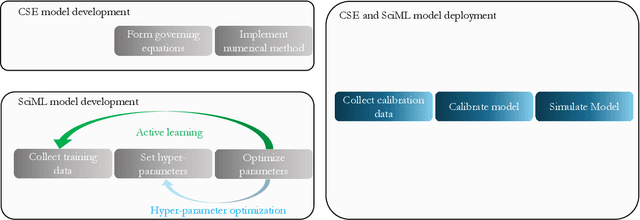
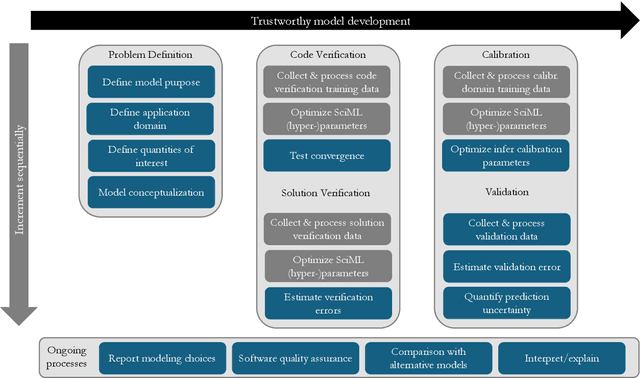
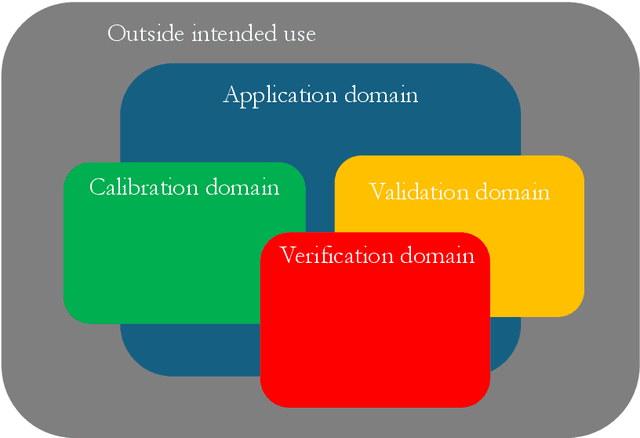
Scientific machine learning (SciML) models are transforming many scientific disciplines. However, the development of good modeling practices to increase the trustworthiness of SciML has lagged behind its application, limiting its potential impact. The goal of this paper is to start a discussion on establishing consensus-based good practices for predictive SciML. We identify key challenges in applying existing computational science and engineering guidelines, such as verification and validation protocols, and provide recommendations to address these challenges. Our discussion focuses on predictive SciML, which uses machine learning models to learn, improve, and accelerate numerical simulations of physical systems. While centered on predictive applications, our 16 recommendations aim to help researchers conduc
LazyDINO: Fast, scalable, and efficiently amortized Bayesian inversion via structure-exploiting and surrogate-driven measure transport
Nov 19, 2024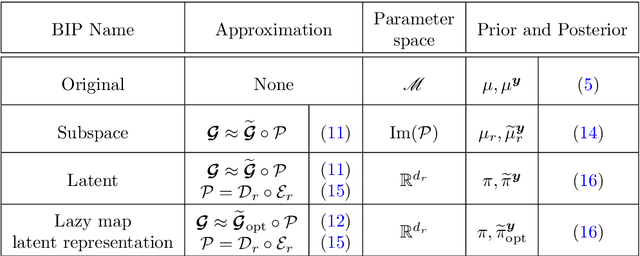
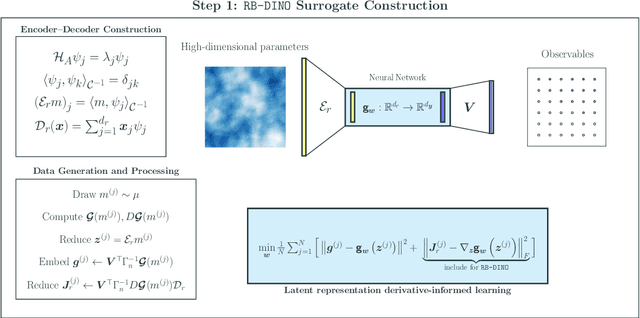
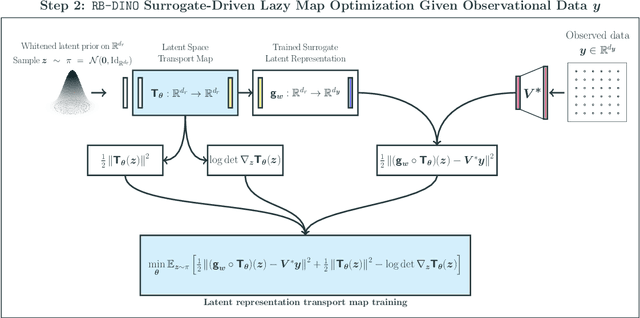
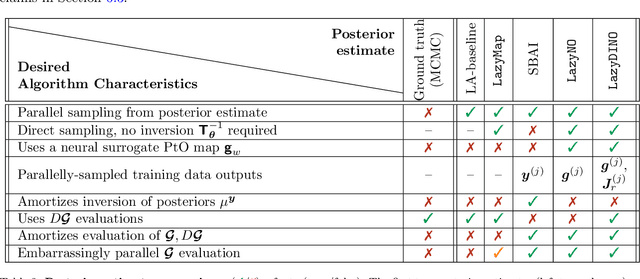
We present LazyDINO, a transport map variational inference method for fast, scalable, and efficiently amortized solutions of high-dimensional nonlinear Bayesian inverse problems with expensive parameter-to-observable (PtO) maps. Our method consists of an offline phase in which