 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDerivative-Informed Neural Operator: An Efficient Framework for High-Dimensional Parametric Derivative Learning
Paper and Code
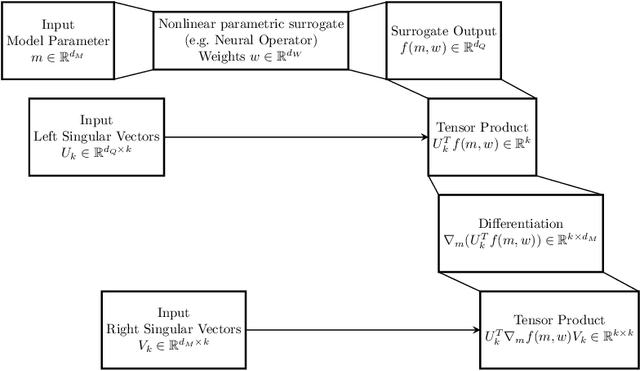
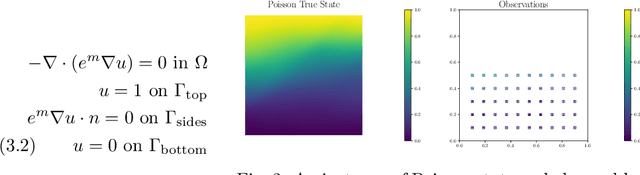
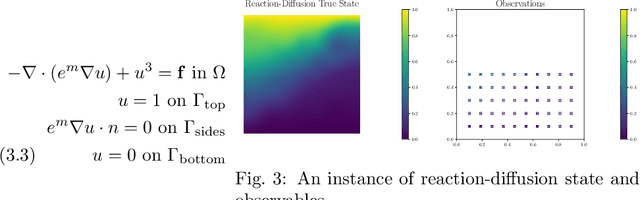
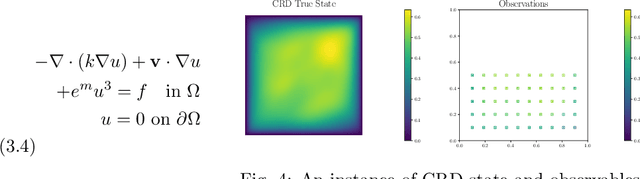
Neural operators have gained significant attention recently due to their ability to approximate high-dimensional parametric maps between function spaces. At present, only parametric function approximation has been addressed in the neural operator literature. In this work we investigate incorporating parametric derivative information in neural operator training; this information can improve function approximations, additionally it can be used to improve the approximation of the derivative with respect to the parameter, which is often the key to scalable solution of high-dimensional outer-loop problems (e.g. Bayesian inverse problems). Parametric Jacobian information is formally intractable to incorporate due to its high-dimensionality, to address this concern we propose strategies based on reduced SVD, randomized sketching and the use of reduced basis surrogates. All of these strategies only require only $O(r)$ Jacobian actions to construct sample Jacobian data, and allow us to reduce the linear algebra and memory costs associated with the Jacobian training from the product of the input and output dimensions down to $O(r^2)$, where $r$ is the dimensionality associated with the dimension reduction technique. Numerical results for parametric PDE problems demonstrate that the addition of derivative information to the training problem can significantly improve the parametric map approximation, particularly given few data. When Jacobian actions are inexpensive compared to the parametric map, this information can be economically substituted for parametric map data. Additionally we show that Jacobian error approximations improve significantly with the introduction of Jacobian training data. This result opens the door to the use of derivative-informed neural operators (DINOs) in outer-loop algorithms where they can amortize the additional training data cost via repeated evaluations.