 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDerivative-Informed Fourier Neural Operator: Universal Approximation and Applications to PDE-Constrained Optimization
Dec 16, 2025

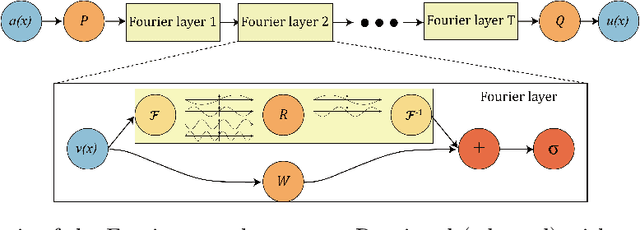
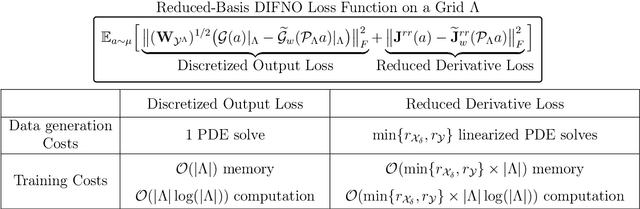
We present approximation theories and efficient training methods for derivative-informed Fourier neural operators (DIFNOs) with applications to PDE-constrained optimization. A DIFNO is an FNO trained by minimizing its prediction error jointly on output and Fréchet derivative samples of a high-fidelity operator (e.g., a parametric PDE solution operator). As a result, a DIFNO can closely emulate not only the high-fidelity operator's response but also its sensitivities. To motivate the use of DIFNOs instead of conventional FNOs as surrogate models, we show that accurate surrogate-driven PDE-constrained optimization requires accurate surrogate Fréchet derivatives. Then, for continuously differentiable operators, we establish (i) simultaneous universal approximation of FNOs and their Fréchet derivatives on compact sets, and (ii) universal approximation of FNOs in weighted Sobolev spaces with input measures that have unbounded supports. Our theoretical results certify the capability of FNOs for accurate derivative-informed operator learning and accurate solution of PDE-constrained optimization. Furthermore, we develop efficient training schemes using dimension reduction and multi-resolution techniques that significantly reduce memory and computational costs for Fréchet derivative learning. Numerical examples on nonlinear diffusion--reaction, Helmholtz, and Navier--Stokes equations demonstrate that DIFNOs are superior in sample complexity for operator learning and solving infinite-dimensional PDE-constrained inverse problems, achieving high accuracy at low training sample sizes.
Dimension reduction for derivative-informed operator learning: An analysis of approximation errors
Apr 11, 2025We study the derivative-informed learning of nonlinear operators between infinite-dimensional separable Hilbert spaces by neural networks. Such operators can arise from the solution of partial differential equations (PDEs), and are used in many simulation-based outer-loop tasks in science and engineering, such as PDE-constrained optimization, Bayesian inverse problems, and optimal experimental design. In these settings, the neural network approximations can be used as surrogate models to accelerate the solution of the outer-loop tasks. However, since outer-loop tasks in infinite dimensions often require knowledge of the underlying geometry, the approximation accuracy of the operator's derivatives can also significantly impact the performance of the surrogate model. Motivated by this, we analyze the approximation errors of neural operators in Sobolev norms over infinite-dimensional Gaussian input measures. We focus on the reduced basis neural operator (RBNO), which uses linear encoders and decoders defined on dominant input/output subspaces spanned by reduced sets of orthonormal bases. To this end, we study two methods for generating the bases; principal component analysis (PCA) and derivative-informed subspaces (DIS), which use the dominant eigenvectors of the covariance of the data or the derivatives as the reduced bases, respectively. We then derive bounds for errors arising from both the dimension reduction and the latent neural network approximation, including the sampling errors associated with the empirical estimation of the PCA/DIS. Our analysis is validated on numerical experiments with elliptic PDEs, where our results show that bases informed by the map (i.e., DIS or output PCA) yield accurate reconstructions and generalization errors for both the operator and its derivatives, while input PCA may underperform unless ranks and training sample sizes are sufficiently large.
Efficient PDE-Constrained optimization under high-dimensional uncertainty using derivative-informed neural operators
May 31, 2023We propose a novel machine learning framework for solving optimization problems governed by large-scale partial differential equations (PDEs) with high-dimensional random parameters. Such optimization under uncertainty (OUU) problems may be computational prohibitive using classical methods, particularly when a large number of samples is needed to evaluate risk measures at every iteration of an optimization algorithm, where each sample requires the solution of an expensive-to-solve PDE. To address this challenge, we propose a new neural operator approximation of the PDE solution operator that has the combined merits of (1) accurate approximation of not only the map from the joint inputs of random parameters and optimization variables to the PDE state, but also its derivative with respect to the optimization variables, (2) efficient construction of the neural network using reduced basis architectures that are scalable to high-dimensional OUU problems, and (3) requiring only a limited number of training data to achieve high accuracy for both the PDE solution and the OUU solution. We refer to such neural operators as multi-input reduced basis derivative informed neural operators (MR-DINOs). We demonstrate the accuracy and efficiency our approach through several numerical experiments, i.e. the risk-averse control of a semilinear elliptic PDE and the steady state Navier--Stokes equations in two and three spatial dimensions, each involving random field inputs. Across the examples, MR-DINOs offer $10^{3}$--$10^{7} \times$ reductions in execution time, and are able to produce OUU solutions of comparable accuracies to those from standard PDE based solutions while being over $10 \times$ more cost-efficient after factoring in the cost of construction.