we construct a derivative-informed neural surrogate of the PtO map using joint samples of the PtO map and its Jacobian. During the online phase, when given observational data, we seek rapid posterior approximation using surrogate-driven training of a lazy map [Brennan et al., NeurIPS, (2020)], i.e., a structure-exploiting transport map with low-dimensional nonlinearity. The trained lazy map then produces approximate posterior samples or density evaluations. Our surrogate construction is optimized for amortized Bayesian inversion using lazy map variational inference. We show that (i) the derivative-based reduced basis architecture [O'Leary-Roseberry et al., Comput. Methods Appl. Mech. Eng., 388 (2022)] minimizes the upper bound on the expected error in surrogate posterior approximation, and (ii) the derivative-informed training formulation [O'Leary-Roseberry et al., J. Comput. Phys., 496 (2024)] minimizes the expected error due to surrogate-driven transport map optimization. Our numerical results demonstrate that LazyDINO is highly efficient in cost amortization for Bayesian inversion. We observe one to two orders of magnitude reduction of offline cost for accurate posterior approximation, compared to simulation-based amortized inference via conditional transport and conventional surrogate-driven transport. In particular, LazyDINO outperforms Laplace approximation consistently using fewer than 1000 offline samples, while other amortized inference methods struggle and sometimes fail at 16,000 offline samples.
Fast Unconstrained Optimization via Hessian Averaging and Adaptive Gradient Sampling Methods
Aug 14, 2024
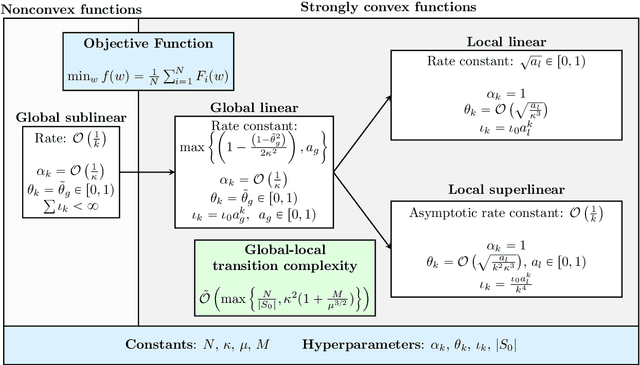


We consider minimizing finite-sum and expectation objective functions via Hessian-averaging based subsampled Newton methods. These methods allow for gradient inexactness and have fixed per-iteration Hessian approximation costs. The recent work (Na et al. 2023) demonstrated that Hessian averaging can be utilized to achieve fast $\mathcal{O}\left(\sqrt{\tfrac{\log k}{k}}\right)$ local superlinear convergence for strongly convex functions in high probability, while maintaining fixed per-iteration Hessian costs. These methods, however, require gradient exactness and strong convexity, which poses challenges for their practical implementation. To address this concern we consider Hessian-averaged methods that allow gradient inexactness via norm condition based adaptive-sampling strategies. For the finite-sum problem we utilize deterministic sampling techniques which lead to global linear and sublinear convergence rates for strongly convex and nonconvex functions respectively. In this setting we are able to derive an improved deterministic local superlinear convergence rate of $\mathcal{O}\left(\tfrac{1}{k}\right)$. For the %expected risk expectation problem we utilize stochastic sampling techniques, and derive global linear and sublinear rates for strongly convex and nonconvex functions, as well as a $\mathcal{O}\left(\tfrac{1}{\sqrt{k}}\right)$ local superlinear convergence rate, all in expectation. We present novel analysis techniques that differ from the previous probabilistic results. Additionally, we propose scalable and efficient variations of these methods via diagonal approximations and derive the novel diagonally-averaged Newton (Dan) method for large-scale problems. Our numerical results demonstrate that the Hessian averaging not only helps with convergence, but can lead to state-of-the-art performance on difficult problems such as CIFAR100 classification with ResNets.
Efficient geometric Markov chain Monte Carlo for nonlinear Bayesian inversion enabled by derivative-informed neural operators
Mar 13, 2024We propose an operator learning approach to accelerate geometric Markov chain Monte Carlo (MCMC) for solving infinite-dimensional nonlinear Bayesian inverse problems. While geometric MCMC employs high-quality proposals that adapt to posterior local geometry, it requires computing local gradient and Hessian information of the log-likelihood, incurring a high cost when the parameter-to-observable (PtO) map is defined through expensive model simulations. We consider a delayed-acceptance geometric MCMC method driven by a neural operator surrogate of the PtO map, where the proposal is designed to exploit fast surrogate approximations of the log-likelihood and, simultaneously, its gradient and Hessian. To achieve a substantial speedup, the surrogate needs to be accurate in predicting both the observable and its parametric derivative (the derivative of the observable with respect to the parameter). Training such a surrogate via conventional operator learning using input--output samples often demands a prohibitively large number of model simulations. In this work, we present an extension of derivative-informed operator learning [O'Leary-Roseberry et al., J. Comput. Phys., 496 (2024)] using input--output--derivative training samples. Such a learning method leads to derivative-informed neural operator (DINO) surrogates that accurately predict the observable and its parametric derivative at a significantly lower training cost than the conventional method. Cost and error analysis for reduced basis DINO surrogates are provided. Numerical studies on PDE-constrained Bayesian inversion demonstrate that DINO-driven MCMC generates effective posterior samples 3--9 times faster than geometric MCMC and 60--97 times faster than prior geometry-based MCMC. Furthermore, the training cost of DINO surrogates breaks even after collecting merely 10--25 effective posterior samples compared to geometric MCMC.
Efficient PDE-Constrained optimization under high-dimensional uncertainty using derivative-informed neural operators
May 31, 2023We propose a novel machine learning framework for solving optimization problems governed by large-scale partial differential equations (PDEs) with high-dimensional random parameters. Such optimization under uncertainty (OUU) problems may be computational prohibitive using classical methods, particularly when a large number of samples is needed to evaluate risk measures at every iteration of an optimization algorithm, where each sample requires the solution of an expensive-to-solve PDE. To address this challenge, we propose a new neural operator approximation of the PDE solution operator that has the combined merits of (1) accurate approximation of not only the map from the joint inputs of random parameters and optimization variables to the PDE state, but also its derivative with respect to the optimization variables, (2) efficient construction of the neural network using reduced basis architectures that are scalable to high-dimensional OUU problems, and (3) requiring only a limited number of training data to achieve high accuracy for both the PDE solution and the OUU solution. We refer to such neural operators as multi-input reduced basis derivative informed neural operators (MR-DINOs). We demonstrate the accuracy and efficiency our approach through several numerical experiments, i.e. the risk-averse control of a semilinear elliptic PDE and the steady state Navier--Stokes equations in two and three spatial dimensions, each involving random field inputs. Across the examples, MR-DINOs offer $10^{3}$--$10^{7} \times$ reductions in execution time, and are able to produce OUU solutions of comparable accuracies to those from standard PDE based solutions while being over $10 \times$ more cost-efficient after factoring in the cost of construction.
Residual-based error correction for neural operator accelerated infinite-dimensional Bayesian inverse problems
Oct 06, 2022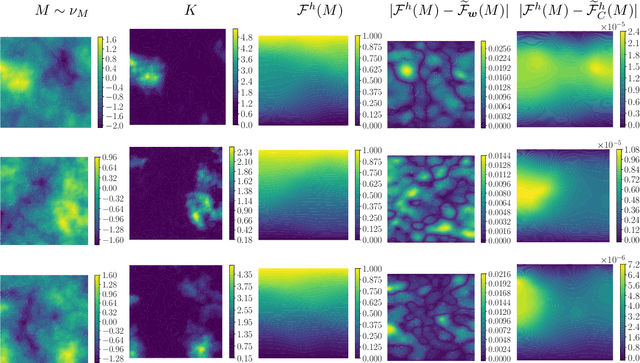
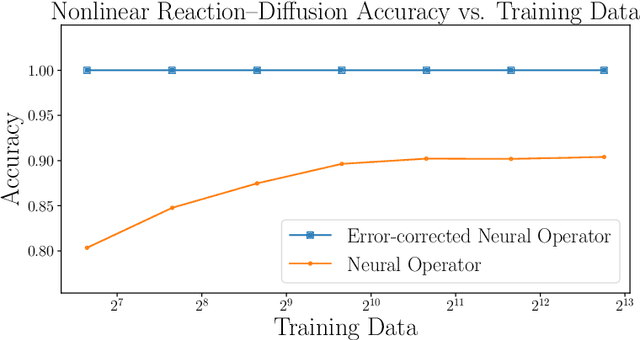

We explore using neural operators, or neural network representations of nonlinear maps between function spaces, to accelerate infinite-dimensional Bayesian inverse problems (BIPs) with models governed by nonlinear parametric partial differential equations (PDEs). Neural operators have gained significant attention in recent years for their ability to approximate the parameter-to-solution maps defined by PDEs using as training data solutions of PDEs at a limited number of parameter samples. The computational cost of BIPs can be drastically reduced if the large number of PDE solves required for posterior characterization are replaced with evaluations of trained neural operators. However, reducing error in the resulting BIP solutions via reducing the approximation error of the neural operators in training can be challenging and unreliable. We provide an a priori error bound result that implies certain BIPs can be ill-conditioned to the approximation error of neural operators, thus leading to inaccessible accuracy requirements in training. To reliably deploy neural operators in BIPs, we consider a strategy for enhancing the performance of neural operators, which is to correct the prediction of a trained neural operator by solving a linear variational problem based on the PDE residual. We show that a trained neural operator with error correction can achieve a quadratic reduction of its approximation error, all while retaining substantial computational speedups of posterior sampling when models are governed by highly nonlinear PDEs. The strategy is applied to two numerical examples of BIPs based on a nonlinear reaction--diffusion problem and deformation of hyperelastic materials. We demonstrate that posterior representations of the two BIPs produced using trained neural operators are greatly and consistently enhanced by error correction.